QuinielaML - Capture de données avec Embedded Python
Nous poursuivons notre série d'articles basés sur l'application QuinielaML.
.png)
Dans cet article, je décrirai comment travailler avec la fonctionnalité Embedded Python disponible dans les produits InterSystems.
Embedded Python nous permet d'utiliser Python comme langage de programmation dans nos productions, en profitant de toutes les fonctionnalités qu'offre Python. Ici vous pouvez trouver plus d'informations à ce sujet.
Tout d'abord, rappelons la nature du concepteur de l'architecture de notre projet :
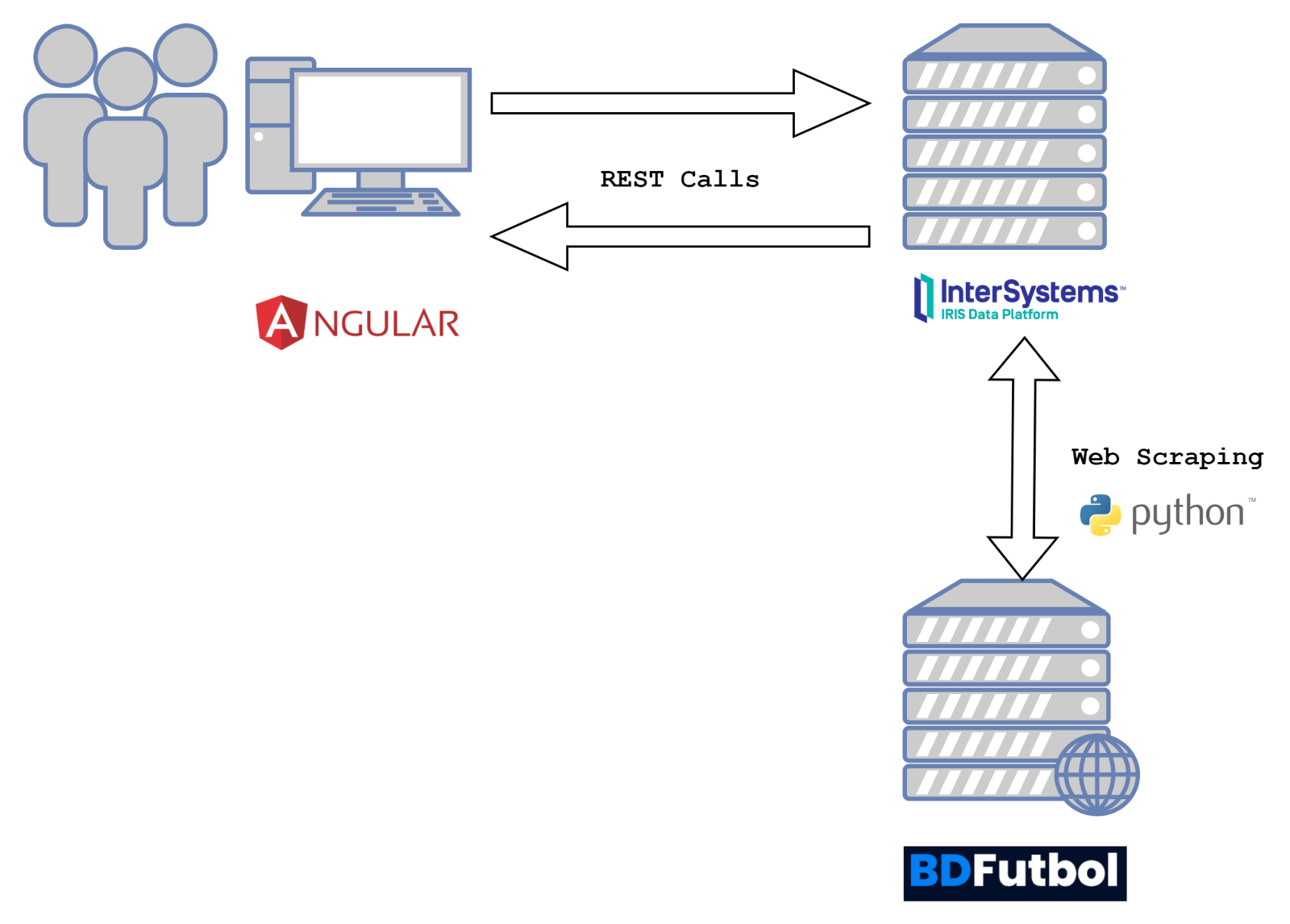
Problème à résoudre
Dans notre cas, il nous faut obtenir les résultats historiques des matches de première et de deuxième division depuis 2000. Nous avons trouvé un site web [BDFutbol] (http://www.bdfutbol.com/es/index.html) qui nous fournit toutes ces données, et le web scraping semble donc la solution la plus appropriée.
Qu'est-ce que le web scraping ?
Le web scraping est une technique qui consiste à capturer automatiquement des informations à partir de pages web en simulant la navigation de la même manière que le ferait un être humain.
Pour réaliser le web scraping, nous devons chercher deux types de bibliothèques, la première qui nous permet d'invoquer les URL à partir desquelles nous voulons obtenir l'information et la seconde qui nous permet de parcourir la page web capturée et d'en extraire l'information nécessaire. Pour le premier cas, nous utiliserons la bibliothèque requests, tandis que pour le second, nous avons trouvé beautifulsoup4, vous pouvez consulter sa documentation.
Configuration d'Embedded Python avec Docker
Pour utiliser les bibliothèques Python de notre instance IRIS dans Docker, il faut ajouter les commandes suivantes dans notre fichier Docker :
RUN apt-get update && apt-get install -y python3
RUN apt-get update &&
apt-get install -y libgl1-mesa-glx libglib2.0-0A l'aide de ces commandes, nous installons Python dans notre conteneur, puis nous installons les bibliothèques nécessaires que nous avons enregistrées dans le fichier requirements.txt.
beautifulsoup4==4.12.2
requests==2.31.0Pour son installation, il suffira d'ajouter la commande suivante dans notre Dockerfile :
<
RUN pip3 install -r /requirements.txtNous avons maintenant tout ce qu'il faut dans notre conteneur pour utiliser les bibliothèques Python nécessaires dans notre production.
Configuration de la production IRIS
La première étape consistera à configurer une méthode spécifique pour gérer les demandes d'importation de données dans notre classe responsable de la réception des appels du frontend :
Class QUINIELA.WS.Service Extends %CSP.REST
{
Parameter HandleCorsRequest = 0;
Parameter CHARSET = "utf-8";
XData UrlMap [ XMLNamespace = "https://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="/getPrediction" Method="GET" Call="GetPrediction" />
<Route Url="/import" Method="GET" Call="ImportRawMatches" />
<Route Url="/getStatus/:operation" Method="GET" Call="GetStatus" />
<Route Url="/prepare" Method="GET" Call="PrepareData" />
<Route Url="/train" Method="GET" Call="TrainData" />
<Route Url="/getReferees" Method="GET" Call="GetReferees" />
<Route Url="/getTeams" Method="GET" Call="GetTeams" />
<Route Url="/saveMatch" Method="POST" Call="SaveMatch" />
<Route Url="/deleteMatch/:matchId" Method="DELETE" Call="DeleteMatch" />
<Route Url="/saveResult" Method="POST" Call="SaveResult" />
<Route Url="/getMatches/:division" Method="GET" Call="GetMatches" />
</Routes>
}
Tout appel avec une URL se terminant par /import sera traité par la méthode ImportRawMatches, examinons cette méthode plus en détail :
ClassMethod ImportRawMatches() As %DynamicObject
{
Try {
Do ##class(%REST.Impl).%SetContentType("application/json")
If '##class(%REST.Impl).%CheckAccepts("application/json") Do ##class(%REST.Impl).%ReportRESTError(..#HTTP406NOTACCEPTABLE,$$$ERROR($$$RESTBadAccepts)) Quit
set newRequest = ##class(QUINIELA.Message.OperationRequest).%New()
set newRequest.Operation = "Import"
set status = ##class(Ens.Director).CreateBusinessService("QUINIELA.BS.FromWSBS", .instance)
set response = ##class(QUINIELA.Message.ImportResponse).%New()
set response.Status = "In Process"
set response.Operation = "Import"
set status = instance.SendRequestAsync("QUINIELA.BP.ImportBPL", newRequest, .response)
if $ISOBJECT(response) {
Do ##class(%REST.Impl).%SetStatusCode("200")
return response.%JSONExport()
}
} Catch (ex) {
Do ##class(%REST.Impl).%SetStatusCode("400")
return ex.DisplayString()
}
}
Comme nous pouvons le voir, nous faisons appel à la BPL ImportBPL de manière asynchrone, afin d'éviter tout problème de dépassement de délai. Examinons la structure de production :
.png)
Ouvrons ImportBPL et voyons comment gérer l'importation des matches :
.png)
Nous créons d'abord un message indiquant l'état de l'importation, puis nous invoquons une opération métier qui sera chargée de supprimer les tableaux de stockage des données de match, une fois que l'importation aura été effectuée et confirmée. Le succès de la préparation des tableaux nous permet de passer à l'étape de l'exécution du scraping sur le web :
.png)
Comme vous voyez dans le flux de tâches, nous lancerons un appel asynchrone à l'opération métier QUINIELA.BO.ImportBO dans laquelle, à l'aide de Python, nous récupèrerons les informations sur les résultats historiques. Pour accélérer la récupération des données, nous avons divisé la récupération des résultats en deux tâches asynchrones, l'une pour la première division et l'autre pour la deuxième division, qui seront exécutées en parallèle.
Méthode de classe pour l'importation de données à l'aide de Python
Ensuite, nous allons analyser la méthode de classe qui est chargée d'effectuer le scraping sur le web.
ClassMethod ImportFromWeb(division As %String) As %String [ Language = python ]
{
from os import path
from pathlib import PurePath
import sys
from bs4 import BeautifulSoup
import requests
import iris
directory = '/shared/files/urls'+division+'.txt'
responses = 1
with open(directory.replace('\', '\\'), 'r') as fh:
urls = fh.readlines()
urls = [url.strip() for url in urls] # strip \n
for url in urls:
file_name = PurePath(url).name
file_path = path.join('.', file_name)
raw_html = ''
try:
response = requests.get(url)
if response.ok:
raw_html = response.text
html = BeautifulSoup(raw_html, 'html.parser')
for match in html.body.find_all('tr', 'jornadai'):
count = 0
matchObject = iris.cls('QUINIELA.Object.RawMatch')._New()
matchObject.Journey = match.get('data-jornada')
for specificMatch in match.children:
if specificMatch.name is not None and specificMatch.name == 'td' and len(specificMatch.contents) > 0:
match count:
case 0:
matchObject.Day = specificMatch.contents[0].text
case 1:
matchObject.LocalTeam = specificMatch.contents[0].text
case 2:
if specificMatch.div is not None and specificMatch.div.a is not None and specificMatch.div.a.contents is not None and len(specificMatch.div.a.contents) > 1:
matchObject.GoalsLocal = specificMatch.div.a.contents[0].text
matchObject.GoalsVisitor = specificMatch.div.a.contents[1].text
case 3:
matchObject.VisitorTeam = specificMatch.contents[0].text
case 5:
matchObject.Referee = specificMatch.contents[0].text
matchObject.Division = division
count = count + 1
if (matchObject.Day != '' and matchObject.GoalsLocal != '' and matchObject.GoalsVisitor != ''):
status = matchObject._Save()
except requests.exceptions.ConnectionError as exc:
print(exc)
return exc
return responses
}
- Importation des bibliothèques nécessaires request, BeautifulSoup et iris:
from bs4 import BeautifulSoup import requests
import iris
-
Invocation de l'URL et capture de sa réponse dans une variable :
response = requests.get(url) if response.ok:
raw_html = response.text html = BeautifulSoup(raw_html, 'html.parser') -
Analyse et extraction des données pertinentes de chaque match et création d'un objet type QUINIELA.Object.RawMatch qui sera stocké dans la base de données IRIS :
for match in html.body.find_all('tr', 'jornadai'):
count = 0 matchObject = iris.cls('QUINIELA.Object.RawMatch')._New() matchObject.Journey = match.get('data-jornada') for specificMatch in match.children:
if specificMatch.name is not None and specificMatch.name == 'td' and len(specificMatch.contents) > 0: match count: case 0: matchObject.Day = specificMatch.contents[0].text case 1: matchObject.LocalTeam = specificMatch.contents[0].text case 2: if specificMatch.div is not None and specificMatch.div.a is not None and specificMatch.div.a.contents is not None and len(specificMatch.div.a.contents) > 1: matchObject.GoalsLocal = specificMatch.div.a.contents[0].text matchObject.GoalsVisitor = specificMatch.div.a.contents[1].text case 3: matchObject.VisitorTeam = specificMatch.contents[0].text case 5: matchObject.Referee = specificMatch.contents[0].text matchObject.Division = division
count = count + 1 if (matchObject.Day != '' and matchObject.GoalsLocal != '' and matchObject.GoalsVisitor != ''): status = matchObject._Save()
Comme vous voyez, nous avons importé la bibliothèque IRIS Python qui nous permet d'utiliser les classes définies dans notre espace de noms, de telle sorte que nous pouvons remplir notre base de données directement depuis la méthode Python. Avec cette méthode simple, nous pouvons maintenant récupérer toutes les données dont nous avons besoin d'une manière simple et agile.
Cette fonctionnalité de "scraping sur le web" peut s'avérer très utile pour l'intégration de systèmes clos dans lesquels aucun autre moyen d'interconnexion n'est possible.
J'espère que cette fonctionnalité vous sera utile et si vous avez des questions, n'hésitez pas à écrire un commentaire.
Merci pour votre attention !