Salut la Communauté!
J'ai une annonce excitante à partager avec vous ! Nous avons décidé d'essayer quelque chose de nouveau et de révolutionnaire 😉 Nous espérons que vous l'apprécierez. Et cela a quelque chose à voir avec l'IA 😊

L'intelligence artificielle (IA) est la simulation des processus d'intelligence humaine par des machines, notamment des systèmes informatiques. Ces processus comprennent l'apprentissage (l'acquisition d'informations et de règles pour utiliser ces informations), le raisonnement (l'utilisation de règles pour parvenir à des conclusions approximatives ou définitives) et l'autocorrection.
Salut la Communauté!
J'ai une annonce excitante à partager avec vous ! Nous avons décidé d'essayer quelque chose de nouveau et de révolutionnaire 😉 Nous espérons que vous l'apprécierez. Et cela a quelque chose à voir avec l'IA 😊
.png)
FHIR a transformé le secteur des soins de santé en fournissant un modèle de données normalisé pour la création d'applications de soins de santé et en favorisant l'échange de données entre les différents systèmes de soins de santé. La norme FHIR est basée sur des approches modernes axées sur les API, ce qui la rend plus accessible aux développeurs mobiles et web. Cependant, l'interaction avec les API FHIR peut encore s'avérer difficile, en particulier lorsqu'il s'agit de requêter des données à l'aide du langage naturel.
Titre: Microsoft présente PHI-1, un modèle de génération de code plus léger et plus performant que GPT-3.5, attribuant cette performance à la puissance des données de haute qualité
Résumé: Microsoft a récemment dévoilé PHI-1, un modèle de génération de code révolutionnaire qui surpasse les performances de GPT-3.5 tout en étant plus léger. La clé de cette performance réside dans l'utilisation de données de haute qualité, qui alimentent l'algorithme avec des informations précieuses et pertinentes. Microsoft affirme que PHI-1 représente une avancée significative dans le domaine de l'intelligence artificielle, offrant des résultats impressionnants en termes de génération de code. Cette nouvelle percée promet de faciliter le développement logiciel et d'améliorer l'efficacité des tâches de programmation.
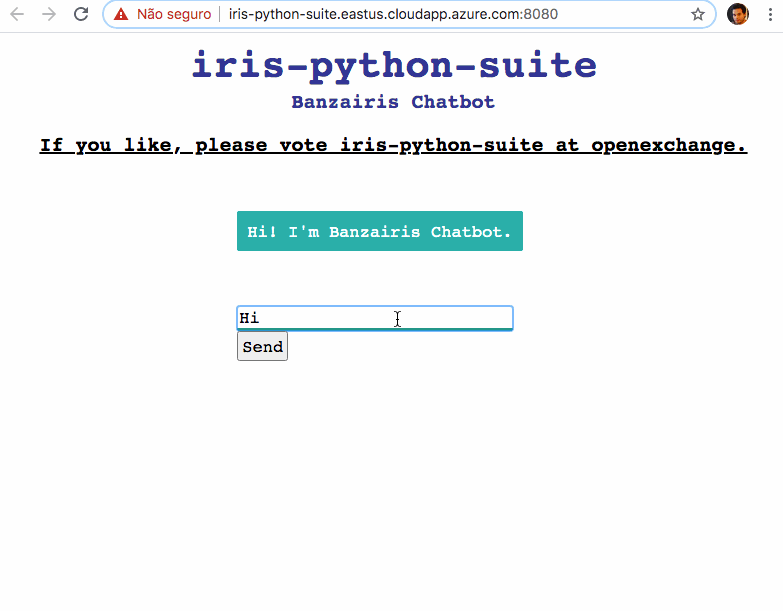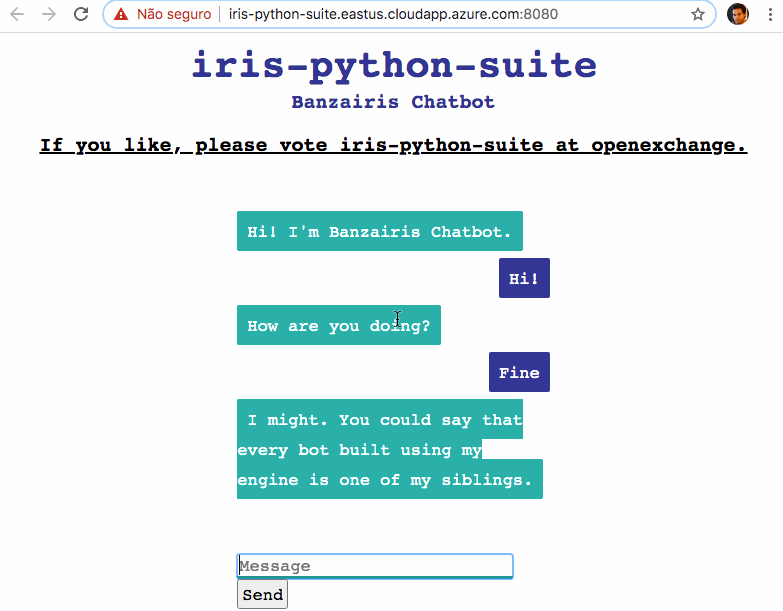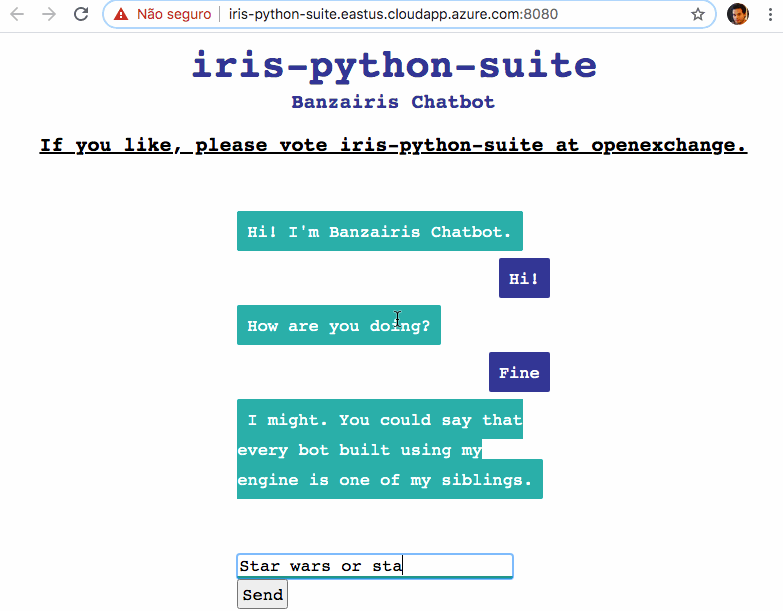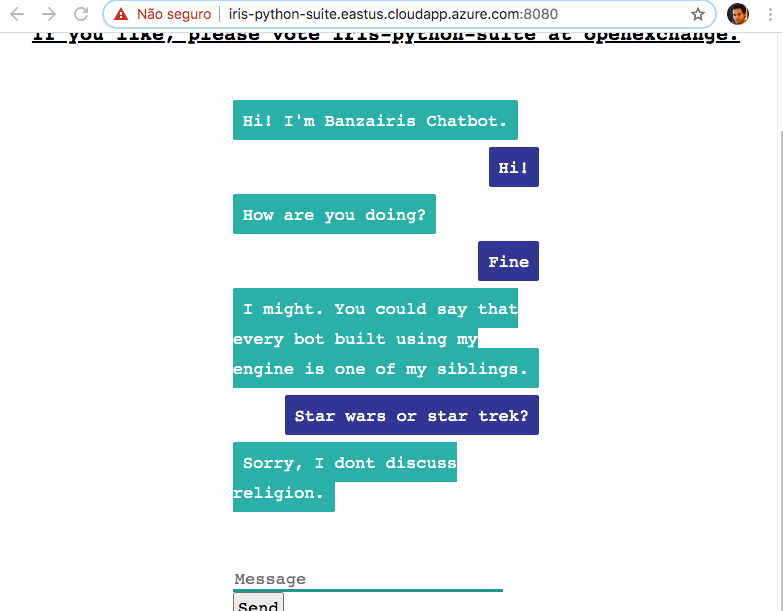
Dans cet article, je vais montrer comment intégrer la base de données IRIS d'InterSystems avec Python pour servir un Modèle d'apprentissage automatique du traitement du langage naturel (NLP).
Avec une large adoption et utilisation dans le monde, Python a une grande communauté et un grand nombre d'accélérateurs et de bibliothèques pour déployer n'importe quel type d'application. Vous pouvez également consulter : https://www.python.org/about/apps/ pour en savoir plus.
This is the third post of a series explaining how to create an end-to-end Machine Learning system.Cet article est le troisième article d'une série expliquant comment créer un système d'apprentissage automatique de bout en bout.
Lorsque vous travaillez avec l'apprentissage automatique, il est fréquent d'entendre ce terme : formation. Que signifie la formation dans un pipeline ML ?
Voici mon introduction à une série d'articles expliquant comment créer un système d'apprentissage automatique de bout en bout.
Notre communauté de développement d'IRIS a plusieurs messages sans balise ou mal balisés. Au fur et à mesure que le nombre de messages augmente, l'organisation de chaque balise et l'expérience d'un membre de la communauté qui parcourt les sujets tendent à diminuer.
Suite à la partie précédente, il est temps de tirer parti de l'instruction de VALIDATION DU MODÈLE IntegratedML, qui fournit des informations permettant de surveiller vos modèles ML. Vous pouvez la voir en action ici
Le code présenté ici est dérivé d'exemples fournis par le modèle InterSystems IntegratedML ou la documentation IRIS, documentation
Remarque: Le code présenté ici n'a qu'une valeur explicative. Si vous souhaitez l'essayer, j'ai développé une application modèle - iris-integratedml-monitor-example, qui participe au concours IA d'InterSystems IRIS (InterSystems IRIS AI Contest).
Il y a quelques mois, j'ai lu cet article intéressant de la MIT Technology Review, qui explique comment la pandémie de COVID-19 pose des défis aux équipes informatiques du monde entier en ce qui concerne leurs systèmes d'apprentissage automatique (ML).
Cet article m'a incité à réfléchir à la manière de traiter les problèmes de performance après le déploiement d'un modèle de ML.
Sur GitHub, vous trouverez toutes les informations sur l'utilisation d'un modèle d'apprentissage automatique "HuggingFace" / modèle d'IA sur le cadre IRIS à l'aide de Python.

Utilisation de modèles d'apprentissage automatique dans IRIS à l'aide de Python ; pour les modèles texte-texte, texte-image ou image-image.
Les modèles suivants servent d'exemple :
Keywords: IRIS, IntegratedML, apprentissage automatique, Covid-19, Kaggle
J'ai récemment remarqué un jeu de données Kaggle permettant de prédire si un patient Covid-19 sera admis en soins intensifs. Il s'agit d'un tableur de 1925 enregistrements comprenant 231 colonnes de signes vitaux et d'observations, la dernière colonne " USI " valant 1 pour Oui ou 0 pour Non.
Ce jeu de données représente un bon exemple de ce que l'on appelle une tâche "traditionnelle de ML". Les données semblent avoir une quantité suffisante et une qualité relativement bonne.
Salut les développeurs,
Nous aimerions vous inviter à participer à notre prochain concours dédié à la création des solutions d'IA/ML qui utilisent Cloud SQL pour travailler avec les données :
🏆 Concours InterSystems IRIS Cloud SQL et IntegratedML 🏆
Durée: du 3 avril au 23 avril 2023
Prix: $13,500!

Keywords: IRIS, IntegratedML, Flask, FastAPI, Tensorflow servant, HAProxy, Docker, Covid-19
Nous avons abordé quelques démonstrations rapides d'apprentissage profond et d'apprentissage automatique au cours des derniers mois, notamment un simple classificateur d'images radiographiques Covid-19 et un classificateur de résultats de laboratoire Covid-19 pour les admissions possibles en soins intensifs. Nous avons également évoqué une implémentation de démonstration IntegratedML du classificateur ICU. Alors que la randonnée de la "science des données" se poursuit, le moment est peut-être venu d'essayer de déployer des services d'IA du point de vue de "l'ingénierie des données" - pourrions-nous regrouper tout ce que nous avons abordé jusqu'à présent dans un ensemble d'API de services ? Quels sont les outils, les composants et l'infrastructure communs que nous pourrions exploiter pour réaliser une telle pile de services dans son approche la plus simple possible ?
La semaine dernière, nous avons annoncé la Plate-forme de données InterSystems IRIS, notre nouvelle plate-forme complète pour toutes vos activités liées aux données, qu'elles soient transactionnelles, analytiques ou les deux. Nous avons inclus un grand nombre des fonctionnalités que nos clients connaissent et apprécient de Caché et Ensemble, mais dans cet article, nous allons mettre un peu plus en lumière l'une des nouvelles capacités de la plate-forme : SQL Sharding, une nouvelle fonctionnalité puissante dans notre histoire de scalability.