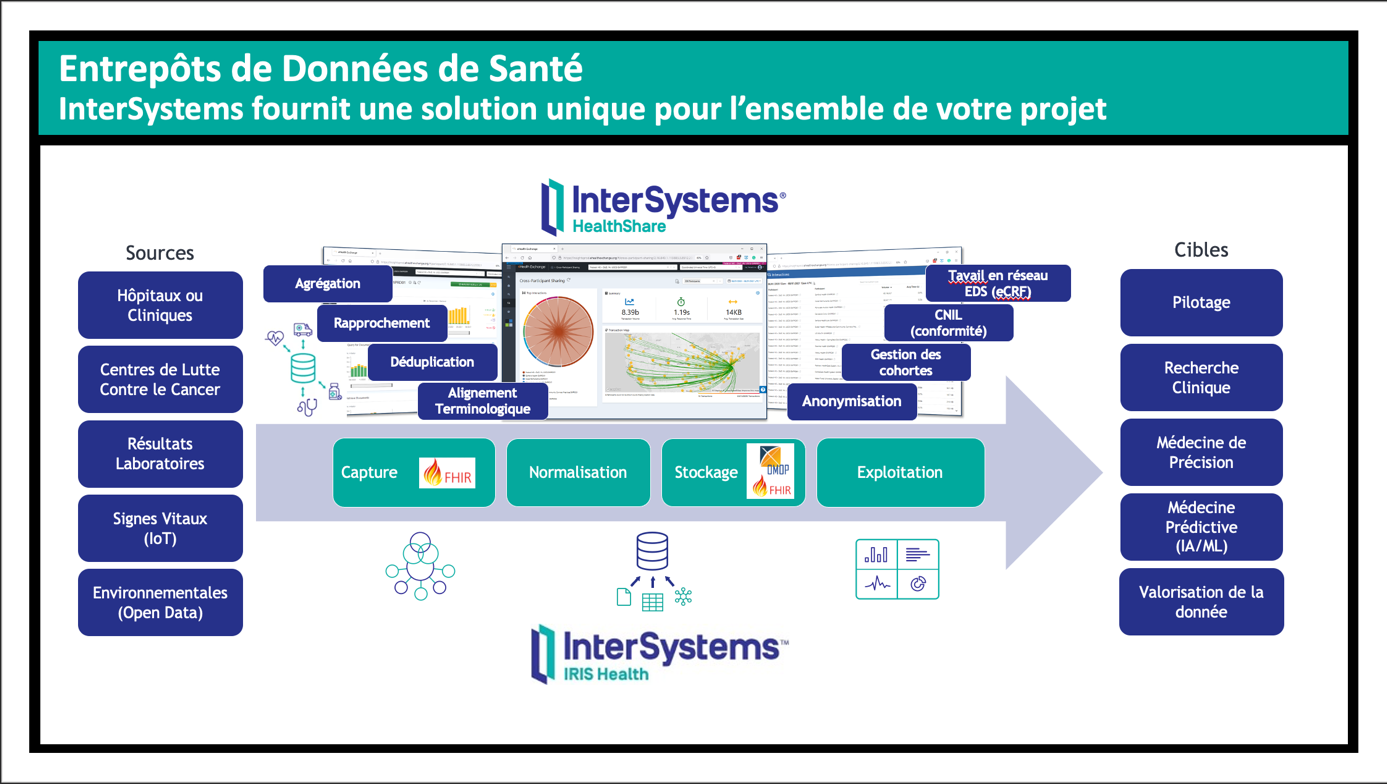
Les systèmes EHR (Electronic Health Record) sont modélisés dans un format/structure propriétaire et ne sont pas basés sur des modèles du marché tels que FHIR ou HL7. Certains de ces systèmes peuvent interopérer des données dans un format propriétaire pour FHIR et d'autres modèles de marché, mais pas tous. InterSystems dispose de deux plateformes capables d'interopérer des formats propriétaires pour ceux du marché : InterSystems HealthShare Connect et InterSystems IRIS for Health. La fonctionnalité de transformation (DTL - Data Transformation Language) de ces plateformes peut recevoir des données dans n'importe quel format, structure ou canal de communication (CSV, JSON, XML, et autres via FTP, File, HTTP, etc.) et les transformer directement en formats du marché (FHIR, CDA, HL7, etc.). Cependant, InterSystems dispose d'un format intermédiaire appelé SDA (Summary Document Architecture) qui est utilisé par ces plateformes pour générer sans effort des FHIR STU, R3, R4, HL7v2, HL7v3, etc. En outre, lorsqu'elles sont au format SDA, les données de santé peuvent être conservées dans le RCU HealthShare. Ainsi, le format propriétaire/personnel est d'abord transformé en SDA, puis les données peuvent être automatiquement converties dans n'importe quel format du marché, ainsi que sauvegardées dans HealthShare. Dans cet article, nous allons vous montrer comment transformer des données propriétaires/personnalisées en SDA à l'aide d'IRIS for Health. L'exemple de données que nous avons utilisé a été généré par le projet de génération de données en masse SYNTHEA (https://synthea.mitre.org/downloads). Nous allons convertir 1000 patients d'un fichier CSV en SDA, en utilisant les fonctions d'interopérabilité d'IRIS for Health.