Comment utiliser l'apprentissage automatique pour organiser la communauté - 1
Voici mon introduction à une série d'articles expliquant comment créer un système d'apprentissage automatique de bout en bout.
Un seul problème pour commencer
Notre communauté de développement d'IRIS a plusieurs messages sans balise ou mal balisés. Au fur et à mesure que le nombre de messages augmente, l'organisation de chaque balise et l'expérience d'un membre de la communauté qui parcourt les sujets tendent à diminuer.
Les premières solutions envisagées
Nous pouvons envisager quelques solutions habituelles pour ce scénario, comme par exemple :
- Prendre un volontaire pour lire tous les messages et corriger les erreurs.
- Payer un entrepreneur pour corriger toutes les erreurs.
- Envoyez un courriel à chaque auteur de message pour qu'il revoie les textes du passé.
Ma solution
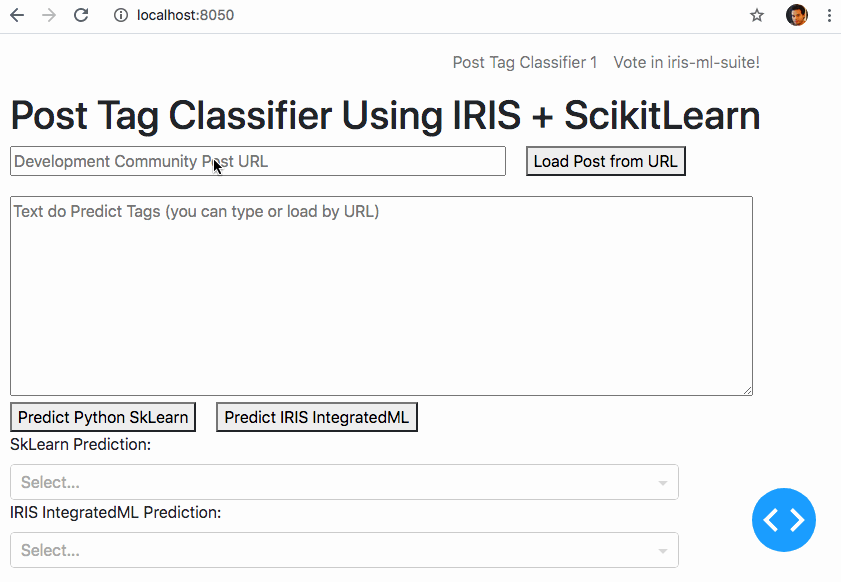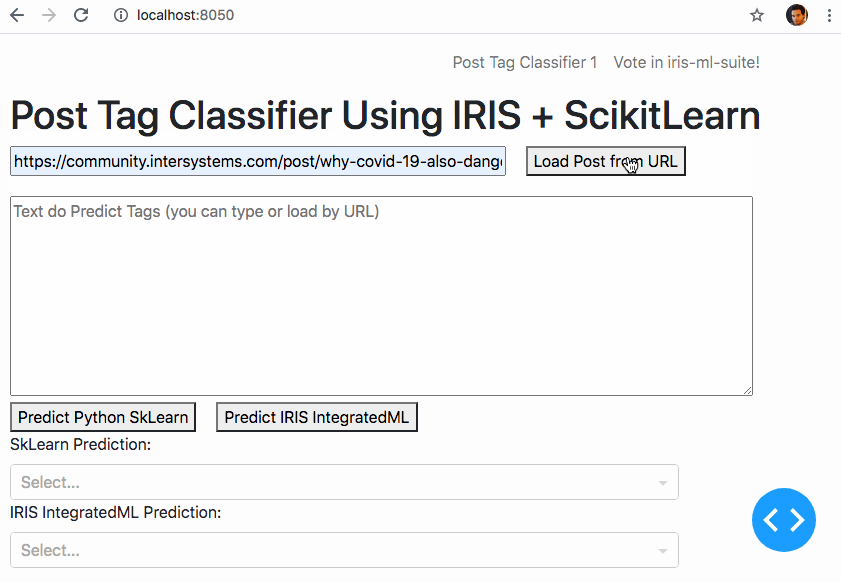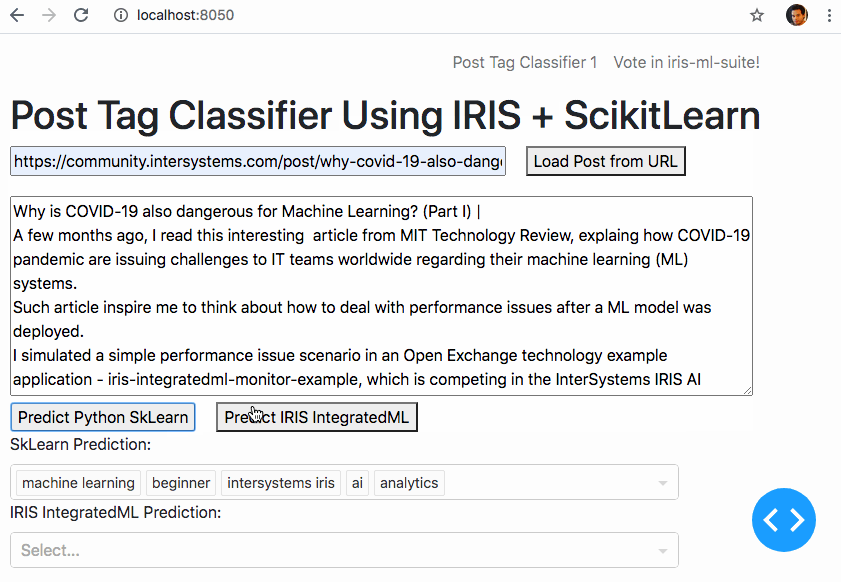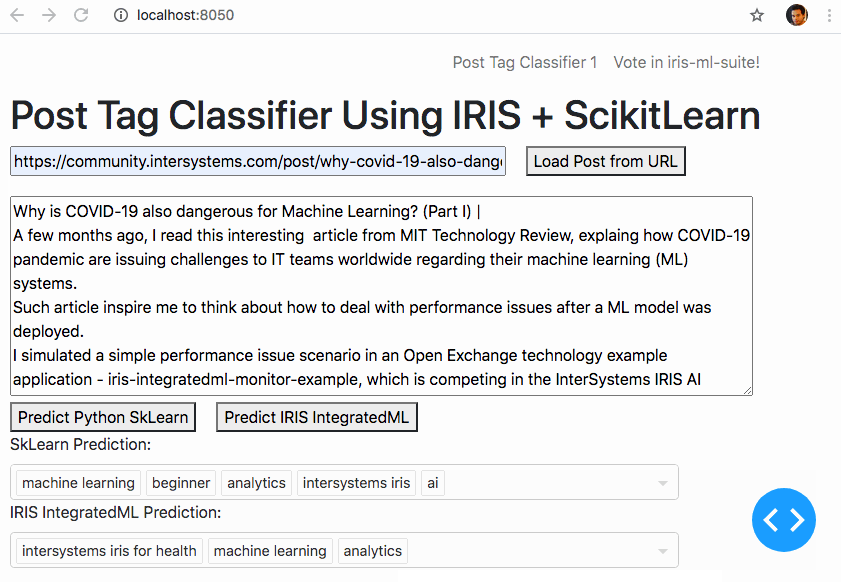
Et si nous pouvions apprendre à une machine à faire ce travail ?
 Nous avons beaucoup d'exemples de dessins animés, d'anime ou de films pour nous rappeler ce qui peut se passer lorsqu'on enseigne à une machine...
Nous avons beaucoup d'exemples de dessins animés, d'anime ou de films pour nous rappeler ce qui peut se passer lorsqu'on enseigne à une machine...
Apprentissage automatique
L'apprentissage automatique est un sujet très vaste et je vais faire de mon mieux pour expliquer ma vision du sujet. Revenons au problème que nous devons encore résoudre : Si l'on examine les solutions habituelles, elles prennent toutes en compte l'interprétation d'un texte. Comment apprendre à une machine à lire un texte, à comprendre la corrélation entre un texte et une balise ? Tout d'abord, nous devons explorer les données et en tirer des conclusions.
Classification ? Régression ?
Lorsque vous commencez à étudier l'apprentissage automatique, les deux termes ci-dessus sont toujours utilisés. Mais comment savoir ce qu'il faut approfondir ?
-Classification : Un algorithme d'apprentissage automatique de classification prédit des valeurs discrètes.
-Régression : Un algorithme d'apprentissage automatique de régression prédit des valeurs continues.
Si l'on considère notre problème, nous devons prédire des valeurs discrètes (toutes les baises existent).
C'est une question de données !
Toutes les données relatives aux articles ont été fournies ici.
Article
SELECT
id, Name, Tags, Text
FROM Community.Post
Where
not text is null
order by id
| id | Nom | Balises | Texte |
|---|---|---|---|
| 1946 | Introduction aux services web | Web Development,Web Services | Cette vidéo est une introduction aux services web. Elle explique ce que sont les services web, leur utilisation et comment les administrer. Les services web sont également connus sous le nom de "SOAP". Cette session comprend des informations sur la sécurité et la politique de sécurité. |
| 1951 | Les outils pour Caché | Caché | Cette astuce technique (Tech Tip) passe en revue les différents outils disponibles à partir du Caché dans la barre d'état système de Windows. Vous verrez comment accéder à Studio IDE, au terminal, au portail de gestion du système, à SQL, aux globales, à la documentation, à la référence de classe et à l'accès au système à distance. |
| 1956 | Démarrage avec Caché | Caché | Démarrage avec Caché présentera Caché et son architecture. Nous examinerons également les outils de développement, la documentation et les exemples disponibles. |
Balises
| ID | Description |
|---|---|
| .NET | NET Framework (prononcé dot net) est un cadre logiciel développé par Microsoft qui fonctionne principalement sur Microsoft Windows. Site officiel. Support .NET dans InterSystems Data Platform. |
| .NET Experience | InterSystems .NET Experience révèle les possibilités d'interopérabilité entre .NET et InterSystems IRIS Data Platform. Pour plus de détails, cliquez ici. Site officiel de .NET |
| IA | L'intelligence artificielle (IA) est la simulation des processus de l'intelligence humaine par des machines, en particulier par des systèmes informatiques. Ces processus comprennent l'apprentissage (l'acquisition d'informations et de règles d'utilisation de ces informations), le raisonnement (l'utilisation de règles pour parvenir à des conclusions approximatives ou définitives) et l'autocorrection. Apprenez-en plus. |
| API | L'interface de programmation d'applications (API) est un ensemble de définitions de sous-programmes, de protocoles et d'outils permettant de créer des logiciels d'application. En termes généraux, il s'agit d'un ensemble de méthodes de communication clairement définies entre divers composants logiciels. Apprenez-en plus. |
Nous savons maintenant à quoi ressemblent les données. Mais il ne suffit pas de connaître la conception des données pour créer un modèle d'apprentissage automatique.
Qu'est-ce qu'un modèle d'apprentissage automatique ?
Un modèle d'apprentissage automatique est une combinaison d'un algorithme d'apprentissage automatique et de données. Après avoir combiné une technique avec des données un modèle peut commencer à prédire.
Exactitude
Si vous pensez que les modèles ML ne font jamais d'erreurs, vous devriez mieux comprendre la précision du modèle. En quelques mots, la précision correspond aux performances du modèle en matière de prédiction. En général, la précision est exprimée en pourcentage, sous forme de chiffres. Ainsi, quelqu'un dira : "J'ai créé un modèle dont la précision est de 70 %". Cela signifie que pour 70 % des prédictions, le modèle prédit correctement. Les 30 % restants seront des prédictions erronées.
NLP - Traitement du langage naturel
Le NLP est un domaine de l'apprentissage automatique qui travaille sur la capacité d'un ordinateur à comprendre et à analyser le langage humain. Et oui, notre problème peut être résolu grâce au NLP.
Utilisation d'algorithmes d'apprentissage automatique
La plupart des algorithmes d'apprentissage automatique ont une chose en commun : ils utilisent en entrée des NOMBRES. Oui, je sais... c'est le point le plus difficile à comprendre pour créer des modèles d'apprentissage automatique.
Si tous les messages et les balises sont du texte, comment le modèle peut-il fonctionner ?
Une bonne partie du travail dans une solution de ML consiste à transformer les données en quelque chose qui peut être utilisé dans un algorithme.
Ce travail est appelé "ingénierie des fonctionnalités" (Feature Engineering). Dans ce cas, c'est plus compliqué car les données ne sont pas structurées. Mais voici une brève explication*:
J'ai transformé chaque mot du texte en un identifiant unique représenté par un nombre. SKLearn et d'autres librairies python devraient vous aider
de le faire facilement.
Démonstration
J'ai déployé le modèle formé en tant que démonstration ici : http://iris-ml-suite.eastus.cloudapp.azure.com/
Quelle est la suite ?
Dans mon prochain article, je montrerai le code et les moyens de faire toute la modélisation. A ne pas manquer !
Si cet article vous a aidé ou si vous avez aimé son contenu, votez :
Cette application est au concours actuel sur l'échange ouvert, vous pouvez voter ici: https://openexchange.intersystems.com/contest/current ou dans mon application iris-ml-suite