Laboratoire pratique pour IntegratedML
Avez-vous essayé le laboratoire de la plate-forme d'apprentissage d'InterSystems pour IRIS IntegratedML ? Dans ce laboratoire, vous pouvez former et tester un modèle sur un ensemble de données de réadmission et être en mesure de prédire quand un patient sera réadmis ou non, ou de calculer sa probabilité d'être réadmis.
Vous pouvez l'essayer sans aucune installation sur votre système, tout ce que vous avez à faire est de démarrer un environnement de laboratoire virtuel (Zeppelin) et de jouer autour !
Dans cet article, nous utiliserons ce laboratoire pour vous présenter brièvement IntegratedML, le problème à traiter, la manière d'utiliser IntegratedML pour créer un modèle prévisionnel de réadmission, ainsi que quelques idées sur la manière d'analyser ses mesures de performance.
Qu'est-ce qu'IntegratedML ?

{kind=link}
Source: https://github.com/intersystems-community/integratedml-demo-template
Avant de commencer ce tutoriel, parlons brièvement d'IRIS IntegratedML. Cet outil vous permet d'effectuer des tâches d'apprentissage automatique (ML) directement dans des instructions SQL, en simplifiant l'implémentation de processus complexes tels que le choix des colonnes et des algorithmes ML les plus appropriés pour effectuer une classification ou une régression sur une colonne cible, par exemple.
Une autre excellente fonctionnalité d'IntegratedML est son déploiement facile. Une fois votre modèle formé et performant, il vous suffit d'exécuter des instructions SQL pour le mettre en production.
IntegratedML vous permet de choisir le fournisseur ML à utiliser. Le fournisseur par défaut est AutoML, une implémentation Python d'InterSystems utilisant la bibliothèque ML bien connue scikit-learn. Mais vous pouvez également choisir entre trois autres fournisseurs : PMML, H2O et DataRobot.
Dans cet article, nous allons utiliser le fournisseur AutoML.
Problème et solution
Présentons maintenant le problème et la manière dont nous pouvons nous y prendre pour proposer un moyen d'en minimiser les impacts. Nous allons essayer de réduire les problèmes liés aux réadmissions.
Selon Wikipedia, une réadmission à l'hôpital est un épisode au cours duquel un patient est autorisé à quitter l'hôpital (déchargé), mais cette personne revient (réadmet) à nouveau à l'hôpital dans un intervalle de temps court et inattendu.
![Infographie sur les réadmissions à l'hôpital][https://news.yale.edu/sites/default/files/styles/horizontal_image/public/d6_files/Hospital_v03_YNews.jpg]
{kind=link}
Les réadmissions entraînent des pertes de qualité de soins pour les patients - le temps écoulé entre la sortie et la réadmission peut être critique - ainsi qu'une optimisation des ressources hospitalières.
Une approche pour surmonter ce problème consiste à essayer d'utiliser une base de données historique pour créer un ensemble de données dans lequel les épisodes de réadmission passés pourraient être analysés par des algorithmes d'apprentissage automatique, créant ainsi un modèle ML. Si l'ensemble de données est suffisamment riche et propre, les schémas de réadmission pourraient être correctement détectés et la probabilité de nouveaux épisodes pourrait être calculée par ce modèle.
Ainsi, la possibilité d'éviter les décharges erronées en utilisant un modèle ML pour prédire les réadmissions sera certainement une option précieuse pour les hôpitaux afin d'augmenter la qualité et le profit de leurs services.
Création et utilisation d'un modèle ML à l'aide de IntegratedML
Création du modèle
La création d'un modèle ML à l'aide d'IntegratedML est aussi simple que l'exécution d'une simple instruction SQL. Il vous suffit de définir l'ensemble de données historiques où se trouvent les données et de désigner votre modèle par un nom :
CREATE MODEL Readmission PREDICTING (MxWillReAdmit) FROM EncountersHistory
Après cette instruction, vous avez déclaré et créé un modèle appelé Readmission destiné à prédire les valeurs d'une colonne appelée MxWillReAdmit, sur la base d'un ensemble de données appelé EncountersHistory.
Vous pouvez trouver plus d'informations sur cette instruction ici. Par exemple, dans la phase de conception, il est pratique de forcer les mêmes résultats à la formation, donc vous pouvez utiliser l'argument USING avec un nombre constant arbitraire, comme suit :
CREATE MODEL Readmission PREDICTING (MxWillReAdmit) FROM EncountersHistory USING {"seed": 3}
Formation de modèle
Votre modèle est maintenant prêt à être formé, en utilisant l'instruction TRAIN MODEL (former le modèle) :
TRAIN MODEL Readmission
Ici, IntegratedML fait une bonne partie du travail pour vous (en utilisant le fournisseur de ML " AutoML") :
- L'ingénierie des fonctionnalités: quelles colonnes utiliser ?
- Codage de données: comment les données dans les colonnes choisies doivent être présentées aux algorithmes de ML
- Sélection de l'algorithme ML: quel algorithme permet d'obtenir les meilleurs résultats ?
- Sélection du modèle: en fonction du type de données de la colonne cible, un modèle de classification ou un modèle de régression doit être sélectionné. Dans cet exemple, un modèle de classification sera sélectionné lorsque la colonne cible contient des valeurs booléennes.
Cette déclaration peut prendre un certain temps, en fonction de la taille de l'ensemble de données et de la complexité de vos données.
Validation du modèle
A présent, nous devrions être impatients de connaître la qualité réelle de notre modèle. La méthode ML intégrée (Integrated ML) propose une déclaration pour le calcul des mesures de performance, sur la base d'un ensemble de données différent de celui utilisé pour la formation - sinon, vous ne seriez pas juste avec vous-même, n'est-ce pas ? :)
Ce nouvel ensemble de données est appelé ensemble de données de test ou de validation, selon la stratégie utilisée pour la validation. Cet ensemble de données est généralement extrait du même ensemble de données que celui utilisé pour la création de l'ensemble de données de formation. Une approche courante consiste à sélectionner au hasard 70 ou 80 % de l'ensemble de données pour la formation et à laisser le reste pour le test/la validation.
Dans le laboratoire, un nouvel ensemble de données prêt à l'emploi a été préparé pour cette tâche : l'ensemble de données EncountersNew.
Nous pouvons maintenant déterminer la qualité (ou la médiocrité) de notre modèle :
VALIDATE MODEL Readmission FROM EncountersNew
Pour obtenir les résultats, vous devez interroger le tableau INFORMATION_SCHEMA.ML_VALIDATION_METRICS :
SELECT * FROM INFORMATION_SCHEMA.ML_VALIDATION_METRICS
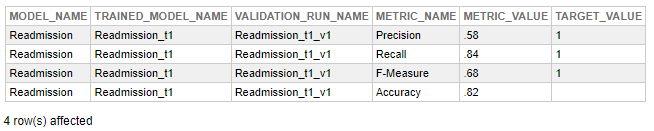
La performance du modèle est mesurée en quatre mesures par IntegratedML:
- Précision : taux de prédictions correctes (des valeurs proches de 1 signifient des taux élevés de réponses correctes).
- Précision : taux de prédictions positives correctes concernant toutes les prédictions positives faites par le modèle (des valeurs proches de 1 signifient un petit nombre de prédictions faussement positives).
- Rappel : taux de prédictions positives correctes concernant toutes les valeurs positives réelles dans l'ensemble de données (des valeurs proches de 1 signifient un petit nombre de prédictions faussement négatives).
- Mesure F : une autre façon de mesurer la précision, utilisée lorsque la précision n'est pas satisfaisante, généralement pour les problèmes de déséquilibre (des valeurs proches de 1 signifient un taux élevé de réponses correctes).
Discussion sur les mesures de performance
Ici, nous pouvons voir que le modèle a une précision de 82%. Mais cette mesure ne doit pas être analysée seule, d'autres mesures telles que la précision et le rappel doivent également être évaluées.
Réfléchissons aux implications des prédictions erronées - faux positifs et faux négatifs. Pour notre modèle, un faux positif signifie qu'une réadmission prévue n'était pas une réadmission réelle. En revanche, un faux négatif signifie qu'un patient a été réadmis et que le modèle a prédit qu'il ne le serait pas.
Dans les deux cas, des décisions erronées pourraient être prises. Une prédiction faussement positive pourrait conduire à la décision de garder un patient à l'hôpital plus longtemps que nécessaire, tandis qu'une prédiction faussement négative pourrait conduire à la décision de faire sortir un patient prématurément, et de le réadmettre ensuite.
Il est à noter que, dans notre modèle, un faux négatif conduit à des cas de réadmission, ce que nous essayons d'éviter. Il faut donc choisir des modèles qui diminuent le nombre de faux négatifs, même si le nombre de faux positifs augmente.
Ainsi, pour choisir des modèles avec de faibles taux de faux négatifs, nous devons choisir des modèles avec des taux de rappel élevés. En effet, plus le taux de rappel est élevé, moins le taux de faux négatifs est important.
Comme notre modèle a un taux de rappel de 84 %, considérons qu'il s'agit d'une valeur raisonnable pour l'instant.
Faire des prédictions
Une fois que votre modèle a été entraîné et que ses performances sont acceptables, vous pouvez maintenant l'exécuter afin de prédire les résultats.
Vous devez utiliser la fonction PREDICT afin d'utiliser un modèle pour effectuer des prédictions :
SELECT TOP 100
ID,
PREDICT(Readmission) AS PredictedReadmission,
MxWillReAdmit AS ActualReadmission
FROM
EncountersNew
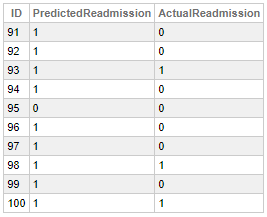
Cette fonction évalue la probabilité que la colonne cible du modèle d'une ligne soit une valeur vraie ou fausse, sur la base d'un seuil interne.
Vous pouvez constater que notre modèle a fait des prévisions erronées, ce qui est normal.
La fonction de probabilité PROBABILITY est une autre fonction qui peut être utilisée pour faire des prédictions.
SELECT TOP 10
ID,
PROBABILITY(Readmission FOR '1') AS ReadmissionProbability,
PREDICT(Readmission) AS PredictedReadmission,
MxWillReAdmit AS ActualReadmission
FROM
EncountersNew
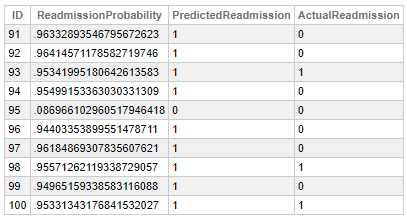
De la même manière que PREDICTION, PROBABILITY utilise les colonnes d'une ligne comme entrée pour le modèle spécifié, mais ici nous devons définir dans quelle classe nous voulons calculer la probabilité.
Cette fonction peut s'avérer utile si l'on souhaite personnaliser le seuil utilisé pour effectuer les prédictions.
Requête de modèles formés
Après avoir créé et formé vos modèles, vous pouvez les requérir à l'aide du tableau INFORMATION_SCHEMA.ML_TRAINED_MODELS, comme suit :
SELECT * FROM INFORMATION_SCHEMA.ML_TRAINED_MODELS

Conclusion
Dans cet article, nous avons créé, formé, validé et fait des prédictions sur un ensemble de données historiques de réadmission de patients. Ces prédictions pourraient être utilisées comme un outil supplémentaire dans la recherche de meilleures décisions qui pourraient améliorer les soins aux patients et réduire les coûts des services hospitaliers. Toutes ces étapes ont été réalisées en utilisant le bon vieux langage SQL grâce à InterSystems IntegratedML, qui met la puissance de l'apprentissage automatique à la portée d'un grand nombre de développeurs.