Les modèles LLM et les applications RAG étape par étape - Partie III - Recherche et injection de contexte
Bienvenue au troisième et dernier de nos articles consacrés au développement d'applications RAG basées sur des modèles LLM. Dans ce dernier article, nous examinerons comment, dans le cadre de notre petit projet d'exemple, on peut trouver le contexte le plus approprié pour la question que l'on veut envoyer à notre modèle LLM et, pour ce faire, nous utiliserons la fonctionnalité de recherche vectorielle incluse dans IRIS.

Recherches vectorielles
Un élément clé de toute application RAG est le mécanisme de recherche vectorielle, qui permet de rechercher dans une table comportant des enregistrements de ce type les enregistrements les plus similaires au vecteur de référence. Pour ce faire, il est nécessaire de générer d'abord l'intégration de la question à transmettre au LLM. Jetons un coup d'œil à notre projet d'exemple pour voir comment nous générons cette intégration et l'utilisons pour lancer la requête dans notre base de données IRIS:
model = sentence_transformers.SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
question = model.encode("¿Qué medicamento puede tomar mi hijo de 2 años para bajar la fiebre?", normalize_embeddings=True)
array = np.array(question)
formatted_array = np.vectorize('{:.12f}'.format)(array)
parameterQuery = []
parameterQuery.append(str(','.join(formatted_array)))
cursorIRIS.execute("SELECT distinct(Document) FROM (SELECT VECTOR_DOT_PRODUCT(VectorizedPhrase, TO_VECTOR(?, DECIMAL)) AS similarity, Document FROM LLMRAG.DOCUMENTCHUNK) WHERE similarity > 0.6", parameterQuery)
similarityRows = cursorIRIS.fetchall()Comme vous pouvez le voir, nous instancions le modèle générateur d'embeddings et vectorisons la question que nous allons soumettre à notre LLM. Ensuite, nous lançons une requête dans notre table de données LLMRAG.DOCUMENTCHUNK pour rechercher les vecteurs dont la similarité est supérieure à 0,6 (cette valeur est totalement basée sur les critères du développeur du produit).
Comme vous pouvez le constater, la commande utilisée pour la recherche est VECTOR_DOT_PRODUCT, mais ce n'est pas la seule option, examinons les deux options dont nous disposons pour les recherches de similarité.
Produit scalaire (VECTOR_DOT_PRODUCT)
Cette opération algébrique est simplement la somme des produits de chaque paire d'éléments occupant la même position dans leurs vecteurs respectifs, représentés comme suit:
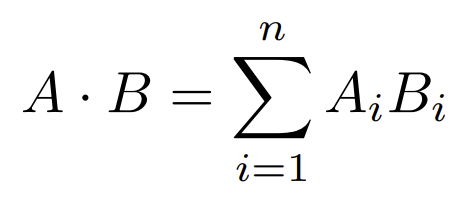
InterSystems recommande l'utilisation de cette méthode lorsque les vecteurs à travailler sont unitaires, c'est-à-dire que leur module est égal à 1. Pour ceux d'entre vous qui ne sont pas familiers avec l'algèbre, le module se calcule de la manière suivante:

Similarité cosinus (Cosine similarity)
Ce calcul représente le produit scalaire des vecteurs divisé par le produit de la longueur des vecteurs et sa formule est la suivante:
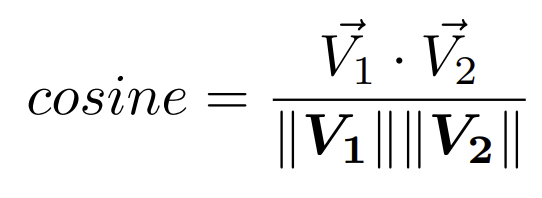
Dans les deux cas, la similarité entre les vecteurs est d'autant plus grande que le résultat est proche de 1
Injection du contexte
Avec la requête précédente, nous obtiendrons les textes liés à la question que nous enverrons au LLM. Dans notre cas, nous n'allons pas transmettre le texte que nous avons vectorisé car nous trouvons qu'il est plus intéressant d'envoyer le document complet avec la notice du médicament car le modèle LLM sera capable d'assembler une réponse beaucoup plus complète avec le document complet. Jetons un coup d'œil à notre code pour voir comment nous procédons:
for similarityRow in similarityRows:
for doc in docs_before_split:
if similarityRow[0] == doc.metadata['source'].upper():
context = context +"".join(doc.page_content)
prompt = hub.pull("rlm/rag-prompt")
rag_chain = (
{"context": lambda x: context, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("¿Qué medicamento puede tomar mi hijo de 2 años para bajar la fiebre?")
Empezamos con un bucle for que nos recorrerá todos los registros vectorizados que son similares a la pregunta realizada. Como en nuestro ejemplo
Nous commençons par une boucle for qui passe en revue tous les enregistrements vectorisés similaires à la question posée. Comme, dans notre exemple, les documents ont été stockés en mémoire lors de l'étape précédente de découpage et de vectorisation, nous les avons réutilisés dans la deuxième boucle pour extraire directement le texte, le mieux étant d'accéder au document que nous avons stocké dans notre système sans devoir utiliser cette deuxième boucle for.
Une fois que nous avons stocké le texte des documents qui formeront le contexte de la question dans une variable, l'étape suivante sera d'informer le LLM du contexte de la question que nous allons lui transmettre. Une fois le contexte transmis, il ne nous reste plus qu'à envoyer notre question au modèle. Dans ce cas, nous voulons savoir quels médicaments nous pouvons donner à notre fils de 2 ans pour réduire sa fièvre, voyons les réponses sans contexte et avec contexte:
Sans contexte:
La fièvre chez les jeunes enfants peut être une source d'inquiétude, mais il est important de la gérer correctement. Pour un enfant de 2 ans, les médicaments les plus couramment recommandés pour faire baisser la fièvre sont le paracétamol (acétaminophène) et l'ibuprofène.
Avec contexte:
Dalsy 40 mg/ml suspension buvable, contenant de l'ibuprofène, peut être utilisé pour soulager la fièvre chez les enfants à partir de l'âge de 3 mois. La dose recommandée pour les enfants à partir de 2 ans dépend de leur poids et doit être administrée sur ordonnance. Par exemple, pour un enfant de 10 kg, la dose recommandée est de 1,8 à 2,4 ml par prise, avec une dose journalière maximale de 7,2 ml (288 mg). Consultez toujours un médecin avant d'administrer un médicament à un enfant.
Comme vous pouvez le constater, sans contexte, la réponse est assez générique, alors qu'avec un contexte adéquat, la réponse est beaucoup plus directe et indique que le médicament doit toujours être prescrit par un médecin
Conclusions
Dans cette série d'articles, nous avons présenté les bases du développement d'applications RAG, comme vous pouvez le voir, les concepts de base sont assez simples, mais vous savez que le diable est toujours dans les détails, pour tout projet il est nécessaire de prendre les décisions suivantes:
- Quel modèle LLM faut-il utiliser? Un service local ou un service en ligne?
- Quel modèle d'intégration faut-il utiliser? Fonctionne-t-il correctement pour la langue que nous allons utiliser? Devons-nous lemmatiser les textes que nous allons vectoriser?
- Comment allons-nous découper nos documents en fonction du contexte? Par paragraphe? Par longueur de texte? Avec des chevauchements?
- Notre contexte est-il uniquement basé sur des documents non structurés ou disposons-nous de différentes sources de données?
- Devons-nous reclasser les résultats de la recherche vectorielle par laquelle nous avons extrait le contexte ? Et si la réponse est oui, quel modèle devons-nous appliquer?
- ...
Le développement d'applications RAG implique un effort plus important dans la validation des résultats que dans le développement technique de l'application elle-même. Vous devez être vraiment sûr que votre application ne fournit pas de réponses erronées ou inexactes, car cela pourrait avoir de graves conséquences, non seulement sur le plan juridique, mais aussi sur le plan de la confiance.