 Par mise à jour
Par mise à jourAujourd'hui, il y a beaucoup de bruit autour du LLM, de l'IA, etc. Les bases de données vectorielles en font partie, et il existe déjà de nombreuses réalisations différentes pour le support en dehors d'IRIS.
Pourquoi Vector?
- Recherche de similarité : Les vecteurs assurent une recherche de similarité efficace, par exemple en trouvant les éléments ou les documents les plus similaires dans un ensemble de données. Les bases de données relationnelles classiques sont conçues pour des recherches de correspondances exactes, qui ne sont pas adaptées à des tâches telles que la recherche de similitudes d'images ou de textes.
- Flexibilité : Les représentations vectorielles sont polyvalentes et peuvent être obtenues à partir de différents types de données, tels que du texte (via des embeddings comme Word2Vec, BERT), des images (via des modèles d'apprentissage profond), et autres.
-
- Recherches multimodales** : Les vecteurs permettent d'effectuer des recherches dans différentes modalités de données. Par exemple, avec une représentation vectorielle d'une image, on peut rechercher des images similaires ou des textes connexes dans une base de données multimodale.
Et pour bien d'autres raisons encore.
Donc, pour ce concours python, j'ai décidé de mettre en place ce support. Et malheureusement, je n'ai pas réussi à le terminer à temps, je vais vous expliquer pourquoi.

 Open Exchange app
Open Exchange app.png)
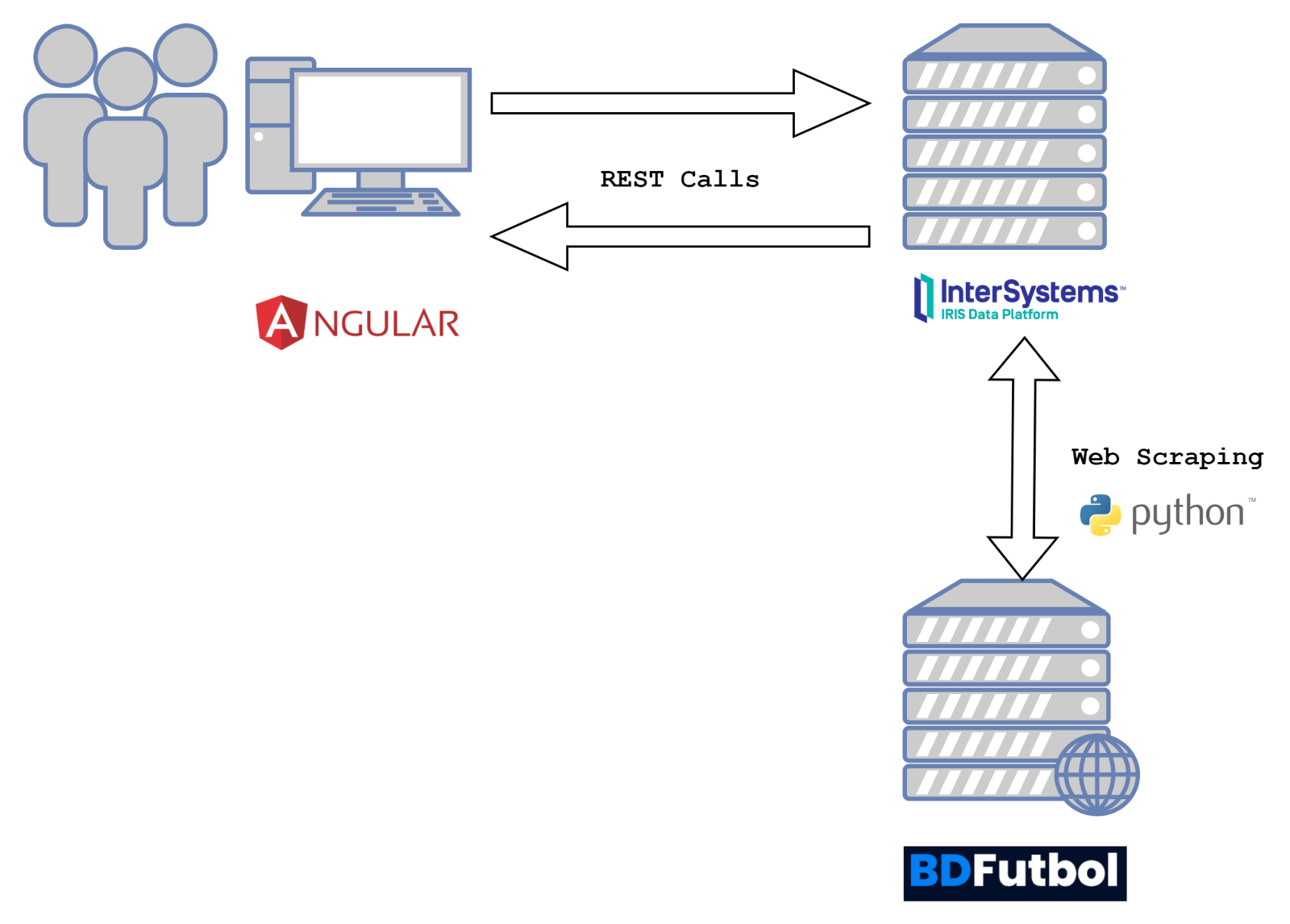
.png)
.png)
.png)





.png)
.png)