Nouveau
🚀 Introduction
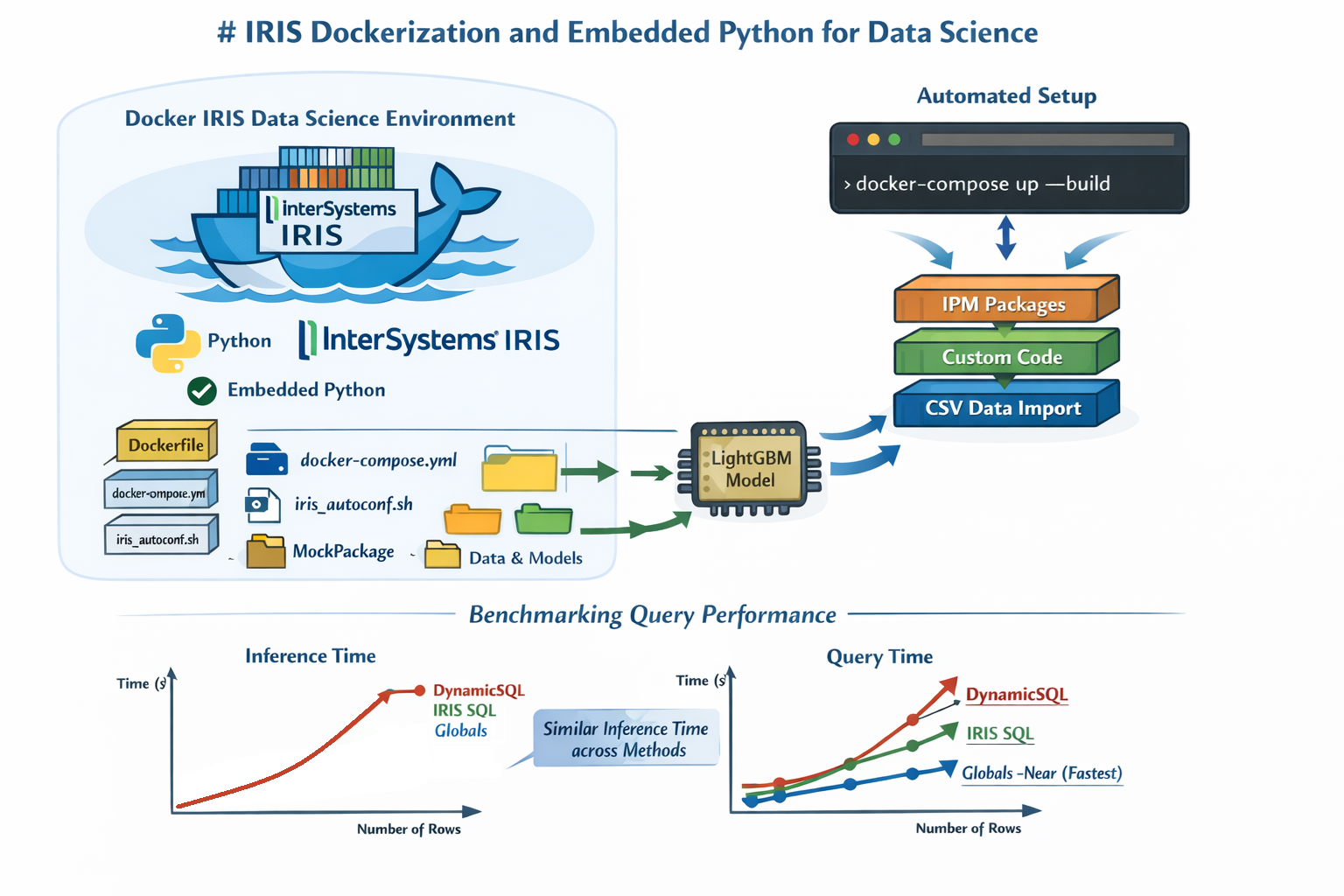
Avec l'émergence des modèles de langage de grande taille (LLM) comme Gemini, Claude et GPT, la capacité d'une intelligence artificielle à comprendre et à interagir avec des sources de données d'entreprise est devenue un enjeu majeur. Cependant, le fossé entre le langage naturel et les structures complexes des bases de données multidimensionnelles peut s'avérer difficile à combler.
Le Connecteur MCP (Model Context Protocol) pour InterSystems IRIS a été conçu pour résoudre ce problème.