Apprentissage automatique dans IRIS en utilisant l'API HuggingFace et/ou des modèles ML en local ( en utilisant Python )
Sur GitHub, vous trouverez toutes les informations sur l'utilisation d'un modèle d'apprentissage automatique "HuggingFace" / modèle d'IA sur le cadre IRIS à l'aide de Python.

1. iris-huggingface
Utilisation de modèles d'apprentissage automatique dans IRIS à l'aide de Python ; pour les modèles texte-texte, texte-image ou image-image.
Les modèles suivants servent d'exemple :
2. Installation
2.1. Lancement de la production
Dans le dossier iris-local-ml, ouvrez un terminal et saisisse :
docker-compose up
La première fois, cela peut prendre quelques minutes pour construire l'image de manière correcte et installer tous les modules nécessaires à Python.
2.2. Accès à la production
En suivant ce lien, vous accédez à la production : Access the Production
2.3. Clôture de la production
docker-compose down
Comment ça marche
Pour l'instant, certains modèles peuvent ne pas fonctionner avec cette implémentation car tout est fait automatiquement, ce qui veut dire que, quel que soit le modèle que vous saisissez, nous essaierons de le faire fonctionner grâce à la bibliothèque transformers pipeline.
Pipeline est un outil puissant de l'équipe HuggingFace qui va scanner le dossier dans lequel nous avons téléchargé le modèle, puis il va déterminer quelle bibliothèque il doit utiliser entre PyTorch, Keras, Tensorflow ou JAX pour ensuite charger ce modèle en utilisant AutoModel.
À partir de ce point, en saisissant la tâche, le pipeline sait ce qu'il doit faire avec le modèle, l'analyseur lexical ou même l'extracteur de caractéristiques dans ce dossier, et gère automatiquement votre entrée, l'analyse et la traite, la transmet au modèle, puis restitue la sortie sous une forme décodée directement utilisable par nous.
3. API HuggingFace
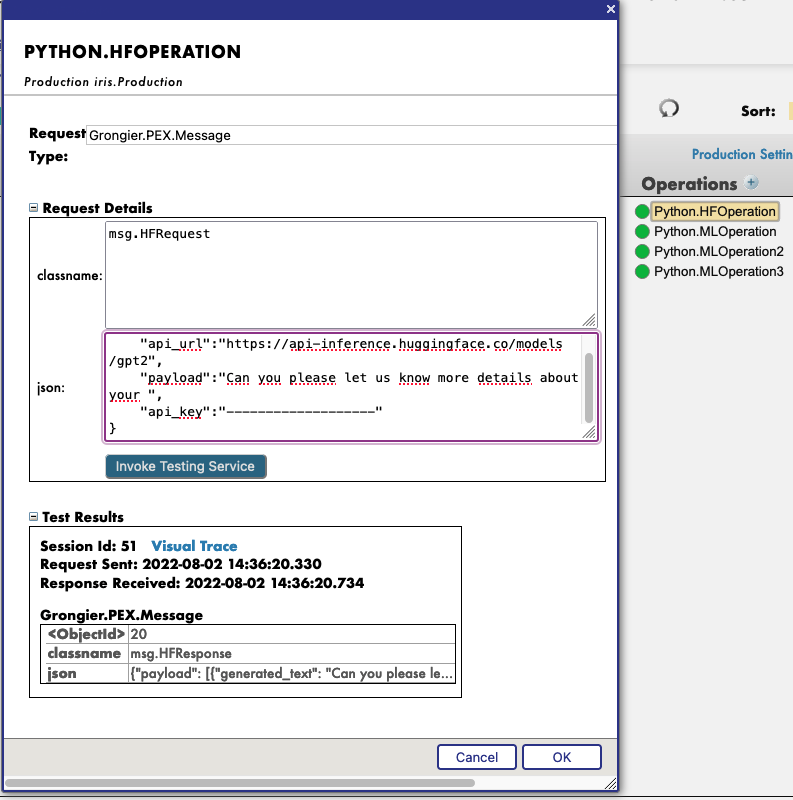
Vous devez d'abord démarrer la démo, en utilisant le bouton vert Start ou Stop et Start à nouveau pour appliquer vos changements de configuration.
Ensuite, en cliquant sur l'opération Python.HFOperation de votre choix, et en sélectionnant dans l'onglet de droite action, vous pouvez tester la démo.
Dans cette fenêtre test, sélectionnez :
Type de demande : Grongier.PEX.Message
Pour le classname vous devez saisir :
msg.HFRequest
Et pour le json, voici un exemple d'appel à GPT2 :
{
"api_url":"https://api-inference.huggingface.co/models/gpt2",
"payload":"Veuillez nous donner plus de détails sur votre ",
"api_key":"----------------------"
}
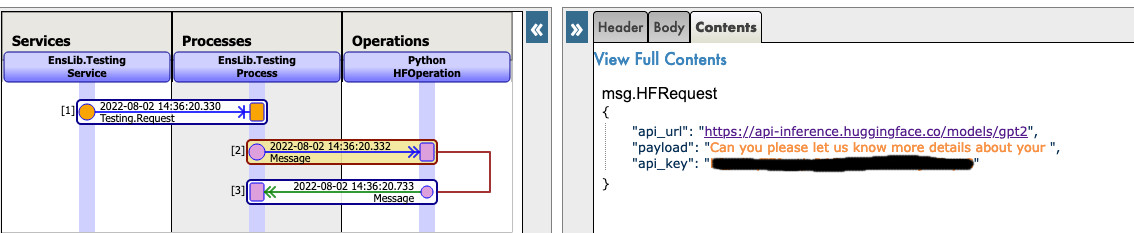
Vous pouvez maintenant cliquer sur le bouton Visual Trace (Trace visuelle) pour voir en détail ce qui s'est passé et consulter les journaux.
REMARQUE : vous devez avoir une clé API de HuggingFace avant d'utiliser cette opération (les clés API sont gratuites, il suffit de s'enregistrer auprès de HF).
REMARQUE : vous pouvez changer l'url pour essayer n'importe quel autre modèle de HuggingFace, mais vous devrez peut-être changer le payload.
Par exemple :

4. Utilisation de n'importe quel modèle sur le web
Dans cette section, nous vous apprendrons à utiliser presque tous les modèles disponibles sur l'internet, qu'il s'agisse de HuggingFace ou non.
4.1. PREMIER CAS : VOUS AVEZ VOTRE PROPRE MODÈLE
Dans ce cas, vous devez copier-coller votre modèle, avec la configuration, l'outil tokenizer.json etc. dans un dossier à l'intérieur du dossier model.
Chemin d'accès : src/model/yourmodelname/
A partir de là, vous devez aller dans les paramètres de Python.MLOperation.
Cliquez sur Python.MLOperation puis rendez-vous dans settings dans l'onglet de droite, puis dans la partie Python, puis dans la partie %settings.
Ici, vous pouvez saisir ou modifier n'importe quel paramètre (n'oubliez pas d'appuyer sur apply une fois que vous avez terminé).
Voici la configuration par défaut pour ce cas :
%settings
name=yourmodelname
task=text-generation
REMARQUE : tous les paramètres qui ne sont pas name ou model_url sont placés dans les paramètres de PIPELINE.
NMaintenant vous pouvez double-cliquer sur l'opération Python.MLOperation et la démarrer.
Vous devez voir dans la partie Log le démarrage de votre modèle.
A partir de là, nous créons une PIPELINE en utilisant des transformateurs qui utilisent votre fichier de configuration situé dans le dossier comme nous l'avons vu précédemment.
Pour appeler ce pipeline, cliquez sur l'opération Python.MLOperation , et sélectionnez dans l'onglet de droite action, vous pouvez tester la démo.
Dans cette fenêtre test, sélectionnez :
Type de demande : Grongier.PEX.Message
Pour le classname (nom de classe), vous devez saisir :
msg.MLRequest
Et pour le json, vous devez saisissez tous les arguments nécessaires à votre modèle.
Voici un exemple d'appel à GPT2 :
{
"text_inputs":"Malheureusement, le résultat",
"max_length":100,
"num_return_sequences":3
}
Cliquez sur Invoke Testing Service (Invoquer le service de test) et attendez que le modèle fonctionne.
Voir par exemple :

Vous pouvez maintenant cliquer sur Visual Trace (Trace visuelle) pour voir en détail ce qui s'est passé et consulter les journaux.
Voir par exemple :

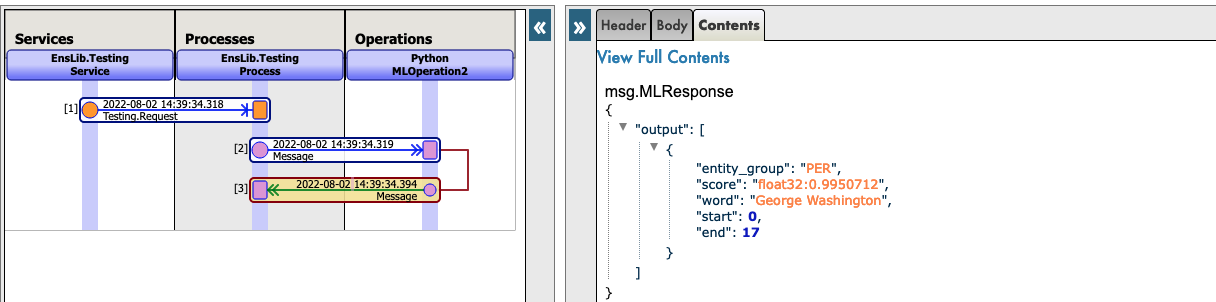
4.2. DEUXIÈME CAS : VOUS VOULEZ TÉLÉCHARGER UN MODÈLE À PARTIR DE HUGGINGFACE
Dans ce cas, vous devez trouver l'URL du modèle sur HuggingFace ;
4.2.1. Paramètres
À partir de là, vous devez accéder aux paramètres de la Python.MLOperation.
Cliquez sur Python.MLOperation puis allez dans des paramètres settings dans l'onglet de droite, puis dans la partie Python, puis dans la partie %settings.
Ici, vous pouvez saisir ou modifier n'importe quel paramètre (n'oubliez pas d'appuyer sur apply (appliquer) une fois que vous avez terminé).
Voici quelques exemples de configuration pour certains modèles que nous avons trouvés sur HuggingFace :
%settings pour gpt2
model_url=https://huggingface.co/gpt2
name=gpt2
task=text-generation
%settings pour camembert-ner
name=camembert-ner
model_url=https://huggingface.co/Jean-Baptiste/camembert-ner
task=ner
aggregation_strategy=simple
%settings pour bert-base-uncased
name=bert-base-uncased
model_url=https://huggingface.co/bert-base-uncased
task=fill-mask
%settings pour detr-resnet-50
name=detr-resnet-50
model_url=https://huggingface.co/facebook/detr-resnet-50
task=object-detection
%settings pour detr-resnet-50-protnic
name=detr-resnet-50-panoptic
model_url=https://huggingface.co/facebook/detr-resnet-50-panoptic
task=image-segmentation
REMARQUE : tous les paramètres qui ne sont pas name ou model_url iront dans les paramètres du PIPELINE, donc dans notre second exemple, le pipeline camembert-ner requiert une stratégie aggregation_strategy et une tâche task qui sont spécifiées ici alors que le pipeline gpt2 ne requiert qu'une tâche task.
Voir par exemple :
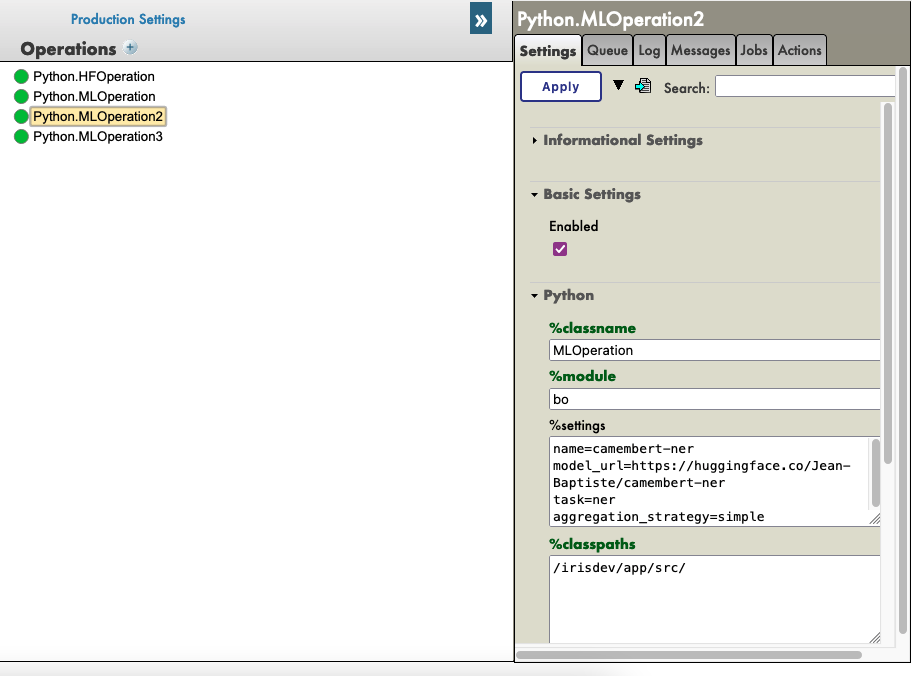
Vous pouvez maintenant double-cliquer sur l'opération Python.MLOperation et la démarrer.
Vous devez voir dans la partie Log le démarrage de votre modèle et le téléchargement.
REMARQUE : Vous pouvez actualiser ces journaux toutes les x secondes pour voir l'évolution des téléchargements.

A partir de là, nous créons une PIPELINE en utilisant des transformateurs qui utilisent votre fichier de configuration qui se trouve dans le dossier comme nous l'avons vu précédemment.
4.2.2. Tests
Pour appeler ce pipeline, cliquez sur l'opération Python.MLOperation , et sélectionnez dans l'onglet de droite action, vous pouvez tester la démo.
Dans cette fenêtre test, sélectionnez :
Type de demande : Grongier.PEX.Message
Pour le classname (nom de classe), vous devez saisir :
msg.MLRequest
Et pour le json, vous devez saisir tous les arguments nécessaires à votre modèle.
Voici un exemple d'appel à GPT2 ( Python.MLOperation ) :
{
"text_inputs":"George Washington a vécu",
"max_length":30,
"num_return_sequences":3
}
Voici un exemple d'appel à Camembert-ner ( Python.MLOperation2 ) :
{
"inputs":"George Washington a vécu à Washington"
}
Voici un exemple d'appel à bert-base-uncased ( Python.MLOperation3 ) :
{
"inputs":"George Washington a vécu à [MASQUE]."
}
Voici un exemple d'appel à detr-resnet-50 à l'aide d'une url en ligne ( Python.MLOperationDETRRESNET ) :
{
"url":"http://images.cocodataset.org/val2017/000000039769.jpg"
}
Voici un exemple d'appel à detr-resnet-50-panoptic utilisant l'url comme chemin d'accès( Python.MLOperationDetrPanoptic ) :
{
"url":"/irisdev/app/misc/000000039769.jpg"
}
Cliquez sur Invoke Testing Service et attendez que le modèle fonctionne.
Vous pouvez maintenant cliquer sur Visual Trace pour voir en détail ce qui s'est passé et consulter les journaux.
REMARQUE : Lorsque le modèle a été téléchargé pour la première fois, la production ne le téléchargera pas à nouveau mais récupérera les fichiers mis en cache dans src/model/TheModelName/.
Si certains fichiers sont manquants, la production les téléchargera à nouveau.
Voir par exemple :
Voir par exemple :


5. Dépannage
Si vous avez des problèmes, la lecture est le premier conseil que nous pouvons vous donner, la plupart des erreurs sont facilement compréhensibles simplement en lisant les journaux car presque toutes les erreurs seront capturées par un try / catch et enregistrées.
Si vous avez besoin d'installer un nouveau module, ou une dépendance Python, ouvrez un terminal à l'intérieur du conteneur et saisissez par exemple : "pip install new-module"
Il y a plusieurs façons d'ouvrir un terminal,
- Si vous utilisez les plugins InterSystems, vous pouvez cliquer sur la barre ci-dessous dans VSCode, celle qui ressemble à
docker:iris:52795[IRISAPP]et sélectionnerOpen Shell in Docker(Ouvrir l'enveloppe dans Docker). - Dans n'importe quel terminal local, saisissez :
docker-compose exec -it iris bash - Depuis Docker-Desktop, trouvez le conteneur IRIS et cliquez sur
Open in terminal(Ouvrir dans le terminal).
Certains modèles peuvent nécessiter des modifications au niveau de leur pipeline ou de leurs paramètres, par exemple, et c'est à vous qu'il incombe d'ajouter les informations adéquates dans les paramètres et dans la demande.
6. Conclusion
À partir de là, vous devriez pouvoir utiliser n'importe quel modèle dont vous avez besoin ou que vous possédez sur IRIS.
REMARQUE : vous pouvez créer une Python.MLOperation pour chacun de vos modèles et les activer en même temps.