Les modèles LLM et les applications RAG étape par étape - Partie I - Introduction
L'année dernière, vous avez probablement beaucoup entendu parler du LLM ( Large Language Model) et du développement associé des applications RAG ( Retrieval Augmented Generation). Dans cette série d'articles, nous expliquerons les bases de chaque terme utilisé et nous verrons comment développer une application RAG simple.
Qu'est-ce qu'un LLM?
Les modèles LLM font partie de ce que nous appelons l'IA générative et se basent sur la vectorisation d'énormes quantités de texte. Cette vectorisation permet d'obtenir un espace vectoriel dans lequel les mots ou termes apparentés sont plus proches les uns des autres que des mots moins apparentés.
.png)
Bien que la manière la plus simple de le visualiser soit un graphique à trois dimensions comme celui de l'image précédente, le nombre de dimensions peut être aussi grand que souhaité, plus les dimensions sont grandes, plus la précision des relations entre les termes et les mots est forte et plus la consommation de ressources est importante.
Ces modèles sont entraînés avec des ensembles de données massives qui leur permettent d'avoir suffisamment d'informations pour pouvoir générer des textes liés à la demande qui est faite, mais... Comment le modèle sait-il quels termes sont en rapport avec la question posée ? Très simplement, par ce que l'on appelle la "similarité" entre les vecteurs, qui n'est rien d'autre qu'un calcul mathématique permettant d'élucider la distance entre deux vecteurs. Les calculs les plus courants sont les suivants:
Par ce calcul, le LLM sera capable d'assembler une réponse cohérente basée sur des termes proches de la question posée en relation avec son contexte.
C'est bien beau, mais les LLM sont limités dans leur application à des usages spécifiques car les informations avec lesquelles ils sont formés sont souvent assez "générales". Si nous voulons qu'un modèle LLM soit adapté aux besoins spécifiques de notre entreprise, deux options s'offrent à nous:
Technique Fine tuning
Le Fine tuning est une technique qui permet de ré-entraîner les modèles LLM avec des données relatives à un sujet spécifique (langage procédural, terminologie médicale, etc.). Grâce à cette technique, il est possible d'avoir des modèles mieux adaptés à nos besoins sans avoir à entraîner un modèle à partir de zéro.
Le principal inconvénient de cette technique est qu'il faut toujours fournir au LLM une grande quantité d'informations pour ce recyclage, ce qui peut parfois ne pas répondre aux attentes d'une entreprise donnée.
Génération de récupération augmentée (Retrieval Augmented Generation)
RAG est une technique qui permet au LLM d'inclure le contexte nécessaire pour répondre à une question donnée sans qu'il soit nécessaire d'entraîner ou de réentraîner spécifiquement le modèle avec les informations pertinentes.
Comment inclure le contexte nécessaire à notre LLM ? Très simplement, lorsque nous envoyons la question au modèle, nous lui demandons explicitement de prendre en considération les informations pertinentes attachées à la réponse à la requête, et pour ce faire, nous utilisons des bases de données vectorielles à partir desquelles nous pouvons extraire le contexte lié à la question envoyée.
Quelle est la meilleure option pour mon problème, Fine tuning ou RAG?
Les deux options ont leurs avantages et leurs inconvénients. D'une part, le Fine tuning vous permet d'inclure toutes les informations relatives au problème que vous souhaitez résoudre dans le modèle LLM, sans avoir besoin de technologies tierces telles qu'une base de données vectorielle pour stocker les contextes, mais d'autre part, cela vous lie au modèle recyclé, et si celui-ci ne répond pas à vos attentes, la migration vers un nouveau modèle peut s'avérer assez fastidieuse.
D'autre part, RAG a besoin de fonctionnalités telles que les recherches vectorielles afin de savoir quel est le contexte le plus précis pour la question que nous transmettons à notre LLM. Ce contexte doit être stocké dans une base de données vectorielle et ensuite recherché pour extraire cette information. Le principal avantage (à part le fait de dire explicitement au LLM d'utiliser le contexte que nous lui fournissons) est que nous ne sommes pas attachés au modèle LLM, et que nous pouvons le changer pour un autre qui est plus adapté à nos besoins.
Comme nous l'avons indiqué au début de l'article, nous nous concentrerons sur le développement d'un exemple d'application dans RAG (sans grandes prétentions, juste pour montrer comment vous pouvez commencer).
Architecture d'un projet RAG
Examinons brièvement l'architecture requise pour un projet RAG:
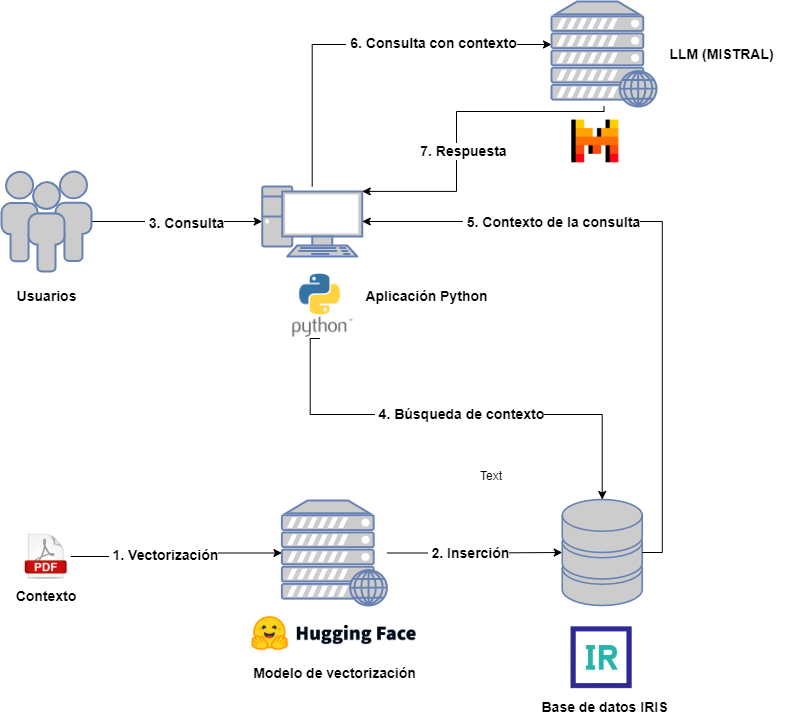
D'une part, nous aurons les acteurs suivants:
- Utilisateurs : qui interagissent avec le LLM en envoyant des requêtes.
- Contexte : préalablement fourni pour être inclus dans les requêtes des utilisateurs.
- Modèle de vectorisation : pour vectoriser les différents documents associés au contexte.
- Base de données vectorielle : dans ce cas, il s'agira d'IRIS, qui stockera les différentes parties vectorisées des documents contextuels.
- LLM : modèle LLM qui recevra les requêtes, pour cet exemple nous avons choisi MISTRAL.
- Application Python : destinée à interroger la base de données vectorielle pour l'extraction du contexte et son inclusion dans la requête LLM.
Pour ne pas alourdir le schéma, j'ai laissé de côté l'application responsable de la capture des documents de contexte, de leur découpage, puis de leur vectorisation et de leur insertion. Dans l'application associée, vous pouvez consulter cette étape ainsi que l'étape suivante relative à la requête d'extraction, mais ne vous inquiétez pas, nous la verrons plus en détail dans les prochains articles.
En association avec cet article vous avez le projet qui nous servira de référence pour expliquer en détail chaque étape, ce projet est contenu dans Docker et vous pouvez y trouver une application Python utilisant Jupyter Notebook et une instance d'IRIS. Vous aurez besoin d'un compte in MISTRAL AI pour inclure la clé API qui vous permet de lancer des requêtes.
.png)
Dans le prochain article, nous verrons comment enregistrer notre contexte dans une base de données vectorielle. Restez connectés!
Comments
Merci @Guillaume Rongier !