Le tutoriel récemment publié « Introduction à InterSystems Data Studio » m’a donné envie de découvrir ce produit. Et je trouve que c’est une approche intéressante pour la gestion d’un data fabric, sans avoir à plonger dans du code complexe. Il permet de connecter des silos de données hétérogènes, de transformer les données via des pipelines automatisés, puis de les charger dans un environnement unifié pour l’analyse.
J’ai donc décidé d’écrire un exemple montrant comment l’utiliser. En pratique, je vais parcourir le tutoriel avec vous au cas où vous n’auriez pas le temps de le faire vous-même. Même si je recommande fortement de suivre directement le tutoriel, car il contient beaucoup d’informations utiles.
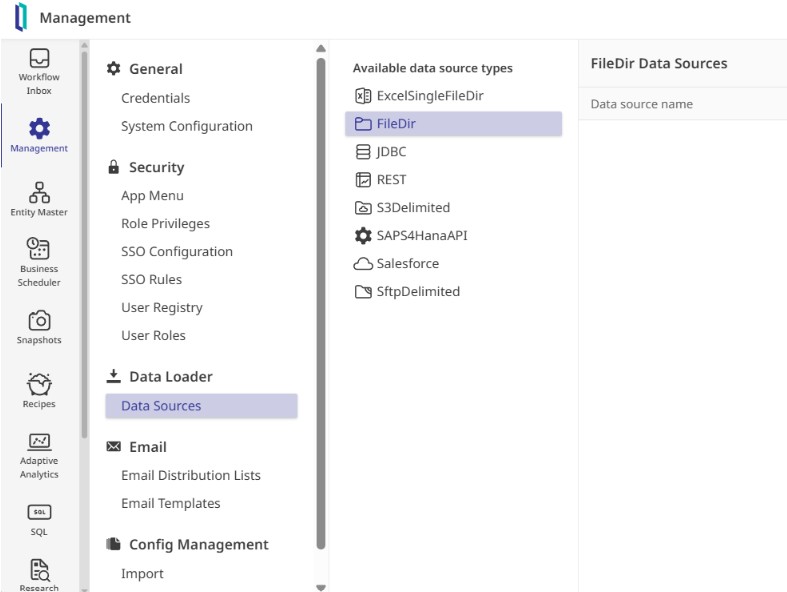
Pour comprendre son fonctionnement, je me suis mis dans la peau d’un administrateur système, en me connectant avec les identifiants fournis afin d’explorer l’interface. L’organisation de l’outil repose sur quelques piliers essentiels : définir les sources de données, cataloguer leur structure et construire des « recettes » automatisées pour les transférer vers un environnement de production.
Et la toute première étape consiste à établir une connexion avec mes données.
.png)

.png)

