Guide de création d'une IA personnalisée avec ChatGPT en utilisant LangChain, étape par étape
.png)
En tant que modèle linguistique d'IA, ChatGPT est capable d'effectuer une variété de tâches telles que traduire, écrire des chansons, répondre à des questions de recherche et même générer du code informatique. Avec ses capacités impressionnantes, ChatGPT est rapidement devenu un outil populaire pour diverses applications, des chatbots à la création de contenu.
Mais malgré ses capacités avancées, ChatGPT n'est pas en mesure d'accéder à vos données personnelles. Mais malgré ses capacités avancées, ChatGPT n'est pas en mesure d'accéder à vos données personnelles. Ainsi, dans cet article, je vais démontrer les étapes suivantes pour construire une IA ChatGPT personnalisée en utilisant le LangChain Framework:
-
Étape 1: Chargement du document
-
Étape 2: Division du document en blocs
-
Étape 3: Utilisation de l'incorporation pour des blocs de données et leur conversion en vecteurs
-
Étape 4: Enregistrement des données dans la base de données de vecteurs
-
Étape 5: Obtention des données (question) de l'utilisateur et leur the intégration
-
Étape 6: Connexion à VectorDB et recherche sémantique
-
Étape 7: Récupération des réponses pertinentes basées sur les requêtes de l'utilisateur et leur envoi au LLM(ChatGPT)
-
Étape 8: Obtention d'une réponse de la part de LLM et renvoi de celle-ci à l'utilisateur
REMARQUE : Veuillez lire mon article précédent LangChain – Unleashing the full potential of LLMs (LangChain - Libération du plein potentiel des LLM) pour obtenir plus de détails sur LangChain et sur la façon d'obtenir la clé API OpenAI
Alors, commençons
Étape 1: Chargement du document
Tout d'abord, il faut charger le document. Nous allons donc importer PyPDFLoader pour le document PDF
ClassMethod SavePDF(filePath) [ Language = python ]
{
#pour un fichier PDF, il faut importer PyPDFLoader à partir du framework langchain
from langchain.document_loaders import PyPDFLoader
# pour un fichier CSV, il faut importer csv_loader
# pour un fichier Doc, il faut importer UnstructuredWordDocumentLoader
# Pour le document texte, il faut importer TextLoader
#importation de l'os pour définir la variable d'environnement
import os
#attribution de la clé API OpenAI à une variable d'environnement
os.environ['OPENAI_API_KEY'] = "apiKey"
#Init du lanceur
loader = PyPDFLoader(filePath)
#Chargement du document
documents = loader.load()
return documents
}Étape 2: Division du document en blocs
Les modèles linguistiques sont souvent limités par la quantité de texte qui peut leur être transmise. Il est donc nécessaire de les diviser en blocs moins volumineux. LangChain fournit plusieurs utilitaires pour ce faire.
L'utilisation d'un séparateur de texte (Text Splitter) peut également contribuer à améliorer les résultats des recherches dans les répertoires de vecteurs, car, par exemple, des blocs moins volumineux ont parfois plus de chances de correspondre à une requête. Tester différentes tailles de blocs (et leur chevauchement) est un exercice intéressant pour adapter les résultats à votre cas d'utilisation.
ClassMethod splitText(documents) [ Language = python ]
{
#Afin de diviser le document, il faut importer RecursiveCharacterTextSplitter du framework Langchain
from langchain.text_splitter import RecursiveCharacterTextSplitter
#Init du séparateur de texte, définition de la taille des blocs (1000) et du chevauchement. = 0
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
#Division du document en plusieurs blocs
texts = text_splitter.split_documents(documents)
return texts
}Étape 3: Utilisation d'incorporation pour des blocs de données et leur conversion en vecteurs
Les incorporations (embeddings) de texte sont le cœur et l'âme des outils de Large Language Operations.. Techniquement, nous pouvons travailler avec des modèles linguistiques en langage naturel, mais le stockage et l'extraction du langage naturel sont très inefficaces.
Pour améliorer l'efficacité, il faut transformer les données textuelles en formes vectorielles. Il existe des modèles ML dédiés à la création d'intégrations à partir de textes. Les textes sont convertis en vecteurs multidimensionnels. Une fois ces données incorporées, nous pouvons les regrouper, les trier, les rechercher, etc. Nous pouvons calculer la distance entre deux phrases pour connaître leur degré de parenté. Et le plus intéressant, c'est que ces opérations ne se limitent pas à des mots-clés comme dans les recherches traditionnelles dans les bases de données, mais capturent plutôt la proximité sémantique de deux phrases. Cela rend le système beaucoup plus puissant, grâce à l'apprentissage automatique.
Les modèles d'incorporation de texte reçoivent la saisie de texte et renvoient une liste de flottants (embeddings), qui sont la représentation numérique du texte saisi. Les embeddings permettent d'extraire des informations d'un texte. Ces informations peuvent ensuite être utilisées, par exemple, pour calculer les similitudes entre des textes (par exemple, des résumés de films).
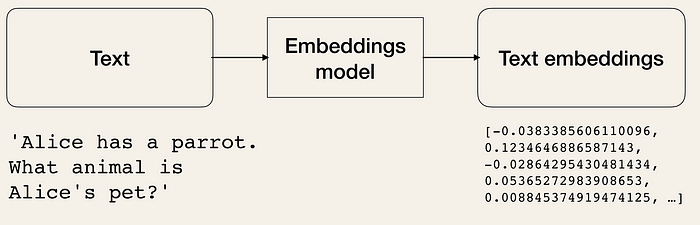
ClassMethod getEmbeddings(query) [ Language = python ]
{
#Obtention d'un modèle d'embeddings à partir du framework Langchain
from langchain.embeddings import OpenAIEmbeddings
#Definition d'embedding
embedding = OpenAIEmbeddings()
return embedding
}
Étape 4: Enregistrement des données dans la base de données de vecteurs
ClassMethod saveDB(texts,embedding) [ Language = python ]
{
#Obtention de la base de données Chroma à partir de langchain
from langchain.vectorstores import Chroma
# Incorporation et stockage des textes
# La fourniture d'un répertoire persistant (persist_directory) permet de stocker les embeddings sur le disque
# par exemple dans le dossier myData du chemin d'accès à l'application en cours
persist_directory = "myData"
vectordb = Chroma.from_documents(documents=texts, embedding=embedding, persist_directory=persist_directory)
#sauvegarde du document au niveau local
vectordb.persist()
vectordb = None
}
Étape 5: Obtention des données (question) de l'utilisateur et leur the intégration
ClassMethod getVectorData(query) [ Language = python ]
{
#REMARQUE: Il faudrait avoir le même embedding utilisée lorsque nous avons sauvegardé des données
from langchain.embeddings import OpenAIEmbeddings
#obtention d'embeddings
embedding = OpenAIEmbeddings()
#saisie des données de l'utilisateur (paramètre)
query = query
#La suite du code...
Étape 6: Connexion à VectorDB et recherche sémantique
#code continue....
from langchain.vectorstores import Chroma
persist_directory = "myData"
## À présent, il est possible de charger la base de données persistante à partir du disque et de l'utiliser comme d'habitude.
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
return vectordb
}Étape 7: Récupération des réponses pertinentes basées sur les requêtes de l'utilisateur et leur envoi au LLM(ChatGPT)
La mémoire de conversation est la façon dont un chatbot peut répondre à de multiples requêtes à la manière d'un chat. Elle assure une conversation cohérente et, sans elle, chaque requête serait traitée comme une entrée totalement indépendante, sans tenir compte des interactions passées.
LLM avec et sans une mémoire de conversation. Les cases bleues représentent les assistances de l'utilisateur et les cases grises représentent les réponses des LLM. Sans mémoire de conversation (à droite), les LLM ne peuvent pas répondre en utilisant la connaissance des interactions précédentes.
La mémoire permet le Large Language Model (LLM) de se souvenir des interactions précédentes avec l'utilisateur. Par défaut, les LLMs sont sans état — ce qui signifie que chaque requête entrante est traitée indépendamment des autres interactions. La seule chose qui existe pour un agent sans état est la saisie actuelle, rien d'autre.
Le modèle ConversationalRetrievalChain est un modèle d'IA conversationnelle conçu pour extraire des réponses pertinentes sur la base des requêtes de l'utilisateur. Il fait partie de la technologie de l'équipe de Langchain. Le modèle utilise une approche basée sur la récupération, où il recherche des réponses préexistantes dans une base de données pour trouver la réponse la plus appropriée à une requête donnée. Le modèle est entraîné sur un grand ensemble de conversations pour apprendre les schémas et le contexte afin de fournir des réponses précises et utiles.
ClassMethod retriveResponse(vectordb) [ Language = python ]
{
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
#La mémoire de conversation est la façon dont un chatbot peut répondre à de multiples requêtes.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
#Le ConversationalRetrievalChain est un modèle d'IA conversationnelle conçu pour extraire des réponses pertinentes sur la base des requêtes de l'utilisateur.
qa = ConversationalRetrievalChain.from_llm(OpenAI(temperature=0), vectordb.as_retriever(), memory=memory)
return qa
}
Étape 8: Obtention d'une réponse de la part de LLM et renvoi de celle-ci à l'utilisateur
ClassMethod getAnswer(qa) [ Language = python ]
{
#Obtention d'une réponse de la part de LLM et renvoi de celle-ci à l'utilisateur
getAnswer = qa.run(query)
return getAnswer
}Pour plus de détails et de fonctionnalités, veuillez consulter mon application irisChatGPT
Vidéo connexe
Je vous remercie
Comments
Super article très intéressant et complet !!