Déduplication (DeDupe) d'un serveur InterSystems® FHIR® avec le constructeur FHIR SQL Builder
Cette publication soutient la démonstration au Global Summit 2023 "Demos and Drinks" avec des détails très probablement perdus dans le bruit de l'événement. Il s'agit d'une démonstration sur la façon dont on peut utiliser les capacités FHIR SQL d'InterSystems du Serveur FHIR avec la solution Super Awesome Identity and Resolution, Zingg.ai pour détecter les enregistrements en double dans votre référentiel FHIR, et l'idée de base derrière la remédiation de ces ressources avec le PID^TOO|| en cours de construction actuellement inscrit dans le programme Incubateur d'InterSystems. Si vous êtes dans le mouvement "Compostable CDP" et si vous voulez maîtriser votre référentiel FHIR en place, vous êtes peut-être au bon endroit. Demo FHIR SQL Builder Il s'agit d'un processus simple en 3 étapes pour FHIR SQL. Configurer une analyse Configurer une transformation Configurer une projection Zingg.ai La documentation de Zingg est exhaustive et bien qu'extensible et évolutive au-delà de cette simple démo, voici les principes de base. Rechercher le lien "Label Train Match Link"
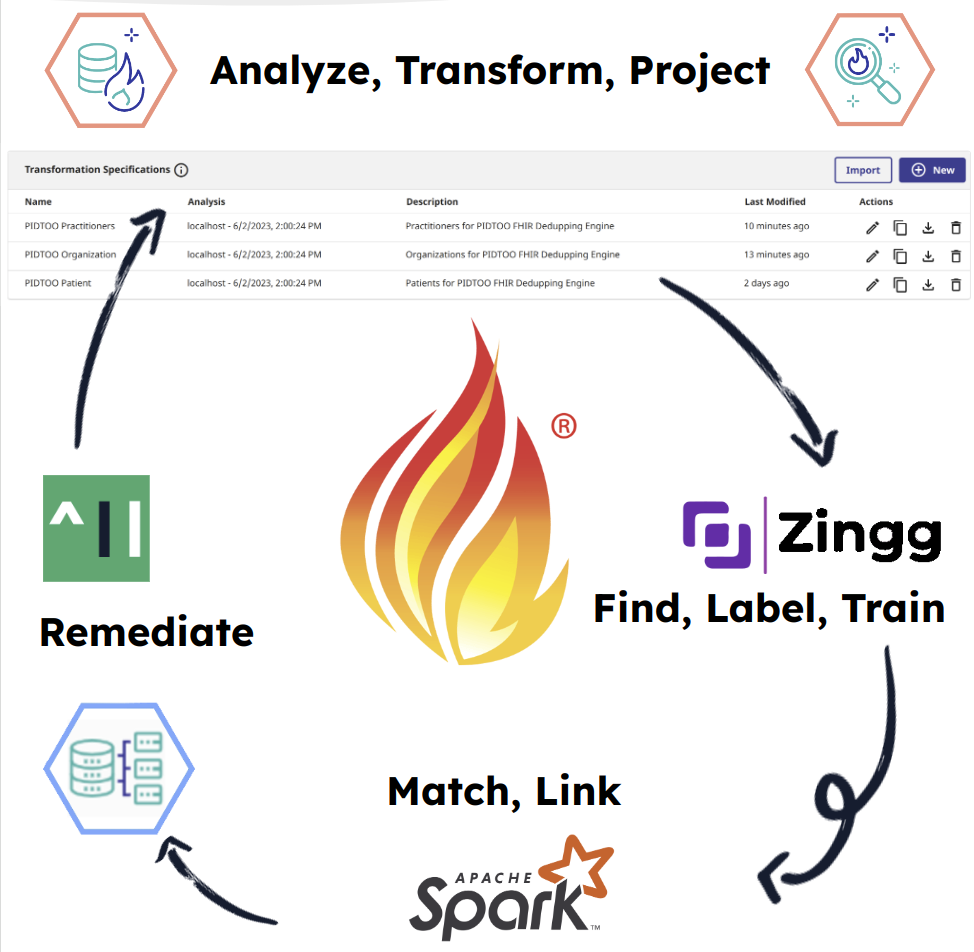
Il faut s'y mettre, dit-on...
SQL FHIR
Nous avons bénéficié d'un essai complet de "Health Connect Cloud" pour la durée de l'incubateur, qui incluait le serveur FHIR avec FHIR SQL activé.
Le constructeur FHIR SQL Builder (abrégé "constructeur") est un outil de projection sophistiqué qui aide les développeurs à créer des schémas SQL personnalisés en utilisant les données de leur référentiel FHIR (Fast Healthcare Interoperability Resources) sans déplacer les données vers un référentiel SQL distinct. L'objectif du constructeur est de permettre aux analystes de données et aux développeurs de business intelligence de travailler avec FHIR en utilisant des outils analytiques familiers, tels que ANSI SQL, Power BI ou Tableau, sans avoir à apprendre une nouvelle syntaxe de requête.
C'est vrai, n'est-ce pas ? Super génial, maintenant notre "builder" va accéder au travail de projection des champs dont nous avons besoin pour identifier les enregistrements dupliqués avec Zingg.
La première étape est celle de l'analyse, à laquelle vous pouvez très bien accéder en cliquant sur celle-ci. Il suffit de faire pointer l'analyse vers " localhost ", qui est essentiellement le serveur FHIR d'InterSystems situé juste en dessous.

Les transformations sont l'élément critique à obtenir, vous devez construire ces champs pour aplatir les ressources FHIR afin qu'elles puissent être lues pour prendre des décisions sur le super serveur SQL. Il faudra probablement y réfléchir, car plus vous transformez de champs en SQL, plus votre modèle d'apprentissage automatique sera performant lors de la prospection double.
En règle générale, c'est un gestionnaire de données qui devrait créer ces données, mais j'en ai créé quelques-unes pour la démo avec une simplicité douteuse, en utilisant le "costume de clown" et en appuyant sur le crayon pour les générer, mais compte tenu de la sophistication à laquelle elles peuvent accéder, vous pouvez également les importer et les exporter. Portez une attention particulière au " Paquet " (" Package ") et au " Nom " (" Name ") car ce sera la table source pour votre connexion sql.

Cette transformation indique essentiellement que nous voulons utiliser le nom et le sexe pour détecter les duplications.
Exemple de transformation de patient
La dernière partie consiste essentiellement à planifier le travail de projection des données vers un schéma cible. Je pense que vous serez actuellement surpris de constater qu'au fur et à mesure que les données sont ajoutées au serveur FHIR, les projections se remplissent automatiquement, ouf.

| Maintenant, pour sceller l'accord avec la configuration de FHIR SQL, vous pouvez voir la projection pour le patient (PIDTOO.Patient) être visible, puis vous créez une autre table pour stocker le résultat de la déduplication (PIDTOO.PatientDups). | 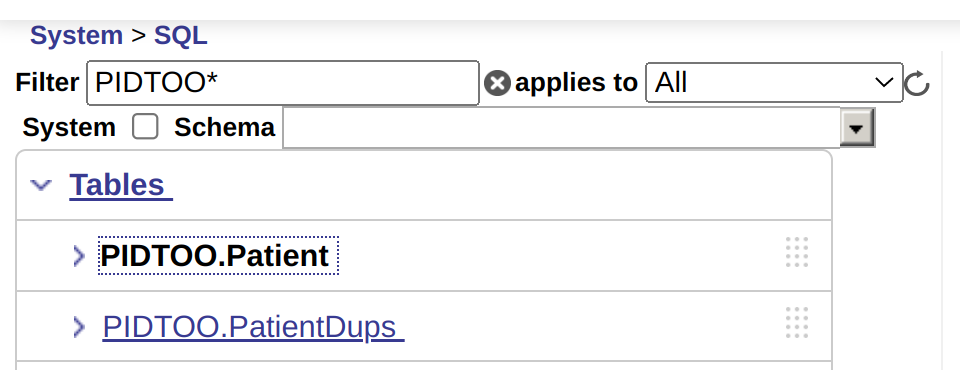 |
Une autre étape à réaliser est l'activation du pare-feu afin que les connexions externes soient activées pour votre déploiement et que vous ayez autorisé l'accès au bloc CIDR source se connectant au super serveur.

Marquez mentalement la page de présentation, car elle contient les informations de connectivité et les informations d'identification nécessaires pour se connecter avant de passer à l'étape suivante.


DeDupe avec Zingg est super puissant, OSS, fonctionne sur Spark et s'adapte à votre portefeuille lorsqu'il s'agit de dédupliquer des ensembles de données de toutes tailles. Je ne veux pas trop simplifier la tâche, mais la réalité est que la documentation, le conteneur fonctionnel sont suffisants pour être opérationnels très rapidement. Nous nous en tiendrons à l'essentiel pour souligner ce qu'il faut faire pour exécuter votre premier travail de déduplication sur une base de données IRIS.
Installation
Clonez le référentiel zingg.ai : https://github.com/zinggAI/zingg
Nous avons également besoin du pilote JDBC pour Zingg afin de nous connecter à IRIS. Téléchargez le pilote JDBC d'IRIS et ajoutez le chemin du pilote à la propriété spark.jars de zingg.conf... organisez ce jar dans le répertoire \`thirdParty/lib\`.
spark.jars=/home/sween/Desktop/PIDTOO/api/zingg/thirdParty/lib/intersystems-jdbc-3.7.1.jar
Critères de concordance
Cette étape demande un peu de réflexion et peut être amusante si vous vous intéressez à ce sujet ou si vous aimez écouter les enregistrements de boîtes noires d'accidents d'avion sur YouTube. Pour démontrer les choses, rappelez-vous les champs que nous avons projetés à partir du constructeur "builder" pour établir les critères de correspondance. Tout ceci est fait dans notre implémentation python qui déclare le job PySpark, qui sera révélé dans son intégralité un peu plus loin.
# FHIRSQL Objet source FIELDDEF
# Astuce de pro !
# Ces champs sont inclus dans les projections FHIRSQL, mais ne sont pas spécifiés dans la transformation (Transform)
fhirkey = FieldDefinition("Key", "string", MatchType.DONT_USE)
dbid = FieldDefinition("ID", "string", MatchType.DONT_USE)
# Actual Fields from the Projection
srcid = FieldDefinition("IdentifierValue", "string", MatchType.DONT_USE)
given = FieldDefinition("NameFamily", "string", MatchType.FUZZY)
family = FieldDefinition("NameGiven", "string", MatchType.FUZZY)
zip = FieldDefinition("AddressPostalCode", "string", MatchType.ONLY_ALPHABETS_FUZZY)
gender = FieldDefinition("Gender", "string", MatchType.FUZZY)
fieldDefs = [fhirkey, dbid, srcid, given, family,zip, gender]Les champs correspondent donc aux attributs de notre projet IRIS et aux MatchTypes que nous avons définis pour chaque type de champ. Vous serez ravis de ce qui est disponible, car vous pourrez immédiatement en faire bon usage en toute connaissance de cause. Voici trois types de champs courants :
- FUZZY: Correspondance généralisée avec des chaînes de caractères et autres éléments
- EXACT: Aucune variation n'est autorisée, valeur déterministe, protection contre les conflits de domaine.
- DONT_USE: Champs qui n'ont rien à voir avec la correspondance, mais qui sont nécessaires à la remédiation ou à la compréhension des résultats.
Voici quelques autres de mes favoris, qui semblent mieux travailler sur les données sales et donner un sens à de multiples courriels.
- EMAIL: Supprime le nom de domaine et le @, et utilise la chaîne.
- TEXT: Ce qu'il y a entre deux chaînes
- ONLY_ALPHABETS_FUZZY: Omet les entiers et les non-alphas lorsqu'ils n'ont manifestement pas leur place pour la prise en compte des correspondances.
Pour les curieux, la liste complète est disponible ici.
Modèle
Créez un dossier pour construire votre modèle... celui-ci correspond au standard dans le repo, créez le dossier \`models/700\`.
# Object MODEL
args = Arguments()
args.setFieldDefinition(fieldDefs)
args.setModelId("700")
args.setZinggDir("/home/sween/Desktop/PIDTOO/api/zingg/models")
args.setNumPartitions(4)
args.setLabelDataSampleSize(0.5)Entrée
Ces valeurs sont représentées dans ce que nous avons mis en place dans les étapes précédentes sur le constructeur "builder"
# "builder" Objet projeté FIELDDEFS
InterSystemsFHIRSQL = Pipe("InterSystemsFHIRSQL", "jdbc")
InterSystemsFHIRSQL.addProperty("url","jdbc:IRIS://3.131.15.187:1972/FHIRDB")
InterSystemsFHIRSQL.addProperty("dbtable", "PIDTOO.Patient")
InterSystemsFHIRSQL.addProperty("driver", "com.intersystems.jdbc.IRISDriver")
InterSystemsFHIRSQL.addProperty("user","fhirsql")
# Utilisez le même mot de passe que celui qui figure sur votre bagage
InterSystemsFHIRSQL.addProperty("password","1234")
args.setData(InterSystemsFHIRSQL)Résultat
Ce tableau n'est pas un tableau projeté par le "constructeur", c'est un tableau vide que nous avons créé pour accueillir les résultats de Zingg.
# L'objet de destination de Zingg sur IRIS
InterSystemsIRIS = Pipe("InterSystemsIRIS", "jdbc")
InterSystemsIRIS.addProperty("url","jdbc:IRIS://3.131.15.187:1972/FHIRDB")
InterSystemsIRIS.addProperty("dbtable", "PIDTOO.PatientDups")
InterSystemsIRIS.addProperty("driver", "com.intersystems.jdbc.IRISDriver")
InterSystemsIRIS.addProperty("user","fhirsql")
# Utilisez le même mot de passe que celui qui figure sur votre bagage
InterSystemsIRIS.addProperty("password","1234")
args.setOutput(InterSystemsIRIS)Si vous essayez de comprendre le déroulement des opérations, j'espère que cela clarifiera les choses.
- Zingg lit les données projetées du constructeur (PIDTOO.Patient).
- Nous effectuons un " Shampoing ML " sur les données.
- Nous écrivons ensuite les résultats dans le constructeur (PIDTOO.PatientDups).
Merci à @Sergei Shutov pour les icônes !
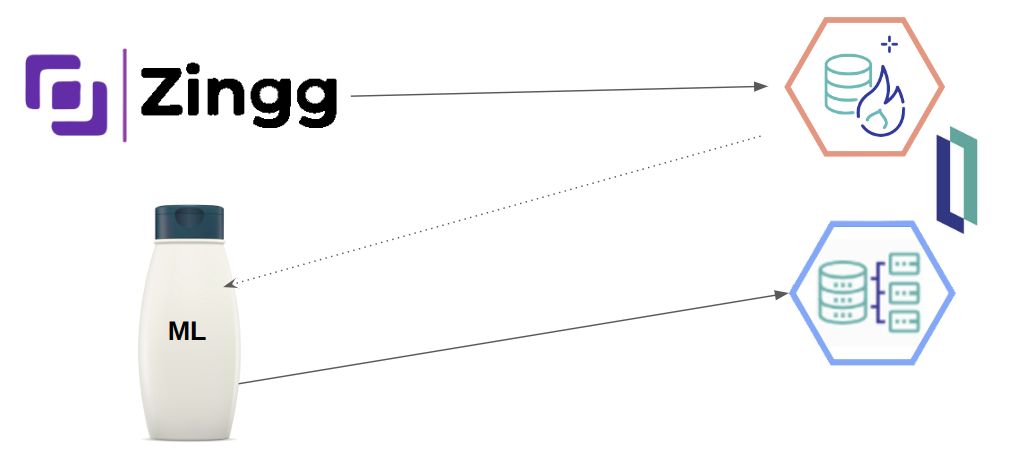
Shampoing ML
Zingg est une implémentation d'apprentissage automatique supervisé, vous allez donc devoir l'entraîner au début, et à intervalles réguliers pour que le modèle reste intelligent. C'est la partie "rincer et répéter" de l'analogie si vous n'avez pas compris ce que je viens de dire à propos du shampoing.
- Trouver - Accéder à des données
- Étiqueter - Inviter un être humain à nous aider
- Train - Une fois que nous avons suffisamment de données étiquetées
- Correspondance - Zingg écrit les résultats
- Lien
bash scripts/zingg.sh --properties-file config/zingg-iris.conf --run pidtoo-iris/FHIRPatient-IRIS.py findTrainingData
bash scripts/zingg.sh --properties-file config/zingg-iris.conf --run pidtoo-iris/FHIRPatient-IRIS.py label
bash scripts/zingg.sh --properties-file config/zingg-iris.conf --run pidtoo-iris/FHIRPatient-IRIS.py trainPour la recherche, vous obtiendrez quelque chose qui ressemble un peu à ce qui suit si les choses se déroulent correctement.
findTrainingData
2023-06-07 16:20:03,677 [Thread-6] INFO zingg.ZinggBase - Start reading internal configurations and functions
2023-06-07 16:20:03,690 [Thread-6] INFO zingg.ZinggBase - Finished reading internal configurations and functions
2023-06-07 16:20:03,697 [Thread-6] WARN zingg.util.PipeUtil - Reading input jdbc
2023-06-07 16:20:03,697 [Thread-6] WARN zingg.util.PipeUtil - Reading Pipe [name=InterSystemsFHIRSQL, format=jdbc, preprocessors=null, props={password=1234luggage, driver=com.intersystems.jdbc.IRISDriver, dbtable=PIDTOO.Patient, user=fhirsql, url=jdbc:IRIS://3.131.15.187:1972/FHIRDB}, schema=null]
2023-06-07 16:20:38,708 [Thread-6] WARN zingg.TrainingDataFinder - Read input data 71383
2023-06-07 16:20:38,709 [Thread-6] WARN zingg.util.PipeUtil - Reading input parquet
2023-06-07 16:20:38,710 [Thread-6] WARN zingg.util.PipeUtil - Reading Pipe [name=null, format=parquet, preprocessors=null, props={location=/home/sween/Desktop/PIDTOO/api/zingg/models/700/trainingData//marked/}, schema=null]
2023-06-07 16:20:39,130 [Thread-6] WARN zingg.util.DSUtil - Read marked training samples
2023-06-07 16:20:39,139 [Thread-6] WARN zingg.util.DSUtil - No configured training samples
2023-06-07 16:20:39,752 [Thread-6] WARN zingg.TrainingDataFinder - Read training samples 37 neg 64
2023-06-07 16:20:39,946 [Thread-6] INFO zingg.TrainingDataFinder - Preprocessing DS for stopWords
2023-06-07 16:20:40,275 [Thread-6] INFO zingg.util.Heuristics - **Block size **35 and total count was 35695
2023-06-07 16:20:40,276 [Thread-6] INFO zingg.util.Heuristics - Heuristics suggest 35
2023-06-07 16:20:40,276 [Thread-6] INFO zingg.util.BlockingTreeUtil - Learning indexing rules for block size 35
2023-06-07 16:20:40,728 [Thread-6] WARN org.apache.spark.sql.execution.CacheManager - Asked to cache already cached data.
2023-06-07 16:20:40,924 [Thread-6] INFO zingg.util.ModelUtil - Learning similarity rules
2023-06-07 16:20:41,072 [Thread-6] WARN org.apache.spark.sql.catalyst.util.package - Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.sql.debug.maxToStringFields'.
2023-06-07 16:20:41,171 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] Stage class: LogisticRegression
2023-06-07 16:20:41,171 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] Stage uid: logreg_d240511c93be
2023-06-07 16:20:41,388 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] training: numPartitions=1 storageLevel=StorageLevel(1 replicas)
2023-06-07 16:20:41,390 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"featuresCol":"z_feature","fitIntercept":true,"labelCol":"z_isMatch","predictionCol":"z_prediction","probabilityCol":"z_probability","maxIter":100}
2023-06-07 16:20:41,752 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"numClasses":2}
2023-06-07 16:20:41,752 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"numFeatures":164}
2023-06-07 16:20:41,752 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"numExamples":101}
2023-06-07 16:20:41,753 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"lowestLabelWeight":"37.0"}
2023-06-07 16:20:41,753 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"highestLabelWeight":"64.0"}
2023-06-07 16:20:41,755 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"sumOfWeights":101.0}
2023-06-07 16:20:41,756 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"actualBlockSizeInMB":"1.0"}
2023-06-07 16:20:42,149 [Executor task launch worker for task 0.0 in stage 29.0 (TID 111)] WARN com.github.fommil.netlib.BLAS - Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
2023-06-07 16:20:42,149 [Executor task launch worker for task 0.0 in stage 29.0 (TID 111)] WARN com.github.fommil.netlib.BLAS - Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS
2023-06-07 16:20:44,470 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [5a6fd183] training finished
2023-06-07 16:20:44,470 [Thread-6] INFO zingg.model.Model - threshold while predicting is 0.5
2023-06-07 16:20:44,589 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [aa3d8dc3] training finished
2023-06-07 16:20:44,600 [Thread-6] INFO zingg.TrainingDataFinder - Writing uncertain pairs
2023-06-07 16:20:47,788 [Thread-6] WARN zingg.util.PipeUtil - Writing output Pipe [name=null, format=parquet, preprocessors=null, props={location=/home/sween/Desktop/PIDTOO/api/zingg/models/700/trainingData//unmarked/}, schema=null]Maintenant, nous entraînons le Cylon avec l'apprentissage supervisé, essayons de le faire accéder.
Label
2023-06-07 16:24:06,122 [Thread-6] INFO zingg.Labeller - Processing Records for CLI Labelling
Labelled pairs so far : 37/101 MATCH, 64/101 DO NOT MATCH, 0/101 NOT SURE
Current labelling round : 0/20 pairs labelled
+----------------+------+---------------+----------+---------+-----------------+------+-------------------+
|Key |ID |IdentifierValue|NameFamily|NameGiven|AddressPostalCode|Gender|z_source |
+----------------+------+---------------+----------+---------+-----------------+------+-------------------+
|Patient/05941921|303302|null |davis |derek |28251 |male |InterSystemsFHIRSQL|
|Patient/05869254|263195|null |davis |terek |27|07 |male |InterSystemsFHIRSQL|
+----------------+------+---------------+----------+---------+-----------------+------+-------------------+
Zingg predicts the above records MATCH with a similarity score of 0.51
What do you think? Your choices are:
No, they do not match : 0
Yes, they match : 1
Not sure : 2
To exit : 9
Please enter your choice [0,1,2 or 9]: Maintenant, faites ce que le cylon vous dit, et faites-le souvent, peut-être pendant des réunions ou sur la Ligne Rouge en allant ou en rentrant du travail (vous comprenez ? Train). Vous aurez besoin de suffisamment d'étiquettes pour la phase de train, où Zingg accède à la ville et fait des miracles pour trouver les duplications.
bash scripts/zingg.sh --properties-file config/zingg-iris.conf --run pidtoo-iris/FHIRPatient-IRIS.py trainOk, nous y voilà, obtenons nos résultats :
bash scripts/zingg.sh --properties-file config/zingg-iris.conf --run pidtoo-iris/FHIRPatient-IRIS.py matchNous avons maintenant des résultats dans le tableau PIDTOO.PatientDups qui nous permettent d'aller à l'essentiel. Nous allons accéder à la sorcellerie sqlalchemy de @Dmitry Maslennikov pour nous connecter via le Notebook et inspecter nos résultats.
from sqlalchemy import create_engine
# FHIRSQL Builder Cloud Instance
engine = create_engine("iris://fhirsql:1234@3.131.15.187:1972/FHIRDB")
conn = engine.connect()
query = '''
SELECT
TOP 20 z_cluster, z_maxScore, z_minScore, NameGiven, NameFamily, COUNT(*)
FROM
PIDTOO.PatientDups
GROUP BY
z_cluster
HAVING
COUNT(*) > 1
'''
result = conn.exec_driver_sql(query)
print(result)Il faut un peu de temps pour interpréter les résultats, mais voici le résultat de la brève formation sur le chargement des données des électeurs de NC dans FHIR.
loadncvoters2fhir.py ©
import os
import requests
import json
import csv
'''
recid,givenname,surname,suburb,postcode
07610568,ranty,turner,statesvikle,28625
'''
for filename in os.listdir("."):
print(filename)
if filename.startswith("ncvr"):
with open(filename, newline='') as csvfile:
ncreader = csv.reader(csvfile, delimiter=',')
for row in ncreader:
patid = row[0]
given = row[1]
family = row[2]
postcode = row[4]
patientpayload = {
"resourceType": "Patient",
"id": patid,
"active": True,
"name": [
{
"use": "official",
"family": family,
"given": [
given
]
}
],
"gender": "male",
"address": [
{
"postalCode": postcode
}
]
}
print(patientpayload)
url = "https://fhir.h7kp7tr48ilp.workload-nonprod-fhiraas.isccloud.io/Patient/" + patid
headers = {
'x-api-key': '1234',
'Content-Type': 'application/fhir+json'
}
response = requests.request("PUT", url, headers=headers, data=json.dumps(patientpayload))
print(response.status_code)Le résultat obtenu par Zingg est très bon pour le peu d'efforts que je consacre à la formation entre deux éclairages au gaz.
z_cluster est l'identifiant que Zingg attribue aux duplications, je l'appelle le "dupeid", comprenez simplement qu'il s'agit de l'identifiant de l'élément que vous souhaitez interroger pour examiner les duplications potentielles... Je suis habitué à faire confiance à un minScore de 0.00 et à tout ce qui est supérieur à 0.90 pour un score d'examen.
(189, 0.4677305247393828, 0.4677305247393828, 'latonya', 'beatty', 2)
(316, 0.8877195988867068, 0.7148998161578, 'wiloiam', 'adams', 5)
(321, 0.5646965557084127, 0.0, 'mar9aret', 'bridges', 3)
(326, 0.5707960437038071, 0.0, 'donnm', 'johnson', 6)
(328, 0.982044685998597, 0.40717509762282955, 'christina', 'davis', 4)
(333, 0.8879795543643093, 0.8879795543643093, 'tiffany', 'stamprr', 2)
(334, 0.808243240184001, 0.0, 'amanta', 'hall', 4)
(343, 0.6544295790716498, 0.0, 'margared', 'casey', 3)
(355, 0.7028336885619522, 0.7028336885619522, 'dammie', 'locklear', 2)
(357, 0.509141927875999, 0.509141927875999, 'albert', 'hardisfon', 2)
(362, 0.5054569794103886, 0.0, 'zarah', 'hll', 6)
(366, 0.4864567456390275, 0.4238040425261962, 'cara', 'matthews', 4)
(367, 0.5210329255531461, 0.5210329255531461, 'william', 'metcaif', 2)
(368, 0.6431091575056218, 0.6431091575056218, 'charles', 'sbarpe', 2)
(385, 0.5338624802449684, 0.0, 'marc', 'moodt', 3)
(393, 0.5640435106505274, 0.5640435106505274, 'marla', 'millrr', 2)
(403, 0.4687497402769476, 0.0, 'donsna', 'barnes', 3)
(407, 0.5801171648347092, 0.0, 'veronicc', 'collins', 35)
(410, 0.9543673811569922, 0.0, 'ann', 'mason', 7)
(414, 0.5355771790403805, 0.5355771790403805, 'serry', 'mccaray', 2)Choisissons le 410 "dupeid" et voyons ce qu'il en est. Les résultats semblent indiquer qu'il y a 7 duplications.

Ok, il y a donc les 7 enregistrements, avec des scores variables... Nous allons ajuster un peu plus et n'indiquer que les scores supérieurs à 0,90.
.png)
Bravo ! Si vous vous souvenez bien, nous avons maintenant le `MatchType.DONT_USE` pour `Key` dans nos critères de correspondance qui apparaît dans notre résultat, mais vous savez quoi ?
USE IT!
- https://fhir.h7kp7tr48ilp.workload-nonprod-fhiraas.isccloud.io/Patient/…
- https://fhir.h7kp7tr48ilp.workload-nonprod-fhiraas.isccloud.io/Patient/…
Il s'agit des identifiants de ressources patient FHIR dans le référentiel FHIR que nous avons identifiés comme étant des duplications et nécessitant une remédiation. 🔥