Comment utiliser l'apprentissage automatique pour organiser la communauté - 3
This is the third post of a series explaining how to create an end-to-end Machine Learning system.Cet article est le troisième article d'une série expliquant comment créer un système d'apprentissage automatique de bout en bout.
Formation d'un modèle d'apprentissage automatique
Lorsque vous travaillez avec l'apprentissage automatique, il est fréquent d'entendre ce terme : formation. Que signifie la formation dans un pipeline ML ? La formation peut désigner l'ensemble du processus de développement d'un modèle d'apprentissage automatique OU le point spécifique du processus de développement qui utilise les données de formation et aboutit à un modèle d'apprentissage automatique.

Les modèles d'apprentissage automatique ne sont donc pas équivalents aux applications communes ?
Le dernier point ressemble à une application normale. Mais le concept est très différent, car dans une application courante, nous n'utilisons pas les données de la même manière. Tout d'abord, pour créer des modèles de ML, vous aurez besoin de données réelles (de production) dans tout le processus de développement. Une autre différence est que si vous utilisez des données différentes, vous aurez un modèle différent... toujours...
Pouvez-vous donner quelques exemples ?
Bien sûr ! Imaginez que vous êtes un développeur de systèmes et que vous créez un système qui contrôle les services dans un PetShop. La façon la plus simple
de ce type de système est de créer une base de données pour stocker les données et de créer une application pour interagir avec l'utilisateur. Lorsque vous développez,
vous n'avez pas besoin de données réelles. Vous pouvez créer tout le système avec de fausses données. C'est impossible avec les modèles d'apprentissage automatique
Ils ont besoin de données réelles au début du développement et elles seront utilisées jusqu'à la fin du développement.
Lorsque vous créez un modèle d'apprentissage automatique, vous fournissez des données à un algorithme
et l'algorithme produit une application adaptée à ces données. Si vous utilisez de fausses données, vous obtiendrez un faux modèle.
Qu'en est-il de l'initiative d'organisation de la communauté avec le ML ?
Revenons au sujet principal. Avec tous les articles que je possède, j'ai commencé à explorer un échantillon et j'ai trouvé le suivant :
- La plupart des articles n'ont pas été balisés.
- Certains articles étaient mal balisés
- Certains articles (de l'échantillon) avec des balises étaient balisés correctement.
Comment utiliser ces données ?
J'ai décidé de créer un sac de mots (BoW) à partir des données et d'utiliser les algorithmes de classification les plus courants.
Comment puis-je caractériser ces données ? Ma brève tentative ici :
1ère tentative - Formation avec uniquement des données de publication
Prenez toutes les données avec les balises, séparez 80 % pour la formation et 20 % pour la validation du modèle. Le modèle obtenu n'est pas très performant. La plupart du temps, il prédisait que tous les textes étaient à propos de Caché... (le BoW comportait environ 15000 caractéristiques).
2ème tentative - Formation avec les données de publication uniquement, en supprimant les mots vides.
La plupart des messages contiennent les mêmes mots : hi, for, to, why, in, on, the, do, don't... Le modèle a probablement pris une mauvaise direction pour prédire les balises. J'ai donc supprimé tous les mots vides et vectorisé les données, ce qui a permis d'obtenir environ 9000 caractéristiques. Mais le modèle n'est toujours pas performant.
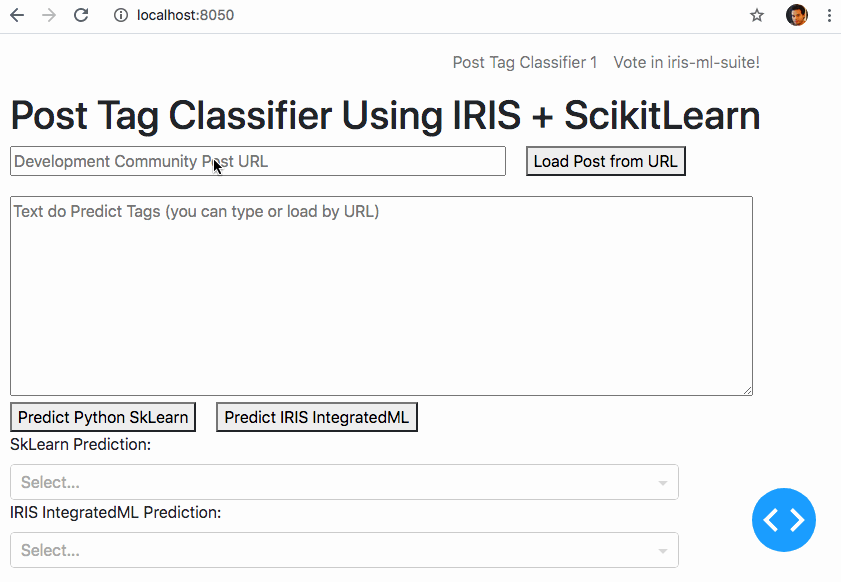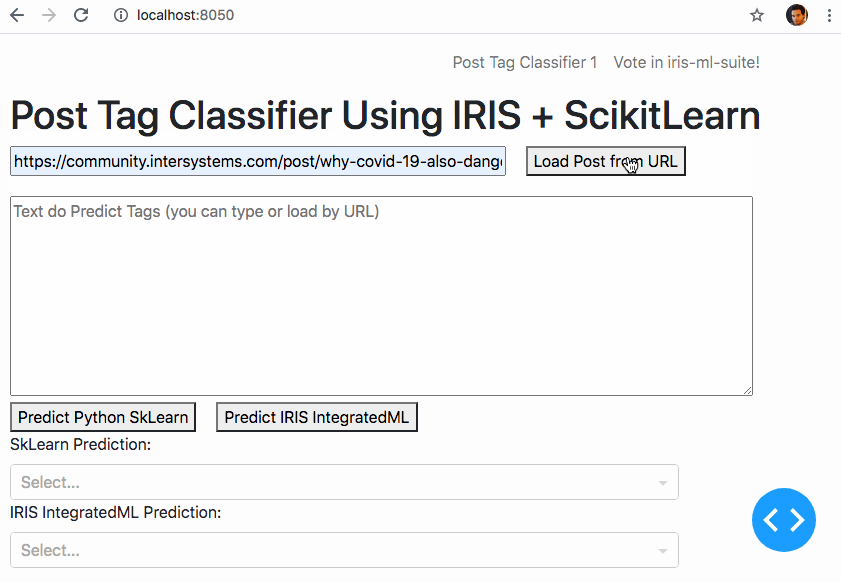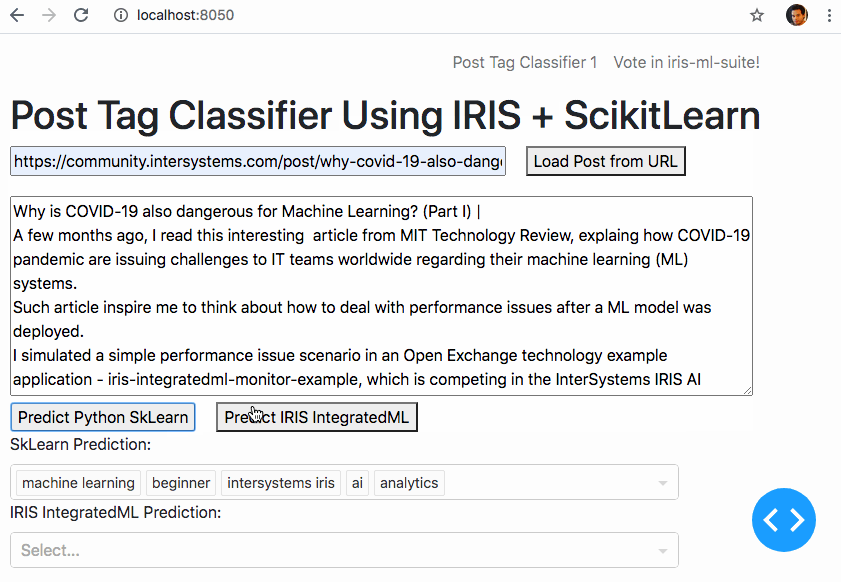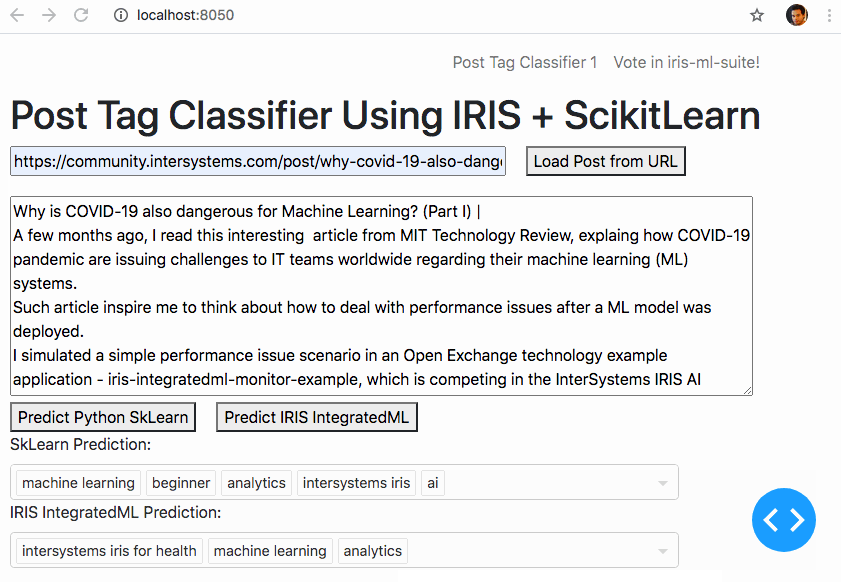
3ème tentative - Entraînement à la description des balises
En regardant le tableau des balises, je vois une courte description de chaque balise. J'ai donc donné la chance à ces petites phrases d'être mon guide sur la bonne façon de baliser comme dans la vie réelle. J'ai obtenu environ 1500 caractéristiques et en les utilisant, le modèle commence à être suffisamment performant pour être montré à d'autres personnes =)
4ème tentative - Entraînement avec description des balises
Après toutes ces recherches, j'ai décidé de tester si IntegratedML pouvait être plus performant que mon modèle. J'ai donc converti le dernier sac de mots en tableau,
mais j'ai été confronté à un problème : un sac de mots avec 1500 caractéristiques signifie que j'ai besoin d'un tableau avec 1500 colonnes.
Et en lisant la documentation d'IRIS, la limite de colonnes était de 1000. J'ai donc modifié mon vectoriseur pour n'utiliser que 900 caractéristiques.
C'est moins, mais c'est la seule solution que j'ai trouvée.
Les algorithmes de classification
J'ai essayé 3 algorithmes avec des paramètres différents :
- SVM
- Forêt aléatoire
- Régression logistique
La meilleure performance (du moins ces derniers jours) a été la régression logistique dans une stratégie Un contre le Reste (One vs Rest).
One vs Rest considère que vous avez 1 classe à prédire contre plus ou moins 1 classe restante.
Article suivant : Application de bout en bout
J'espère que vous appréciez. Si vous aimez le texte et mon application, votez sur https://openexchange.intersystems.com/contest/current dans mon application iris-ml-suite
Training a Machine Learning Model
When you work with machine learning is common to hear this work: training. Do you what training mean in a ML Pipeline? Training could mean all the development process of a machine learning model OR the specific point in all development process that uses training data and results in a machine learning model.
So Machine Learning Models are not equal Common Applications?
In the very last point it looks like a normal application. But the concept is pretty different, because in a common application we don't use data in the same way. First of all, to create ML Models you will need real (production) data at all development process another difference is if you use different data you will have a different model..always...
Can you give some examples?
Sure! Imagine you are a system developer and create a system that controls services in a PetShop. The most simple way to do this kind of system is create a DataBase do store data and create an application to interact with the user. When you start develop it you don't need real data. You can create all system with fake data. This is impossible with machine learning models they need real data at the starting point of development and it will be used until the last point of development. When you create a machine learning model you provide data to an algorithm and the algorithm results in an application fitted to those data, so if you use fake data, you will have a fake model.
What about Organize the Community with ML?
Getting back to the main subject. With all posts that I have I started exploring a sample and realize:
- Most post were without any tag
- Some posts were with wrong tags
- Some posts (from sample) with tags were right tagged
How use this data?
I take the option of create a BoW (Bag of Words) of the data and use the most popular classification algorithms with. How do I featurize those data? My brief of attempts here:
1st Attempt - Training with only post data
Take all the data with tags, separate 80% for training and 20% to validate the model. The resulting model didn't perform well. Most of time it was predicting all text were about Caché... (the BoW was with aroun 15000 features)
2nd Attempt - Training with only post data removing stop words
Thinking of most posts has the same words like: hi, for, to, why, in, on, the, do, don't... the model probably was taking the wrong way to predict the tags. So I removed all stop words and vectorized the data, resulting in around 9000 features. But the model continues to not perform well.
3rd Attempt - Training with Tags Description
Looking at tags table, I see a short description of each tag. So I give the chance to that small phrases be my guide to the right way to tagging like in real life. It resulted in about 1500 features and using it the model starts performing well enough to show to other people =)
4th Attempt - Training with Tags Description
After all this quest I decide to test if IntegratedML could perform better than my model. So I converted the last Bag of Words into a Table but I faced a problem: a bag of words with 1500 features means that I need a table with 1500 columns. And reading the IRIS docs the limit of columns was 1000. So I changed my vectorizer to use only 900 features. It would less but was the only way that I could think.
Classification Algorithms
I tried 3 algorithms with different params:
- SVM
- Random Forest
- Logistic Regression
The best performer (at least in last days) was Logistic Regression in a strategy One vs Rest. One vs Rest consider that you have 1 class to predict versus a more than 1 other classes.
Next article: End-to-End Application
I hope you are enjoying. If you like the text and my application, please vote on https://openexchange.intersystems.com/contest/current in my application iris-ml-suite