Différents modèles de données dans InterSystems IRIS
Pour parler des différentes bases de données et des différents modèles de données qui existent, on doit premièrement comprendre ce qui est une base de données et comment les utiliser.
Une base de données est une collection organisée de données stockées et accessibles par voie électronique. Elle permet de stocker et de retrouver des données structurées, semi-structurées ou des données brutes souvent en rapport avec un thème ou une activité.
Au cœur de chaque base de données se trouve au moins un modèle utilisé pour décrire ses données. Et selon le modèle sur lequel elle est basée, elle peut avoir des caractéristiques un peu différentes et stocker différents types de données.
Pour inscrire, retrouver, modifier, trier, transformer ou imprimer les informations de la base de données on utilise un logiciel qui s’appelle système de gestion de base de données (SGBD, en anglais DBMS pour Database management system).
La taille, les capacités et les performances des bases de données et de leurs SGBD respectifs ont augmenté de plusieurs ordres de grandeur. Ces augmentations de performances ont été rendues possibles par les progrès technologiques dans différents domaines, tels que les domaines des processeurs, de la mémoire informatique, du stockage informatique et des réseaux informatiques. Le développement ultérieur de la technologie des bases de données peut être divisé en quatre générations basées sur le modèle ou la structure des données : navigation, relationnel, objet et post-relationnel.
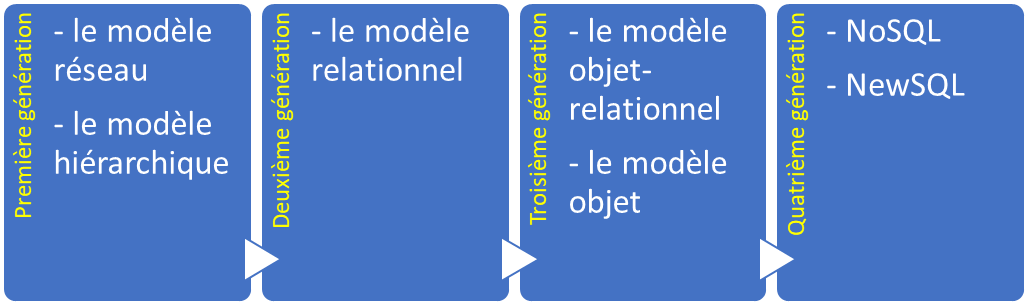

Contrairement aux trois premières générations, qui se caractérisent par un modèle de données spécifiques, la quatrième comprend de nombreuses bases de données différentes basées sur différents modèles. Ils incluent des modèles de colonnes, graphe, document, composant, multidimensionnel, clé-valeur, en mémoire etc. Toutes ces bases de données sont unies par un seul nom NoSQL (No SQL qu'on traduit maintenant par Not only SQL (pas seulement SQL)).
De plus, maintenant il apparaît une nouvelle classe, qui s’appelle NewSQL. Ce sont des bases de données relationnelles modernes qui visent à fournir les mêmes performances évolutives que les systèmes NoSQL pour les charges de travail de traitement des transactions en ligne (lecture-écriture) tout en utilisant SQL et en maintenant les garanties ACID.
D'ailleurs, parmi ces bases de données de quatrième génération, il y a celles qui supportent plusieurs modèles de données évoqués ci-dessus à la fois. Elles s’appellent multi modèles. Un bon exemple de ce type de base de données est InterSystems IRIS. C’est pourquoi je vais l’utiliser pour donner des exemples de différents types de modèles suivant leur apparition.
Les premières bases de données utilisaient les modèles hiérarchique ou réseau. Au cœur une structure arborescente où chaque enregistrement n'a qu'un seul possesseur. On peut voir comment ça marche en utilisant l’exemple d’InterSystems IRIS, parce que son modèle principal est hiérarchique et toutes les données sont stockées dans les globales (qui sont des B*-arbres). Vous pouvez lire plus sur les globales ici.
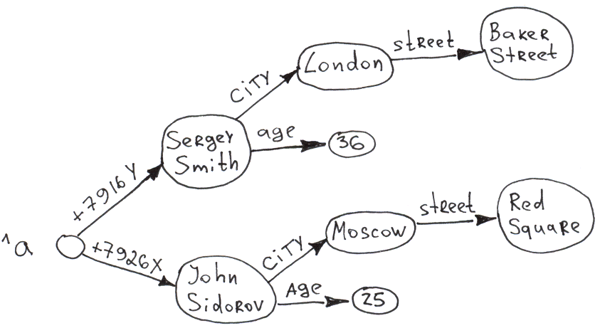
On peut créer cet arbre dans IRIS :
Set ^a("+7926X", "city") = "Moscow"
Set ^a("+7926X", "city", "street") = "Req Square"
Set ^a("+7926X", "age") = 25
Set ^a("+7916Y", "city") = "London"
Set ^a("+7916Y", "city", "street") = "Baker Street"
Set ^a("+7916Y", "age") = 36Et le voir dans la base de données :

Après que Edgar F. Codd a proposé son algèbre relationnelle en 1969 et sa théorie du stockage des données, en utilisant des principes relationnels, les bases de données relationnelles ont été créées. L’utilisation des relations (tables), des attributs (colonnes), des tuples (lignes) et, le plus important, des transactions et des exigences ACID ont rendu ces bases de données très populaires et elles le restent encore maintenant.
Par exemple on a le schéma comme ça :
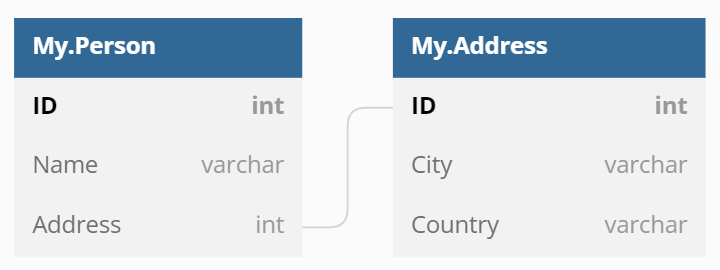
On va avoir les tables comme les suivantes :
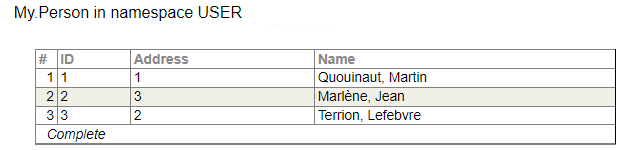
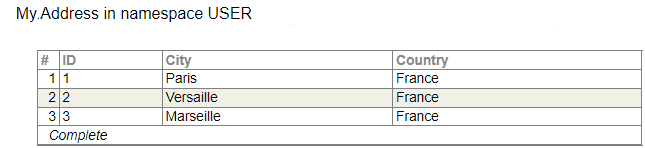
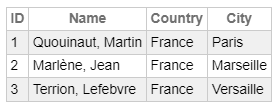
Et on peut écrire la requête :
select p.ID, p.Name, a.Country, A.City
from My.Person p left join My.Address a
on p.Address = a.IDet recevoir la réponse :
Malgré les avantages importants des bases de données relationnelles, avec la diffusion des langages objets, il est devenu nécessaire de stocker des données orientées objet dans des bases de données. C’est pourquoi, dans des années 1990 les premiers systèmes de gestion de bases de données objets et de bases de données objet-relationnel sont apparus. Ces derniers ont été créés sur la base de bases de données relationnelles en ajoutant des add-ons pour simuler le travail avec des objets. Les premiers ont été développés à partir de zéro sur la base des recommandations du consortium OMG (Object Management Group) et après ODMG (Object Data Management Group).
Les idées clés de ces bases de données objets sont les suivantes.
Le seul entrepôt de données est accessible en utilisant :
- langage de définition d'objet - définition de schéma, permet de définir des classes, leurs attributs, relations et méthodes,
- langage objet-requête - langage déclaratif presque SQL qui permet d’obtenir des objets de la base de données,
- langage de manipulation d'objets - permet de modifier et d'enregistrer des données dans la base de données, prend en charge les transactions et les appels de méthode.
Ce modèle permet d'obtenir des données à partir des bases de données en utilisant des langages orientés objet.
Si on prend la même structure comme dans un exemple précédent mais dans la forme orientée objet, on va avoir les classes suivantes :
Class My.Person Extends %Persistent
{
Property Name As %Name;
Property Address As My.Address;
}Class My.Address Extends %Persistent
{
Property Country;
Property City;
}Et on peut créer les objets en utilisant la langage orientées objet :
set address = ##class(My.Address).%New()
set address.Country = "France"
set address.City = "Marseille"
set person = ##class(My.Person).%New()
set person.Address = address
set person.Name = "Quouinaut, Martin"
do person.%Save()Malheureusement les bases de données objet n’ont pas réussi à concurrencer les bases de données relationnelles de leur position dominante, et à la suite de cela, de nombreux ORM sont apparus.
Dans tous les cas, avec la diffusion d'Internet dans des années 2000 et l'émergence de nouvelles exigences pour le stockage de données, d’autres modèles de données et SGBD ont commencé à être utilisés. Deux de ces modèles qui sont utilisés dans IRIS ce sont des modèles de type document et colonnes.
Les bases de données orientées documents sont utilisées pour gérer des données semi-structurées. Il s’agit de données ne suivant pas une structure fixe et portant la structure en elles. Chaque unité d'information dans une telle base de données est une paire simple : une clé et un document spécifique. Ce document est formaté en JSON et contient les informations. Étant donné que la base de données n’exige pas de schéma déterminé, il est également possible d’intégrer différents types de documents dans un même entrepôt.
Si on prend encore une fois l’exemple précédent, on peut avoir les documents comme les suivants :
{
"Name":"Quouinaut, Martin",
"Address":{
"Country":"France",
"City":"Paris"
}
}
{
"Name":"Merlingue, Luke",
"Address":{
"Country":"France",
"City":"Nancy"
},
"Age":26
}Ces deux documents avec un nombre différent de champs sont stockés dans la base de données IRIS sans aucun problème.
Et le dernier exemple de modèle qui va être disponible à la version 2022.2, c’est le modèle de colonnes. Dans ce cas, le SGBD stocke les tableaux de données par colonne et non par ligne.
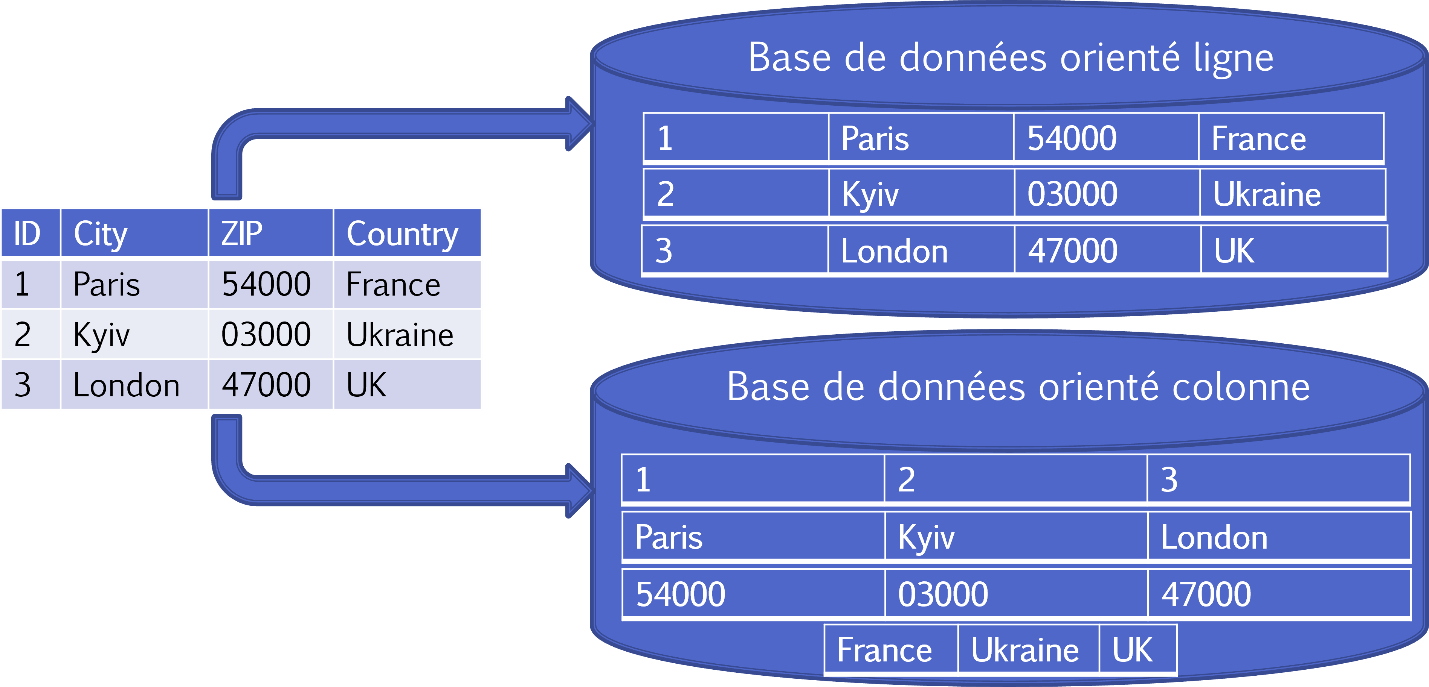
L'orientation colonne permet un accès plus efficace aux données pour interroger un sous-ensemble de colonnes (en éliminant le besoin de lire les colonnes qui ne sont pas pertinentes), et plus d'options pour la compression des données. La compression par colonne est aussi plus efficace lorsque les données de la colonne se ressemblent. De plus, on peut aussi utiliser les requêtes SQL pour recevoir les données. Cependant, elles sont généralement moins efficaces pour insérer de nouvelles données.
On peut créer cette table :
Create Table My.Address (
city varchar(50),
zip varchar(5),
country varchar(15)
) WITH STORAGETYPE = COLUMNARDans ce cas, la classe est comme ça :
Spoiler
Class My.Address Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {UnknownUser}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = Address ]
{
Property city As %Library.String(COLLATION = "EXACT", MAXLEN = 50) [ SqlColumnNumber = 2 ];
Property zip As %Library.String(COLLATION = "EXACT", MAXLEN = 5) [ SqlColumnNumber = 3 ];
Property country As %Library.String(COLLATION = "EXACT", MAXLEN = 15) [ SqlColumnNumber = 4 ];
Parameter STORAGEDEFAULT = "columnar";
Parameter USEEXTENTSET = 1;
/// Bitmap Extent Index auto-generated by DDL CREATE TABLE statement. Do not edit the SqlName of this index.
Index DDLBEIndex [ Extent, SqlName = "%%DDLBEIndex", Type = bitmap ];
Storage Default
{
<Data name="_CDM_city">
<Attribute>city</Attribute>
<ColumnarGlobal>^q3AW.DZLd.1.V1</ColumnarGlobal>
<Structure>vector</Structure>
</Data>
<Data name="_CDM_country">
<Attribute>country</Attribute>
<ColumnarGlobal>^q3AW.DZLd.1.V2</ColumnarGlobal>
<Structure>vector</Structure>
</Data>
<Data name="_CDM_zip">
<Attribute>zip</Attribute>
<ColumnarGlobal>^q3AW.DZLd.1.V3</ColumnarGlobal>
<Structure>vector</Structure>
</Data>
<DataLocation>^q3AW.DZLd.1</DataLocation>
<ExtentLocation>^q3AW.DZLd</ExtentLocation>
<ExtentSize>3</ExtentSize>
<IdFunction>sequence</IdFunction>
<IdLocation>^q3AW.DZLd.1</IdLocation>
<Index name="DDLBEIndex">
<Location>^q3AW.DZLd.2</Location>
</Index>
<Index name="IDKEY">
<Location>^q3AW.DZLd.1</Location>
</Index>
<IndexLocation>^q3AW.DZLd.I</IndexLocation>
<Property name="%%ID">
<AverageFieldSize>3</AverageFieldSize>
<Selectivity>1</Selectivity>
</Property>
<Property name="city">
<AverageFieldSize>7</AverageFieldSize>
<Selectivity>33.3333%</Selectivity>
</Property>
<Property name="country">
<AverageFieldSize>7</AverageFieldSize>
<Selectivity>33.3333%</Selectivity>
</Property>
<Property name="zip">
<AverageFieldSize>7</AverageFieldSize>
<Selectivity>33.3333%</Selectivity>
</Property>
<SQLMap name="%%DDLBEIndex">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="IDKEY">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="_CDM_city">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="_CDM_country">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="_CDM_zip">
<BlockCount>-4</BlockCount>
</SQLMap>
<StreamLocation>^q3AW.DZLd.S</StreamLocation>
<Type>%Storage.Persistent</Type>
}
}
Après on y insére les données :
insert into My.Address values ('London', '47000', 'UK')
insert into My.Address values ('Paris', '54000', 'France')
insert into My.Address values ('Kyiv', '03000', 'Ukraine')Dans les globales on voit les structures avec ces données :

Si on ouvre la globale avec les noms de villes, on verra :

Et on peut écrire une requête :
select City
from My.Addresset recevoir des données :

Dans ce cas, le SGBD lit juste une globale pour obtenir tout le résultat. Et ça permet de conserver du temps et des ressources lors de la lecture.
Ainsi, nous avons parlé de 5 modèles de données différents pris en charge par la base de données InterSystems IRIS. Ce sont le modèle hiérarchique, relationnel, objet, de document et de colonne.
Si vous avez des questions n’hésitez pas à me les poser dans les commentaires.
Comments
Super article, j'adore, il parle aussi bien à des personnes techniques que de culture générale sur les bases de données (SQL, NoSQL, stockage colonne, stockage en ligne).
Bref, un must read !
Merci!
Merci @Iryna Mykhailova pour ce brillant article !
Très clair et intelligemment présenté.
NB : pour le stockage orienté colonne indiqué au niveau de la table via l'instruction WITH STORAGETYPE = COLUMNAR , il est à noter qu'IRIS se laisse la liberté de choisir pour vous le stockage le plus communément optimal (en ligne ou en colonne), en fonction des types de données.
Exemple :
l'instruction suivante :
CREATE TABLE a.addressV1 (
city varchar(50),
zip varchar(15),
country varchar(15)
)
WITH STORAGETYPE = COLUMNAR
Ne créera aucun stockage orienté colonne, lié au risque de données trop disparates, du fait du nombre de caractères autorisés dans chaque colonne (15 ou 50) :
Class a.addressV1 Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {_SYSTEM}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = addressV1 ]
{
Property city As %Library.String(COLLATION = "EXACT", MAXLEN = 50, STORAGEDEFAULT = "ROW") [ SqlColumnNumber = 2 ];
Property zip As %Library.String(COLLATION = "EXACT", MAXLEN = 15, STORAGEDEFAULT = "ROW") [ SqlColumnNumber = 3 ];
Property country As %Library.String(COLLATION = "EXACT", MAXLEN = 15, STORAGEDEFAULT = "ROW") [ SqlColumnNumber = 4 ];
Parameter STORAGEDEFAULT = "columnar";
Parameter USEEXTENTSET = 1;
alors que l'exemple donné dans l'article, retient bien une colonne (et une seule) en stockage orienté colonne, puisqu'ayant seulement 5 caractères autorisés pour la colonne zip.
CREATE TABLE a.addressV2 (
city varchar(50),
zip varchar(5),
country varchar(15)
)
WITH STORAGETYPE = COLUMNAR
Class a.addressV2 Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {_SYSTEM}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = addressV2 ]
{
Property city As %Library.String(COLLATION = "EXACT", MAXLEN = 50, STORAGEDEFAULT = "ROW") [ SqlColumnNumber = 2 ];
Property zip As %Library.String(COLLATION = "EXACT", MAXLEN = 5) [ SqlColumnNumber = 3 ];
Property country As %Library.String(COLLATION = "EXACT", MAXLEN = 15, STORAGEDEFAULT = "ROW") [ SqlColumnNumber = 4 ];
Parameter STORAGEDEFAULT = "columnar";
Parameter USEEXTENTSET = 1;