Quatre API pour les bases de données
Une session concurrente dans IRIS : SQL, Objects, REST, et GraphQL

Kazimir Malevitch, "Athlètes" (1932)
"Mais bien sûr, vous ne comprenez pas ! Comment celui qui a toujours voyagé en calèche peut-il comprendre les sentiments et les impressions du voyageur en express ou du pilote dans les airs ?"
Kazimir Malevich (1916)
Introduction
Nous avons déjà abordé le sujet des raisons pour lesquelles la représentation objet/type est préférable à SQL pour la mise en œuvre des modèles de domaine. Et ces conclusions et ces faits sont aussi vrais aujourd'hui qu'ils l'ont toujours été. Alors pourquoi devrions-nous faire un pas en arrière et discuter des technologies qui ramènent les abstractions au niveau global, où elles se trouvaient à l'ère pré-objet et pré-type ? Et pourquoi devrions-nous encourager l'utilisation d'un code spaghetti, qui donne lieu à des bogues difficiles à repérer et qui ne repose que sur les compétences virtuoses des développeurs ?
Plusieurs arguments sont favorables à la transmission de données via des API basées sur SQL/REST/GraphQL plutôt qu'à leur représentation sous forme de types/objects:
- Ces technologies sont très bien étudiées et assez faciles à appliquer.
- Ils jouissent d'une incroyable popularité et ont été largement mis en œuvre dans des logiciels accessibles et à code source ouvert.
- Vous n'avez souvent pas d'autre choix que d'utiliser ces technologies, notamment sur le web et dans les bases de données.
- Plus important encore, les API utilisent toujours des objets, car ils constituent le moyen le plus approprié d'implémenter les API dans le code.
Avant de parler de la mise en œuvre des API, jetons d'abord un coup d'œil aux couches d'abstraction sous-jacentes. Le schéma ci-dessous montre comment les données se déplacent entre l'endroit où elles sont stockées de façon permanente et l'endroit où elles sont traitées et présentées à l'utilisateur de nos applications.
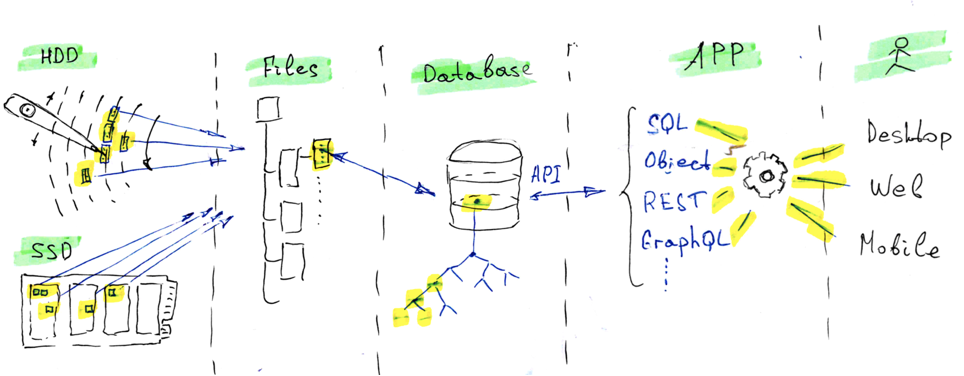
Aujourd'hui, les données sont stockées soit sur des disques durs rotatifs (HDD), soit, pour utiliser une technologie plus moderne, dans des puces de mémoire flash utilisées dans les disques SSD. Les données sont écrites et lues à l'aide d'un flux constitué de blocs de stockage distincts sur le disque dur/le disque SSD.
La division en blocs n'est pas aléatoire. Elle est plutôt déterminée par la physique, la mécanique et l'électronique du support de stockage des données. Dans un disque dur, il s'agit des pistes/secteurs d'un disque magnétique rotatif. Dans un SSD, il s'agit des segments de mémoire dans une puce de silicium réinscriptible.
Le principe est le même : il s'agit de blocs d'informations que nous devons trouver et assembler afin de récupérer les éléments de données dont nous avons besoin. Les données doivent être assemblées dans des structures qui correspondent à notre modèle/type de données avec les valeurs qui correspondent au moment de la requête. Le DBMS, associé au sous-système de fichiers du système d'exploitation, est responsable du processus d'assemblage et de récupération des données.
Nous pouvons contourner le DBMS en nous adressant directement au système de fichiers ou même au disque dur/SSD. Mais dans ce cas, nous renonçons à deux ponts super importants vers les données : entre les blocs de stockage et les flux de fichiers, et entre les fichiers et la structure ordonnée dans le modèle de base de données. En d'autres termes, nous assumons la responsabilité du développement de l'ensemble du code pour le traitement des blocs, des fichiers et des modèles, y compris toutes les optimisations, le débogage minutieux et les tests de fiabilité à long terme.
Le DBMS nous offre une excellente opportunité de traiter les données dans un langage de haut niveau, en utilisant des modèles et des représentations compréhensibles. C'est l'un des grands avantages de ces systèmes. Les DBMS et les plates-formes de données, comme InterSystems IRIS, offrent encore plus : la possibilité d'accéder simultanément à des données ordonnées de manières très diverses. Et c'est à vous de choisir lequel utiliser dans votre projet.
Profitons de la variété d'outils qu'IRIS nous offre. Rendons le code plus attrayant et plus clair. Nous utiliserons directement le langage orienté objet ObjectScript pour utiliser et développer les API. En d'autres termes, par exemple, nous appellerons le code SQL directement depuis l'intérieur du logiciel ObjectScript. Pour les autres APIs, nous utiliserons des bibliothèques prêtes à l'emploi et des outils Embedded ObjectScript.
Nous prendrons nos exemples dans le projet SQLZoo Internet, qui offre des ressources d'apprentissage pour SQL. Nous utiliserons les mêmes données dans nos autres exemples d'API.
Si vous souhaitez avoir une vue d'ensemble de la variété des approches en matière de conception d'API et profiter de solutions toutes faites, voici une collection intéressante et utile d'API publiques, qui ont été rassemblées en un seul projet sur GitHub.
SQL
Il n'y a pas de moyen plus naturel de commencer qu'avec SQL. Qui n'est pas familier avec ce langage ?
TIl existe un grand nombre de tutoriels et de livres sur SQL. Nous nous baserons sur SQLZoo. Il s'agit d'un bon cours de SQL pour débutants, avec des exemples, des instructions et une référence du langage.
Transférons certaines tâches de SQLZoo vers la plateforme IRIS et résolvons-les en utilisant diverses méthodes.
En combien de temps pouvez-vous accéder à InterSystems IRIS sur votre ordinateur ? L'une des options les plus rapides consiste à déployer un conteneur dans Docker à partir d'une image InterSystems IRIS Community Edition prête à l'emploi. InterSystems IRIS Community Edition est une version gratuite pour les développeurs de la plate-forme de données InterSystems IRIS Data Platform.
Autres moyens d'accéder à InterSystems IRIS Community Edition dans le portail de formation
Comment déplacer les données de SQLZoo vers notre propre stockage d'instance IRIS.
Pour ce faire :
- Ouvrez le Management Portal,
- Passez à la zone USER - dans Namespace %SYS, cliquez sur le lien "Switch" et sélectionnez USER
- Basculer vers Système > SQL - ouvrez System Explorer, puis SQL et cliquez sur le bouton "Go".
- Sur le côté droit l'onglet "Execute query" avec le bouton "Execute" est ouvert - c'est ce dont nous avons besoin.
Pour en savoir plus sur la façon de travailler avec SQL via le Management Portal, consultez la documentation.
Consultez les scripts prêts à l'emploi pour déployer la base de données et les données de test SQLZoo dans la description de la section Données.
Voici quelques liens directs pour la table World:
- Un script qui est utilisé pour créer la base de données
World - Les données contenues dans cette table
Le script de création de la base de données peut être exécuté dans le formulaire Query Executor du Management Portal IRIS.
CREATE TABLE world(
name VARCHAR(50) NOT NULL
,continent VARCHAR(60)
,area DECIMAL(10)
,population DECIMAL(11)
,gdp DECIMAL(14)
,capital VARCHAR(60)
,tld VARCHAR(5)
,flag VARCHAR(255)
,PRIMARY KEY (name)
)Pour charger les données de test pour le formulaire Query Executor basculez vers le menu Wizards > Data Import. Notez que le répertoire contenant le fichier de données de test doit être ajouté à l'avance, lorsque vous créez le conteneur, ou chargé depuis votre ordinateur via le navigateur. Cette option est disponible dans le panneau de contrôle de l'assistant d'importation de données.
Vérifiez si le tableau contenant les données est présent en exécutant ce script dans le formulaire Query Executor form:
SELECT * FROM world
Nous pouvons maintenant accéder aux exemples et aux tâches à partir du site Web de SQLZoo. Tous les exemples ci-dessous exigent que vous implémentiez une requête SQL dans la première attribution :
SELECT population FROM world WHERE name = 'France'

Ainsi, vous pourrez continuer à travailler de manière transparente avec l'API en transférant les tâches de SQLZoo vers la plateforme IRIS.
Attention : comme je l'ai découvert, les données de l'interface du site SQLZoo sont différentes des données exportées. Au moins dans le premier exemple, les valeurs de la population de la France et de l'Allemagne sont différentes. Ne vous en préoccupez pas. Utilisez les données d'Eurostat comme référence.
Un autre moyen pratique d'obtenir un accès SQL à la base de données dans IRIS est l'éditeur Visual Studio Code avec le plugin SQLTools et le pilote SQLTools pour InterSystems IRIS. Cette solution est populaire auprès des développeurs - essayez-la.
Afin de passer sans encombre à l'étape suivante et d'obtenir un accès objet à notre base de données, faisons un petit détour pour passer des requêtes SQL "pures" aux requêtes Embedded SQL au code de l'application en ObjectScript, qui est un langage orienté objet intégré à IRIS.
Comment configurer l'accès à IRIS et développer en ObjectScript dans VSCode.
Class User.worldquery
{
ClassMethod WhereName(name As %String)
{
&sql(
SELECT population INTO :population
FROM world
WHERE name = :name
)
IF SQLCODE<0 {WRITE "SQLCODE error ",SQLCODE," ",%msg QUIT}
ELSEIF SQLCODE=100 {WRITE "Query returns no results" QUIT}
WRITE name, " ", population
}
}Vérifions le résultat dans le terminal :
do ##class(User.worldquery).WhereName("France")Vous devriez recevoir comme réponse le nom du pays et le nombre d'habitants.
Objets/Types
Passons maintenant à l'histoire de REST/GraphQL. Nous mettons en œuvre une API pour des protocoles web. Le plus souvent, nous aurons du code source à disposition côté serveur dans un langage qui supporte bien les types, voire un paradigme entièrement orienté objet. Voici quelques-uns des langages dont nous parlons : Spring en Java/Kotlin, Django en Python, Ruby on Rails, ASP.NET en C# ou Angular en TypeScript. Et, bien entendu, des objets en ObjectScript, qui est natif de la plateforme IRIS.
Pourquoi est-ce important ? Les types et les objets de votre code seront simplifiés en structures de données lorsqu'ils seront envoyés. Vous devez tenir compte de la manière dont les modèles sont simplifiés dans le programme, ce qui revient à prendre en compte les pertes dans les modèles relationnels. Vous devez également vous assurer que, de l'autre côté de l'API, les modèles sont correctement restaurés et peuvent être utilisés sans aucune distorsion. Cela représente une charge supplémentaire : une responsabilité supplémentaire pour vous en tant que programmeur. En dehors du code et au-delà de l'aide des traducteurs, compilateurs et autres outils automatiques, vous devez vous assurer en permanence que les modèles sont correctement transférés.
Si nous examinons la question ci-dessus sous un autre angle, nous ne voyons pas encore de technologies et d'outils à l'horizon qui puissent être utilisés pour transférer facilement des types/objets d'un programme dans un langage à un programme dans un autre. Que reste-t-il ? Il existe des implémentations simplifiées de SQL/REST/GraphQL, et une multitude de documents décrivant l'API dans un langage convivial. La documentation informelle (du point de vue de l'ordinateur) destinée aux développeurs décrit exactement ce qui doit être traduit en code formel en utilisant tous les moyens disponibles, afin que l'ordinateur puisse le traiter.
Les programmeurs développent constamment différentes approches pour résoudre les problèmes mentionnés ci-dessus. L'une de ces approches réussies est le paradigme inter-langues dans le DBMS objet de la plate-forme IRIS.
Le tableau suivant devrait vous aider à comprendre la relation entre les modèles OPP et SQL dans IRIS :
| Programmation orientée objet (OOP) | Langage de requête structuré (SQL) |
| Package | Schéma |
| Classe | Tableau |
| Propriété | Colonne |
| Méthode | Procédure stockée |
| Relation entre deux classes | Contrainte de clé étrangère, jointure intégrée |
| Objet (en mémoire ou sur le disque) | Ligne (sur le disque) |
Pour en savoir plus sur l'affichage des modèles objet et relationnel, consultez la documentation d'IRIS.
Lors de l'exécution de notre requête SQL pour créer la table world de l'exemple ci-dessus, IRIS générera automatiquement les descriptions de l'objet correspondant dans la classe nommée User.world.
Class User.world Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {_SYSTEM}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = world ]
{
Property name As %Library.String(MAXLEN = 50) [ Required, SqlColumnNumber = 2 ];
Property continent As %Library.String(MAXLEN = 60) [ SqlColumnNumber = 3 ];
Property area As %Library.Numeric(MAXVAL = 9999999999, MINVAL = -9999999999, SCALE = 0) [ SqlColumnNumber = 4 ];
Property population As %Library.Numeric(MAXVAL = 99999999999, MINVAL = -99999999999, SCALE = 0) [ SqlColumnNumber = 5 ];
Property gdp As %Library.Numeric(MAXVAL = 99999999999999, MINVAL = -99999999999999, SCALE = 0) [ SqlColumnNumber = 6 ];
Property capital As %Library.String(MAXLEN = 60) [ SqlColumnNumber = 7 ];
Property tld As %Library.String(MAXLEN = 5) [ SqlColumnNumber = 8 ];
Property flag As %Library.String(MAXLEN = 255) [ SqlColumnNumber = 9 ];
Parameter USEEXTENTSET = 1;
/// Bitmap Extent Index auto-generated by DDL CREATE TABLE statement. Do not edit the SqlName of this index.
Index DDLBEIndex [ Extent, SqlName = "%%DDLBEIndex", Type = bitmap ];
/// DDL Primary Key Specification
Index WORLDPKey2 On name [ PrimaryKey, Type = index, Unique ];
}Il s'agit d'un modèle que vous pouvez utiliser pour développer votre application dans un style orienté objet. Tout ce que vous avez à faire est d'ajouter des méthodes à la classe en ObjectScript, qui dispose de bundles prêts à l'emploi pour la base de données. En fait, les méthodes de cette classe sont des "procédures stockées", pour reprendre la terminologie SQL.
Essayons d'implémenter le même exemple que nous avons réalisé précédemment en utilisant SQL. Ajoutez la méthode WhereName à la User.world classe, qui jouera le rôle de concepteur de l'objet "Informations sur le pays" pour le nom de pays saisi :
ClassMethod WhereName(name As %String) As User.world
{
Set id = 1
While ( ..%ExistsId(id) ) {
Set countryInfo = ..%OpenId(id)
if ( countryInfo.name = name ) { Return countryInfo }
Set id = id + 1
}
Return countryInfo = ""
}Vérifiez les éléments suivants dans le terminal :
set countryInfo = ##class(User.world).WhereName("France")
write countryInfo.name
write countryInfo.populationNous pouvons voir dans cet exemple que, pour trouver l'objet souhaité par le nom du pays, contrairement à une requête SQL, nous devons trier manuellement les enregistrements de la base de données un par un. Au pire, si notre objet se trouve à la fin de la liste (ou n'y figure pas du tout), nous devrons trier tous les enregistrements. Il existe une discussion séparée sur la façon dont vous pouvez accélérer le processus de recherche en indexant les champs d'objet et en générant automatiquement les méthodes de classe dans IRIS. Vous pouvez en savoir plus dans la documentation et dans les articles du portail de la communauté des développeurs.
Par exemple, pour notre classe, connaissant le nom de l'index généré par IRIS à partir du nom du pays WORLDPKey2 vous pouvez initialiser/concevoir un objet à partir de la base de données en utilisant une seule requête rapide :
set countryInfo = ##class(User.world).WORLDPKey2Open("France")Vérifiez également :
write countryInfo.name
write countryInfo.population Vous trouverez des lignes directrices pour décider si vous devez utiliser l'accès objet ou SQL pour les objets stockés dans cette documentation.
Bien entendu, vous devez toujours garder à l'esprit que vous ne pouvez utiliser pleinement qu'un seul d'entre eux pour vos tâches.
En outre, grâce à la disponibilité de paquets binaires prêts à l'emploi dans IRIS qui prennent en charge les langages de programmation orientée objet les plus courants, tels que Java, Python, C, C# (.Net), JavaScript et même Julia (voir GitHub et OpenExchange), qui gagne rapidement en popularité , vous pourrez toujours choisir les outils de développement du langage qui vous conviennent le mieux.
Plongeons maintenant dans la discussion sur les données dans l'API Web.
API Web REST, ou RESTful
Sortons des limites du serveur et du terminal familier et utilisons des interfaces plus courantes : le navigateur et les applications similaires. Ces applications s'appuient sur les protocoles hypertextes de la famille HTTP pour gérer les interactions entre les systèmes. IRIS est livré avec une série d'outils adaptés à cette fin, notamment un véritable serveur de base de données et le serveur HTTP Apache.
Le transfert d'état représentationnel (REST) est un style architectural pour la conception d'applications distribuées et, en particulier, d'applications Web. Bien que populaire, REST n'est qu'un ensemble de principes architecturaux, tandis que SOAP est un protocole standard maintenu par le World Wide Web Consortium (W3C), et les technologies basées sur SOAP sont donc soutenues par une norme.
L'ID global dans REST est une URL, et il définit chaque unité d'information successive lors de l'échange avec une base de données ou une application back-end. Voir la documentation sur le développement de services REST dans IRIS.
Dans notre exemple, l'identifiant de base sera quelque chose comme la base de l'adresse du serveur IRIS, http://localhost:52773, et le /world/ chemin /world/ vers nos données qui en est un sous-répertoire. En particulier, nous parlons de notre répertoire de pays /world/France.
Il ressemblera à ce qui suit dans un conteneur Docker :
http://localhost:52773/world/France
Si vous développez une application complète, veillez à consulter les recommandations de la documentation IRIS. L'une d'entre elles est basée sur la description de l'API REST conformément à la spécification OpenAPI 2.0.
Faisons cela de la manière la plus simple, en implémentant l'API manuellement. Dans notre exemple, nous allons créer la solution REST la plus simple qui ne nécessite que deux étapes dans IRIS :
- Créer un moniteur de chemin de classe dans l'URL, qui héritera de la classe système %CSP.REST
- Ajoutez un appel à notre classe de surveillance lors de la configuration de l'application web IRIS
Étape 1 : Surveillance de la classe
La façon dont vous pouvez implémenter une classe devrait être claire. Suivez les instructions de la documentation pour créer un REST " à la main ".
/// Description
Class User.worldrest Extends %CSP.REST
{
Parameter UseSession As Integer = 1;
Parameter CHARSET = "utf-8";
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="/:name" Method="GET" Call="countryInfo" />
</Routes>
}
}Veillez à inclure une méthode de gestion. Elle doit exécuter exactement la même fonction que les appels dans le terminal de l'exemple précédent :
ClassMethod countryInfo(name As %String) As %Status
{
set countryInfo = ##class(User.world).WhereName(name)
write "Country: ", countryInfo.name
write "<br>"
write "Population: ", countryInfo.population
return $$$OK
}Comme vous pouvez le constater, le paramètre qui commence par deux points, :name, est indiqué pour transmettre aux paramètres le nom de la méthode du gestionnaire appelé dans le moniteur à partir de la requête REST entrante.
Étape 2 : Configuration de l'application Web IRIS
Sous Administration du système > Sécurité > Applications > Applications Web,, ajoutez une nouvelle application Web avec une adresse URL d'entrée à /world /world et le gestionnaire suivant : our worldrest monitor class . Une fois qu'elle est configurée, l'application Web devrait répondre immédiatement lorsque vous basculez de http://localhost:52773/world/France. N'oubliez pas que la base de données est sensible à la casse. Il faut donc utiliser la casse correcte lors de la transmission des données de la requête au paramètre de la méthode.
Astuces :
- Utilisez les outils de débogage si nécessaire. Vous trouverez une bonne description dans cet article en deux parties (consultez également les commentaires).
- Si l'erreur "401 Unauthorized" apparaît, et que vous êtes sûr que la classe de moniteur est sur le serveur et qu'il n'y a pas d'erreurs dans le lien, essayez d'ajouter le rôle %All dans l'onglet Application Roles des paramètres de l'application Web. Il ne s'agit pas d'une méthode entièrement sécurisée, et vous devez comprendre les implications possibles de l'autorisation d'accès pour tous les rôles, mais elle est acceptable pour une installation locale.
GraphQL
Il s'agit d'un nouveau territoire dans le sens où vous ne trouverez rien dans la documentation actuelle d'IRIS sur les API utilisant GraphQL. Toutefois, cela ne doit pas nous empêcher d'utiliser ce merveilleux outil.
Cela ne fait que cinq ans que GraphQL est devenu public. Développé par la Fondation Linux, GraphQL est un langage d'interrogation pour les API. Et l'on peut sans doute affirmer qu'il s'agit de la meilleure technologie issue de l'amélioration de l'architecture REST et des différentes API web. Voici un court exposé introductif à ce sujet pour les débutants. Et, grâce aux efforts des passionnés et des ingénieurs d'InterSystems, IRIS offre un support pour GraphQL depuis 2018.
Voici l'article correspondant “Implémentation de GraphQL pour les plateformes InterSystems”. Et voici GraphQL compris, expliqué et implémenté.
L'application GraphQL se compose de deux modules : le back-end de l'application du côté d'IRIS et la partie front-end qui s'exécute dans le navigateur. En d'autres termes, vous devez la configurer conformément aux instructions relatives à l'application Web GraphQL et GraphiQL.
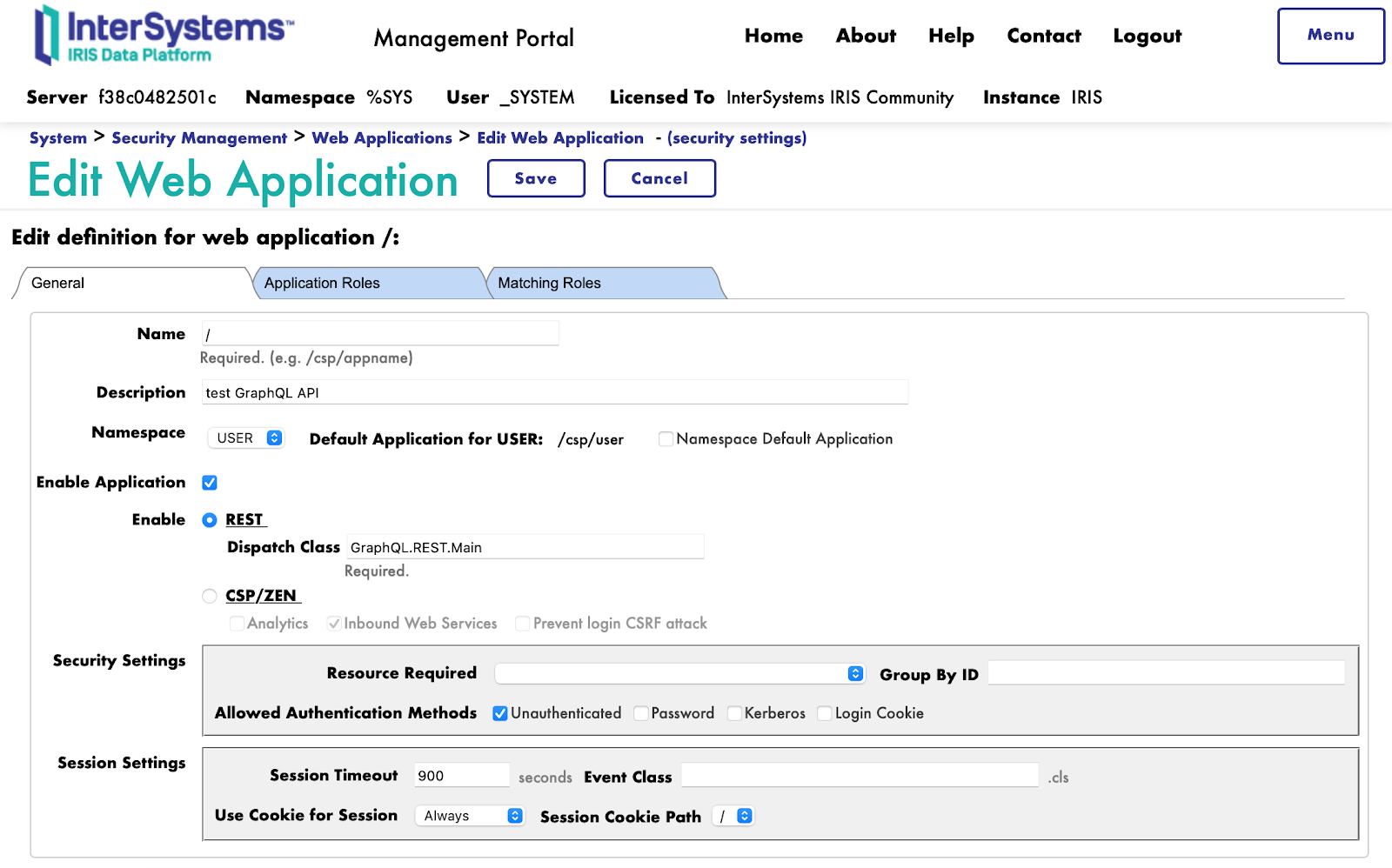
Par exemple, voici à quoi la configuration de l'application ressemble pour moi dans IRIS à l'intérieur d'un conteneur Docker. Il s'agit des paramètres d'une application Web GraphQL qui agit comme un moniteur REST et un gestionnaire de schéma de base de données : Et la seconde application GraphQL est une interface utilisateur pour le navigateur, écrite en HTML et JavaScript : Il peut être exécuté en basculant de http://localhost:52773/graphiql/index.html. Sans paramètres restrictifs supplémentaires, l'application récupère immédiatement tous les schémas de base de données qu'elle peut trouver dans la zone d'installation. Cela signifie que nos exemples vont commencer à fonctionner immédiatement. De plus, le front-end fournit un merveilleux tableau organisé d'indices à partir des objets disponibles.

Voici un exemple de requête GraphQL pour notre base de données :
{
User_world ( name: France ) {
name
population
}
} Et voici la réponse correspondante :
{
"data": {
"User_world": [
{
"name": "France",
"population": 65906000
}
]
}
}Voici à quoi cela ressemble dans le navigateur :

Résumé
| Nom de la technologie | Âge de la technologie | Exemple de requête |
| SQL | 50 ans Edgar F. Codd | SELECT population FROM world WHERE name = 'France' |
| OOP | 40 ans Alan Kay and Dan Ingalls | set countryInfo = ##class(User.world).WhereName("France") |
| REST | 20 ans Roy Thomas Fielding | http://localhost:52773/world/France |
| GraphQL | 5 ans Lee Byron | { User_world ( name: France ) { name population } } |
- Beaucoup d'énergie est investie dans des technologies telles que SQL, REST, et probablement aussi GraphQL. Elles ont également une longue histoire. Elles sont toutes compatibles les unes avec les autres, au sein de la plateforme IRIS, pour créer des programmes qui traitent les données.
- Bien que cela n'ait pas été mentionné dans cet article, IRIS prend également en charge d'autres API, qui sont basées sur XML (SOAP) et JSON, et qui sont bien implémentées.
- À moins que vous ne vous occupiez spécifiquement, par exemple, du marshaling de vos objets, n'oubliez pas que les données échangées via l'API représentent toujours une version incomplète et dépouillée d'un transfert d'objet. En tant que développeur (et non en tant que code), vous êtes responsable du transfert correct des informations relatives au type de données d'un objet .
Une question pour vous, chers lecteurs
L'objectif de cet article n'était pas seulement de comparer les API modernes, ni même de passer en revue les capacités de base d'IRIS. Il s'agissait de vous aider à voir à quel point il est facile de passer d'une API à l'autre pour accéder à une base de données, de faire vos premiers pas dans IRIS et d'obtenir rapidement des résultats de votre tâche. C'est pourquoi je serais très intéressé de savoir ce que vous en pensez :
- Ce type d'approche vous aide-t-il à être opérationnel avec le logiciel ?
- Quelles sont les étapes du processus qui rendent difficile la maîtrise des outils de travail avec l'API dans IRIS ?
- Pouvez-vous citer un obstacle que vous n'auriez pas pu prévoir ?
Si vous connaissez un utilisateur qui apprend encore à utiliser IRIS, demandez-lui de laisser un commentaire ci-dessous. La discussion qui en résultera sera utile à toutes les personnes qui y participent.