Support des vecteurs, enfin presque
Aujourd'hui, il y a beaucoup de bruit autour du LLM, de l'IA, etc. Les bases de données vectorielles en font partie, et il existe déjà de nombreuses réalisations différentes pour le support en dehors d'IRIS.
Pourquoi Vector?
- Recherche de similarité : Les vecteurs assurent une recherche de similarité efficace, par exemple en trouvant les éléments ou les documents les plus similaires dans un ensemble de données. Les bases de données relationnelles classiques sont conçues pour des recherches de correspondances exactes, qui ne sont pas adaptées à des tâches telles que la recherche de similitudes d'images ou de textes.
- Flexibilité : Les représentations vectorielles sont polyvalentes et peuvent être obtenues à partir de différents types de données, tels que du texte (via des embeddings comme Word2Vec, BERT), des images (via des modèles d'apprentissage profond), et autres.
-
- Recherches multimodales** : Les vecteurs permettent d'effectuer des recherches dans différentes modalités de données. Par exemple, avec une représentation vectorielle d'une image, on peut rechercher des images similaires ou des textes connexes dans une base de données multimodale.
Et pour bien d'autres raisons encore.
Donc, pour ce concours python, j'ai décidé de mettre en place ce support. Et malheureusement, je n'ai pas réussi à le terminer à temps, je vais vous expliquer pourquoi.
 Il y a un certain nombre de choses importantes à faire pour qu'il soit complet
Il y a un certain nombre de choses importantes à faire pour qu'il soit complet
- Accepter et stocker des données vectorisées, avec SQL, exemple simple, (3 dans cet exemple est le nombre de dimensions, il est fixé par champ, et tous les vecteurs dans le champ doivent avoir des dimensions exactes)
create table items(embedding vector(3)); insert into items (embedding) values ('[1,2,3]'); insert into items (embedding) values ('[4,5,6]'); - Fonctions de similarité, il existe des algorithmes de similarité différents, adaptés à une recherche simple sur une petite quantité de données, sans utiliser d'index
-- Euclidean distance select embedding, vector.l2_distance(embedding, '[9,8,7]') distance from items order by distance; -- Cosine similarity select embedding, vector.cosine_distance(embedding, '[9,8,7]') distance from items order by distance; -- Inner product select embedding, -vector.inner_product(embedding, '[9,8,7]') distance from items order by distance; - Index personnalisé, pour accélérer la recherche sur une grande quantité de données. Les index peuvent utiliser un algorithme différent et des fonctions de distance différentes de celles mentionnées ci-dessus, ainsi que d'autres options.
- HNSW
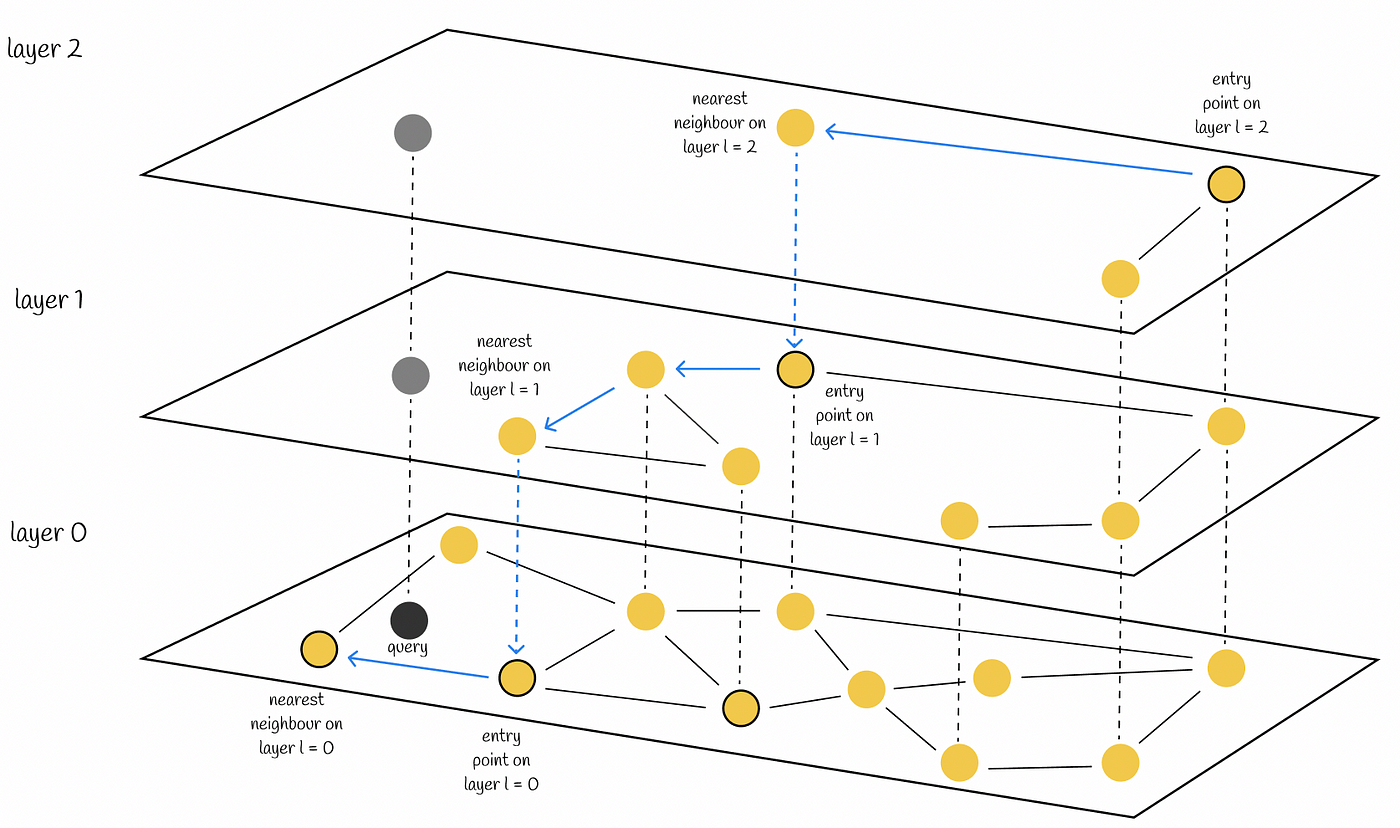
- Index de fichier inversé
.png)
- HNSW
- La recherche n'utilisera que l'index créé et son algorithme trouvera l'information demandée.
Insertion de vecteurs
On suppose que le vecteur est un tableau de valeurs numériques, lesquelles peuvent être des entiers ou des flottants, ainsi que signées ou non. Dans IRIS, nous pouvons le stocker comme $listbuild, il a une bonne représentation, il est déjà supporté, il faut seulement implémenter la conversion d'ODBC en logique.
Les valeurs peuvent ensuite être insérées sous forme de texte brut à l'aide de pilotes externes tels que ODBC/JDBC ou à partir d'IRIS avec ObjectScript.
insert into items (embedding) values ('[1,2,3]');set rs = ##class(%SQL.Statement).%ExecDirect(, "insert into test.items (embedding) values ('[1,2,3]')")
set rs = ##class(%SQL.Statement).%ExecDirect(, "insert into test.items (embedding) values (?)", $listbuild(2,3,4))
&sql(insert into test.items (embedding) values ('[1,2,3]'))
set val = $listbuild(2,3,4)
&sql(insert into test.items (embedding) values (:val))
Il sera toujours stocké sous la forme de $lb(), et renvoyé au format textuel dans ODBC.
J'ai ensuite découvert que JDBC utilise les insertions rapide Fast Inserts par défaut, dans ce cas, les données insérées sont stockées directement dans les globales, et j'ai donc dû les désactiver manuellement
Dans DBeaver, sélectionnez optfastSelect dans le champ FeatureOption.
.png)
Calculations
Les vecteurs sont principalement nécessaires pour calculer les distances entre deux vecteurs.
Pour le concours, j'ai eu besoin d'utiliser l'outil Embedded Python, et c'est là que se pose le problème de savoir comment utiliser $lb dans Embedded Python. Il y a une méthode ToList dans %SYS.Class, mais le paquetage d'iris de Python ne l'a pas intégrée, et il faut l'appeler comme ObjectScript.
ClassMethod l2DistancePy(v1 As dc.vector.type, v2 As dc.vector.type) As %Decimal(SCALE=10) [ Language = python, SqlName = l2_distance_py, SqlProc ]
{
import iris
import math
vector_type = iris.cls('dc.vector.type')
v1 = iris.cls('%SYS.Python').ToList(vector_type.Normalize(v1))
v2 = iris.cls('%SYS.Python').ToList(vector_type.Normalize(v2))
return math.sqrt(sum([(val1 - val2) ** 2 for val1, val2 in zip(v1, v2)]))
}
Cela ne semble pas correct du tout. Je préférerais que $lb puisse être interprété directement comme une liste en python, ou comme les fonctions intégrées to_list et from_list.
Un autre problème s'est posé lorsque j'ai essayé de tester cette fonction de différentes manières. En utilisant SQL à partir d'Embedded Python qui emploie la fonction SQL écrite dans Embedded Python, elle se plante. J'ai donc dû ajouter les fonctions ObjectScript.
ModuleNotFoundError: No module named 'dc' SQL Function VECTOR.NORM_PY failed with error: SQLCODE=-400,%msg=ERROR #5002: ObjectScript error:
Les fonctions sont actuellement implémentées pour calculer la distance, à la fois en Python et en ObjectScript
- Distance euclidienne
[SQL]_system@localhost:USER> select embedding, vector.l2_distance_py(embedding, '[9,8,7]') distance from items order by distance; +-----------+----------------------+ | embedding | distance | +-----------+----------------------+ | [4,5,6] | 5.91607978309961613 | | [1,2,3] | 10.77032961426900748 | +-----------+----------------------+ 2 rows in set Time: 0.011s [SQL]_system@localhost:USER> select embedding, vector.l2_distance(embedding, '[9,8,7]') distance from items order by distance; +-----------+----------------------+ | embedding | distance | +-----------+----------------------+ | [4,5,6] | 5.916079783099616045 | | [1,2,3] | 10.77032961426900807 | +-----------+----------------------+ 2 rows in set Time: 0.012s - Similarité cosinus
[SQL]_system@localhost:USER> select embedding, vector.cosine_distance(embedding, '[9,8,7]') distance from items order by distance;
+-----------+---------------------+
| embedding | distance |
+-----------+---------------------+
| [4,5,6] | .034536677566264152 |
| [1,2,3] | .11734101007866331 |
+-----------+---------------------+
2 rows in set
Time: 0.034s
[SQL]_system@localhost:USER> select embedding, vector.cosine_distance_py(embedding, '[9,8,7]') distance from items order by distance;
+-----------+-----------------------+
| embedding | distance |
+-----------+-----------------------+
| [4,5,6] | .03453667756626421781 |
| [1,2,3] | .1173410100786632659 |
+-----------+-----------------------+
2 rows in set
Time: 0.025s
Produit scalaire
[SQL]_system@localhost:USER> select embedding, vector.inner_product_py(embedding, '[9,8,7]') distance from items order by distance;
+-----------+----------+
| embedding | distance |
+-----------+----------+
| [1,2,3] | 46 |
| [4,5,6] | 118 |
+-----------+----------+
2 rows in set
Time: 0.035s
[SQL]_system@localhost:USER> select embedding, vector.inner_product(embedding, '[9,8,7]') distance from items order by distance;
+-----------+----------+
| embedding | distance |
+-----------+----------+
| [1,2,3] | 46 |
| [4,5,6] | 118 |
+-----------+----------+
2 rows in set
Time: 0.032s
En outre, les fonctions mathématiques suivantes ont été intégrées : add (ajouter), sub (sous), div (diviser), mul (multiplier). InterSystems permet de créer ses propres fonctions d'agrégation. Ainsi, il serait possible de faire la somme totale de tous les vecteurs ou de trouver la moyenne. Malheureusement, InterSystems ne permet pas d'utiliser le même nom et nécessite l'utilisation d'un nom (et d'un schéma) propre pour la fonction. Mais il ne prend pas en charge les résultats non numériques pour les fonctions d'agrégation.
La fonction vector_add simple, qui renvoie la somme de deux vecteurs
.png)
Lorsqu'elle est utilisée en tant qu'agrégat, la valeur est de 0, alors que le vecteur attendu est également de 0.
.png)
Création d'un index
Malheureusement, je n'ai pas réussi à terminer cette partie, en raison de certains obstacles que j'ai rencontrés lors de la réalisation.
- L'absence de $lb intégré à des conversions de listes python et inversement lorsque le vecteur dans IRIS est stocké dans $lb, et que toute la logique de construction de l'index est censée être en Python, il est important également de récupérer les données de $lb et de les réintégrer dans les globales.
absence de support pour les globales
-
Dans IRIS, $Order supporte la direction, cette fonction peut donc être utilisée en sens inverse, alors que la réalisation de l'ordre dans Python Embedded ne la supporte pas, il faudra donc lire toutes les clés et les inverser ou stocker la fin quelque part.
J'ai des doutes suite à une mauvaise expérience avec les fonctions SQL de Python, appelées à partir de Python mentionné ci-dessus.
Au cours de la construction de l'index, il était prévu de stocker les distances dans le graphe entre les vecteurs, mais un bogue s'est produit lors du stockage de nombres flottants dans les données globales de l'index.
J'ai abordé 11 problèmes avec Embedded Python que j'ai trouvés pendant le travail, donc la plupart du temps il faut trouver des solutions de contournement pour résoudre les problèmes. Avec l'aide du projet de @Guillaume Rongier nommé iris-dollar-list j'ai réussi à résoudre certains problèmes.
Installation
Quoi qu'il en soit, ce logiciel est toujours disponible et peut être installé avec IPM, et utilisé même avec des fonctionnalités limitées.
zpm "install vector"Ou en mode de développement avec docker-compose
git clone https://github.com/caretdev/iris-vector.git
cd iris-vector
docker-compose up -d