Prédictions de Covid-19 ICU via ML vs. IntegratedML (Partie I)
Keywords: IRIS, IntegratedML, apprentissage automatique, Covid-19, Kaggle
Objectif
J'ai récemment remarqué un jeu de données Kaggle permettant de prédire si un patient Covid-19 sera admis en soins intensifs. Il s'agit d'un tableur de 1925 enregistrements comprenant 231 colonnes de signes vitaux et d'observations, la dernière colonne " USI " valant 1 pour Oui ou 0 pour Non.
Ce jeu de données représente un bon exemple de ce que l'on appelle une tâche "traditionnelle de ML". Les données semblent avoir une quantité suffisante et une qualité relativement bonne. Il pourrait avoir de meilleures chances d'être appliqué directement sur le kit IntegratedML demo. Quelle serait donc l'approche la plus simple pour un test rapide basé sur les pipelines ML normaux par rapport à l'approche possible avec IntegratedML ?
Champ d'application
Nous examinerons brièvement quelques étapes normales de ML, telles que :
- Analyse des données (EDA)
- Sélection des caractéristiques
- Sélection du modèle
- Ajustement des paramètres du modèle via le quadrillage
Vs.
- Approches ML intégrées via SQL.
Il est exécuté sur un serveur AWS Ubuntu 16.04 avec Docker-compose, etc.
Environnement
Nous allons réutiliser l'environnement Docker de integredML-demo-template:
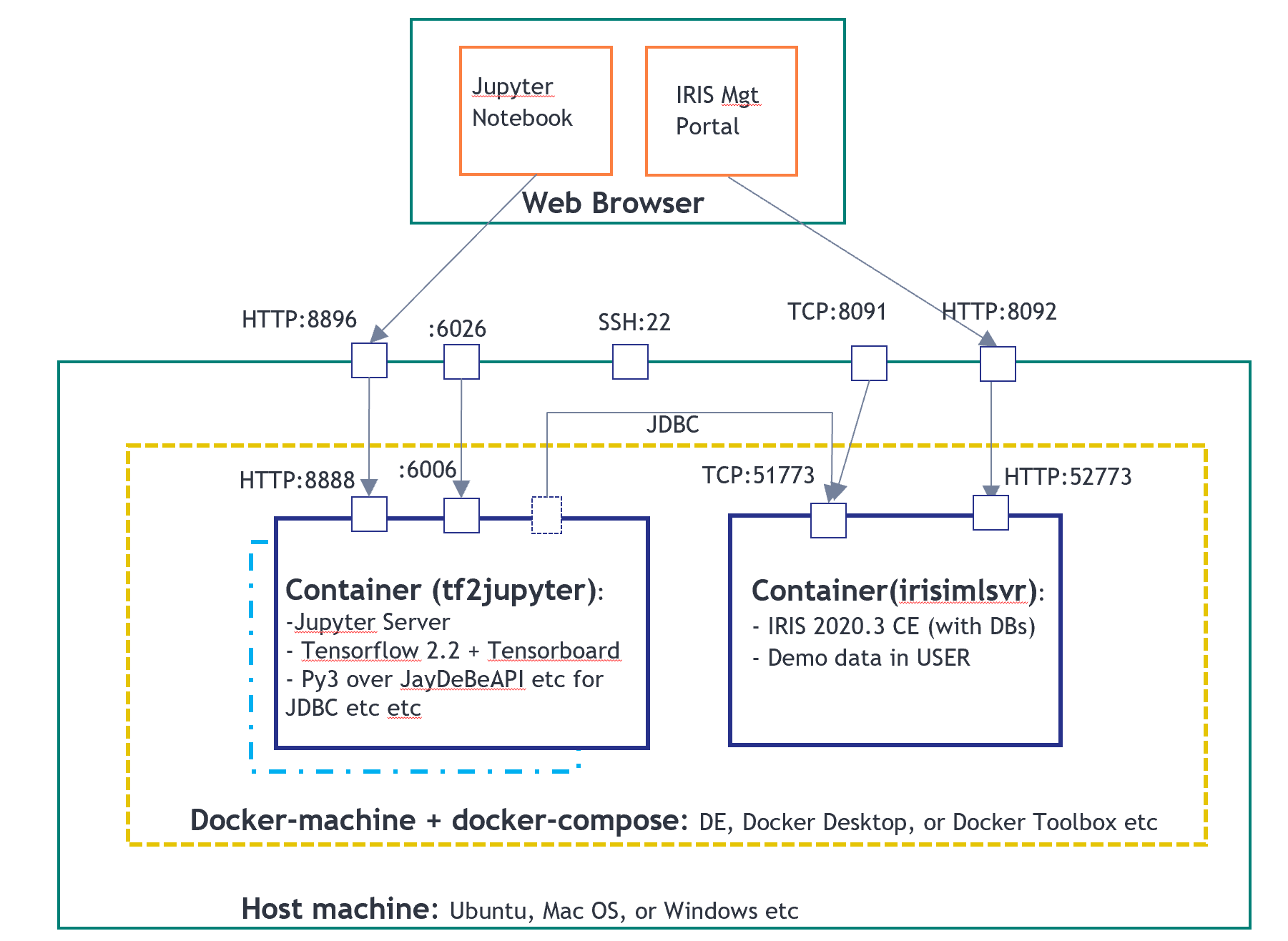
Le fichier de bloc-notes suivant est exécuté sur "tf2jupyter", et IRIS avec IntegratedML sur "irismlsrv". Docker-compose fonctionne sur un AWS Ubuntu 16.04.
Données et tâches
Le jeu de données contient 1925 enregistrements collectés auprès de 385 patients, chacun comportant exactement 5 enregistrements de rendez-vous. Sur ses 231 colonnes, une seule, "USI", constitue notre cible d'apprentissage et de prédiction, et les 230 autres colonnes pourraient toutes être utilisées comme entrées de quelque manière que ce soit. L'unité de soins intensifs a une valeur binaire de 1 ou 0. À l'exception de deux colonnes qui semblent être des chaînes catégorielles (présentées comme "objet" dans le cadre de données), toutes les autres sont numériques.
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, roc_auc_score, roc_curve
import seaborn as sns
sns.set(style="whitegrid")
import os
for dirname, _, filenames in os.walk('./input'):
for filename in filenames:
print(os.path.join(dirname, filename))
./input/datasets_605991_1272346_Kaggle_Sirio_Libanes_ICU_Prediction.xlsx
df = pd.read_excel("./input/datasets_605991_1272346_Kaggle_Sirio_Libanes_ICU_Prediction.xlsx")
df| IDENTIFIANT_DE_VISITE_DU_PATIENT | ÂGE_AU-DESSUS65 | ÂGE_POURCENTAGE | GENRE | GROUPE DE MALADIES 1 | GROUPE DE MALADIES 2 | GROUPE DE MALADIES 3 | GROUPE DE MALADIES 4 | GROUPE DE MALADIES 5 | GROUPE DE MALADIES 6 | ... | DIFFÉRENCE_DE_TEMPÉRATURE | DIFFÉRENCE_DE SATURATION_D'OXYGÈNE | DIFFÉRENCE_DE_TENSION_DIASTOLIQUE_REL | DIFFÉRENCE_DE_TENSION_SISTOLIQUE_REL | DIFFÉRENCE_DU_RYTHME_CARDIAQUE_REL | DIFFÉRENCE_DE_TAUX_RESPIRATOIRE_REL | DIFFÉRENCE_DE_TEMPÉRATURE_REL | DIFFÉRENCE_DE_SATURATION_D'OXYGÈNE_REL | FENÊTRE | ICU | 1 | âge de 60-69 ans | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | ... | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | 0-2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | âge de 60-69 ans | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | ... | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | 2-4 | |||
| 2 | 1 | âge de 60-69 ans | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 4-6 | |||
| 3 | 1 | âge de 60-69 ans | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | ... | -1.000000 | -1.000000 | NaN | NaN | NaN | NaN | -1.000000 | -1.000000 | 6-12 | |||
| 4 | 1 | âge de 60-69 ans | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | ... | -0.238095 | -0.818182 | -0.389967 | 0.407558 | -0.230462 | 0.096774 | -0.242282 | -0.814433 | AU-DESSUS_12 | 1 | ||
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1920 | 384 | âge de 50-59 ans | 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | 0-2 | ||
| 1921 | 384 | âge de 50-59 ans | 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | 2-4 | ||
| 1922 | 384 | âge de 50-59 ans | 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | 4-6 | ||
| 1923 | 384 | âge de 50-59 ans | 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | 6-12 | ||
| 1924 | 384 | âge de 50-59 ans | 1 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | -0.547619 | -0.838384 | -0.701863 | -0.585967 | -0.763868 | -0.612903 | -0.551337 | -0.835052 | AU-DESSUS_12 |
1925 lignes × 231 colonnes
df.dtypesIDENTIFIANT_DE_VISITE_DU_PATIENT int64 ÂGE_AU-DESSUS65 int64 ÂGE_POURCENTAGE object GENRE int64 GROUPE DE MALADIES 1 float64 ...
DIFFÉRENCE_DE_TAUX_RESPIRATOIRE_REL float64 DIFFÉRENCE_DE_TEMPÉRATURE_REL float64 DIFFÉRENCE_DE SATURATION_D'OXYGÈNE_REL float64 FENÊTRE object USI int64 Longeur: 231, dtype: object
Il existe certainement plusieurs options pour définir ce problème et ses approches. La première option qui nous vient à l'esprit est qu'il peut s'agir d'un problème fondamental de "classification binaire". Nous pouvons traiter les 1925 enregistrements comme des enregistrements individuels "apatrides", qu'ils proviennent ou non du même patient. Bien sûr, il pourrait également s'agir d'un problème de "régression" si nous traitions les valeurs de l'unité de soins intensifs et d'autres valeurs comme étant toutes numériques.
Il existe certainement d'autres approches possibles. Par exemple, nous pouvons considérer que l'ensemble de données comporte 385 jeux distincts de courtes "séries temporelles", chacun pour un patient. Nous pourrions dissoudre le jeu entier en 385 jeux distincts pour Train/Val/Test, et pourrions-nous essayer des modèles d'apprentissage profond tels que CNN ou LSTM pour capturer la "phase ou le modèle de développement des symptômes" caché dans chaque jeu pour chaque patient individuel ? C'est possible. Ce faisant, nous pourrions également appliquer une augmentation des données pour enrichir les données de test par divers moyens. Il s'agit là d'un sujet qui dépasse le cadre de cet article.
Dans cet article, nous nous contenterons de tester rapidement l'approche ML dite "traditionnelle" par rapport à l'approche IntegratedML (une approche AutoML)..
Approche ML "traditionnelle" ?
Il s'agit d'un jeu de données relativement normalisé par rapport à la plupart des cas réels, à l'exception de quelques valeurs manquantes, de sorte que nous pourrions sauter la partie relative à l'ingénierie des caractéristiques et utiliser directement les colonnes comme caractéristiques. Passons donc directement à la sélection des caractéristiques.
Imputation des données manquantes
Il faut d'abord s'assurer que toutes les valeurs manquantes sont remplies au moyen d'une imputation simple :
df_cat = df.select_dtypes(include=['object'])
df_numeric = df.select_dtypes(exclude=['object'])
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
idf = pd.DataFrame(imp.fit_transform(df_numeric))
idf.columns = df_numeric.columns
idf.index = df_numeric.index
idf.isnull().sum()Sélection sur les caractéristiques
Nous pouvons certainement utiliser la fonction de corrélation normale intégrée dans la base de données pour calculer la corrélation entre les valeurs de chaque colonne et les unités de soins intensifs.
l'ingénierie des caractéristiques - corrélation {#featuring-engineering---correlation}
idf.drop(["PATIENT_VISIT_IDENTIFIER"],1)
idf = pd.concat([idf,df_cat ], axis=1)
cor = idf.corr()
cor_target = abs(cor["ICU"])
relevant_features = cor_target[cor_target>0.1] # correlation above 0.1
print(cor.shape, cor_target.shape, relevant_features.shape)
#relevant_features.index
#relevant_features.index.shapeIl répertorie 88 caractéristiques présentant une corrélation >0,1 avec la valeur cible de l'unité de soins intensifs. Ces colonnes peuvent être directement utilisées comme entrée de notre modèle
J'ai également exécuté quelques autres "méthodes de sélection de caractéristiques" qui sont normalement utilisées dans les tâches traditionnelles de ML :
Sélection des caractéristiques - Chi carré {#feature-selection---Chi-squared}
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import MinMaxScaler
X_norm = MinMaxScaler().fit_transform(X)
chi_selector = SelectKBest(chi2, k=88)
chi_selector.fit(X_norm, y)
chi_support = chi_selector.get_support()
chi_feature = X.loc[:,chi_support].columns.tolist()
print(str(len(chi_feature)), 'selected features', chi_feature)88 caractéristiques sélectionnées ['ÂGE_AU-DESSUS65', 'GENRE', 'GROUPE DE MALADIES 1', ... ... 'P02_VENEUS_MIN', 'P02_VENEUS_MAX', ... ... RATURE_MAX', 'DIFFÉRENCE_DE_TENSION_ARTÉRIELLE_DIASTOLIQUE', ... ... 'DIFFÉRENCE_DE_TEMPÉRATURE_REL', 'DIFFÉRENCE_DE SATURATION_D'OXYGÈNE_REL']
Sélection des caractéristiques - Corrélation de Pearson
def cor_selector(X, y,num_feats): cor_list = [] feature_name = X.columns.tolist() # calculate the correlation with y for each feature for i in X.columns.tolist(): cor = np.corrcoef(X[i], y)[0, 1] cor_list.append(cor) # replace NaN with 0 cor_list = [0 if np.isnan(i) else i for i in cor_list] # feature name cor_feature = X.iloc[:,np.argsort(np.abs(cor_list))[-num_feats:]].columns.tolist() # Sélection des caractéristiques? 0 for not select, 1 for select cor_support = [Vrai if i in cor_feature else False for i in feature_name] return cor_support, cor_feature
cor_support, cor_feature = cor_selector(X, y, 88) print(str(len(cor_feature)), 'selected features: ', cor_feature)
88 caractéristiques sélectionnées: ['TEMPÉRATURE_MOYENNE', 'TENSION_DIASTOLIQUE_MAX', ... ... 'DIFFÉRENCE_DE_TAUX_ RESPIRATOIRE', 'AUX_ RESPIRATOIRE_MAX']
Sélection des caractéristiques - élimination de caractéristiques récursives (RFE) {#feature-selection---Recursive-Feature-Elimination-(RFE)}
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
rfe_selector = RFE(estimator=LogisticRegression(), n_features_to_select=88, step=100, verbose=5)
rfe_selector.fit(X_norm, y)
rfe_support = rfe_selector.get_support()
rfe_feature = X.loc[:,rfe_support].columns.tolist()
print(str(len(rfe_feature)), 'selected features: ', rfe_feature)Estimateur d'ajustement avec 127 caractéristiques. 88 caractéristiques sélectionnées: ['ÂGE_AU-DESSUS65', 'GENRE', ... ... 'DIFFÉRENCE_DE_TAUX_ RESPIRATOIRE_REL', 'DIFFÉRENCE_DE_TEMPÉRATURE_REL']
Sélection des caractéristiques - Lasso
ffrom sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import MinMaxScaler
X_norm = MinMaxScaler().fit_transform(X)
embeded_lr_selector = SelectFromModel(LogisticRegression(penalty="l2"), max_features=88)
embeded_lr_selector.fit(X_norm, y)
embeded_lr_support = embeded_lr_selector.get_support()
embeded_lr_feature = X.loc[:,embeded_lr_support].columns.tolist()
print(str(len(embeded_lr_feature)), 'selected features', embeded_lr_feature)65 caractéristiques sélectionnées ['ÂGE_AU-DESSUS65', 'GENRE', ... ... 'DIFFÉRENCE_DE_TAUX_ RESPIRATOIRE_REL', 'DIFFÉRENCE_DE_TEMPÉRATURE_REL']
Sélection des caractéristiques - RF Tree-based: SelectFromModel
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
embeded_rf_selector = SelectFromModel(RandomForestClassifier(n_estimators=100), max_features=227)
embeded_rf_selector.fit(X, y)
embeded_rf_support = embeded_rf_selector.get_support()
embeded_rf_feature = X.loc[:,embeded_rf_support].columns.tolist()
print(str(len(embeded_rf_feature)), 'selected features', embeded_rf_feature)48 selected features ['ÂGE_AU-DESSUS65', 'GENRE', ... ... 'DIFFÉRENCE_DE_TEMPÉRATURE_REL', 'DIFFÉRENCE_DE SATURATION_D'OXYGÈNE_REL']
Sélection des caractéristiques - LightGBM or XGBoost {#feature-selection---LightGBM-or-XGBoost}
from sklearn.feature_selection import SelectFromModel from lightgbm import LGBMClassifierlgbc=LGBMClassifier(n_estimators=500, learning_rate=0.05, num_leaves=32, colsample_bytree=0.2, reg_alpha=3, reg_lambda=1, min_split_gain=0.01, min_child_weight=40)embeded_lgb_selector = SelectFromModel(lgbc, max_features=128) embeded_lgb_selector.fit(X, y)embeded_lgb_support = embeded_lgb_selector.get_support() embeded_lgb_feature = X.loc[:,embeded_lgb_support].columns.tolist() print(str(len(embeded_lgb_feature)), 'selected features: ', embeded_lgb_feature) embeded_lgb_feature.index
56 selected features: ['ÂGE_AU-DESSUS65', 'GENRE', 'HTN', ... ... 'DIFFÉRENCE_DE_TEMPÉRATURE_REL', 'DIFFÉRENCE_DE SATURATION_D'OXYGÈNE_REL']
Sélection des caractéristiques - Les regrouper tous {#feature-selection---Ensemble-them-all}
feature_name = X.columns.tolist()regrouper toute la sélection
feature_selection_df = pd.DataFrame({'Feature':feature_name, 'Pearson':cor_support, 'Chi-2':chi_support, 'RFE':rfe_support, 'Logistics':embeded_lr_support, 'Random Forest':embeded_rf_support, 'LightGBM':embeded_lgb_support})
compter les temps sélectionnés pour chaque caractéristique
feature_selection_df['Total'] = np.sum(feature_selection_df, axis=1)
afficher les 100 premières
num_feats = 227 feature_selection_df = feature_selection_df.sort_values(['Total','Feature'] , ascending=False) feature_selection_df.index = range(1, len(feature_selection_df)+1) feature_selection_df.head(num_feats)
df_selected_columns = feature_selection_df.loc[(feature_selection_df['Total'] > 3)] df_selected_columns
Nous pouvons dresser la liste des caractéristiques qui ont été sélectionnées dans le cadre d'au moins quatre méthodes :
.png)
... ...
.png)
Nous pouvons certainement choisir ces 58 caractéristiques. Entre-temps, l'expérience nous a appris que la sélection des caractéristiques n'est pas nécessairement toujours un vote démocratique ; le plus souvent, elle peut être spécifique au problème du domaine, aux données spécifiques et parfois au modèle ou à l'approche ML spécifique que nous allons adopter plus tard.
Sélection des caractéristiques - Outils tiers
Il existe des outils industriels et des outils AutoML largement utilisés, par exemple DataRobot qui peut fournir une bonne sélection automatique des caractéristiques :
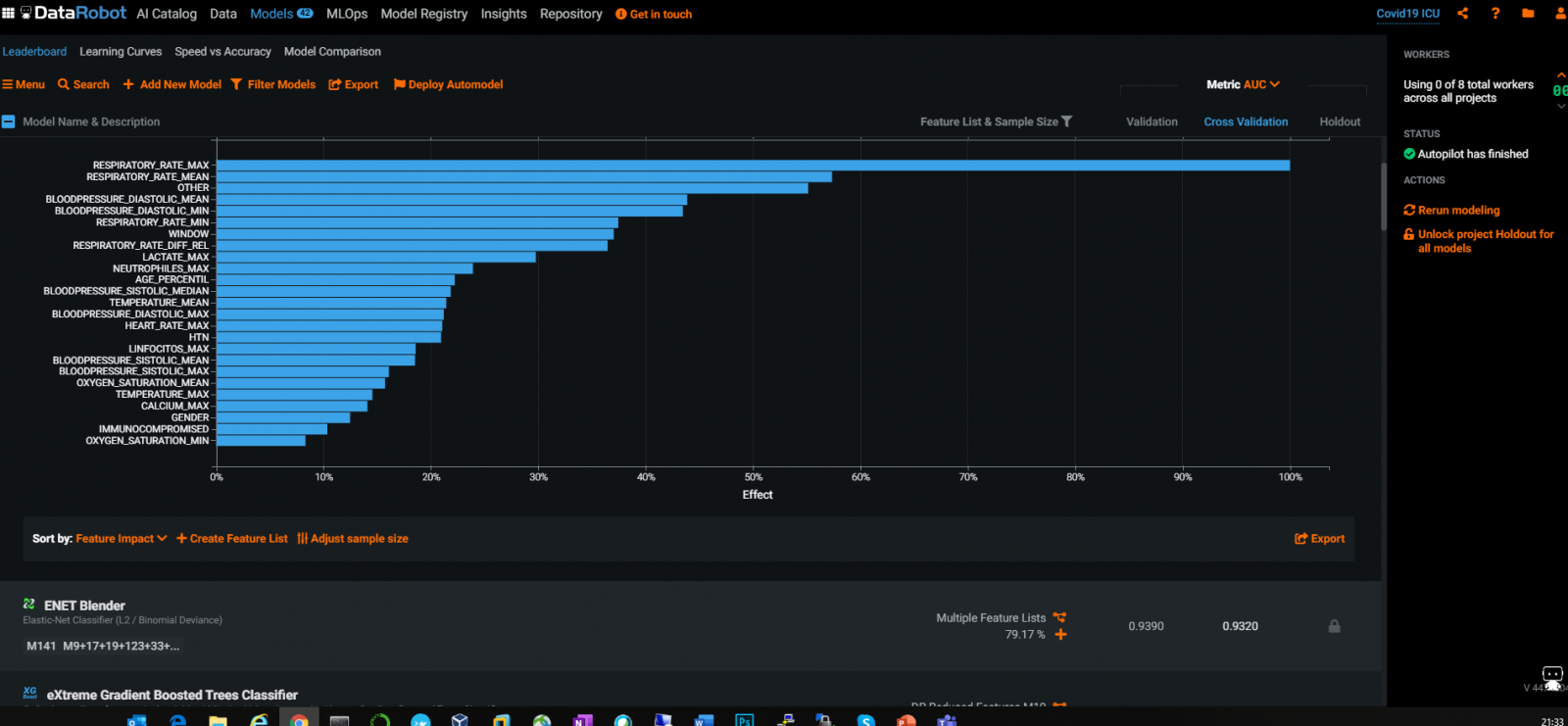
Le graphe DataRobot ci-dessus montre, sans surprise, que les valeurs de fréquence respiratoire et de tension artérielle sont les caractéristiques les plus pertinentes pour l'admission en soins intensifs.
Sélection des caractéristiques - Sélection finale
Dans ce cas, j'ai fait quelques expériences rapides et j'ai remarqué que la sélection des caractéristiques par LightGBM donnait un résultat un peu meilleur, c'est pourquoi nous n'utiliserons que cette méthode de sélection.
df_selected_columns = embeded_lgb_feature # mieux que la sélection ensemblistedataS = pd.concat([idf[df_selected_columns],idf['ICU'], df_cat['FENÊTRE']],1) dataS.ICU.value_counts() print(dataS.shape)
(1925, 58)
Nous pouvons voir que 58 caractéristiques sont sélectionnées, c'est-à-dire ni trop peu, ni trop beaucoup, ce qui semble être la bonne quantité pour ce problème spécifique de classification binaire à cible unique.
Déséquilibre des données
plt.figure(figsize=(10,5))
count = sns.countplot(x = "USI",data=data)
count.set_xticklabels(["Non admis", "Admis"])
plt.xlabel("Admission à l'USI")
plt.ylabel("Nombre de patients")
plt.show()

Cela indique que les données sont déséquilibrées, seuls 26 % des enregistrements étant admis en USI. Cela aura un impact sur les résultats et nous pouvons donc envisager des approches normales d'équilibrage des données telles que SMOTE, etc.
Nous pouvons essayer toutes sortes d'autres AED pour analyser les différentes distributions de données en conséquence.
Exécuter une formation de base en LR
Le site Kaggle propose de jolis carnets d'entraînement rapide que nous pouvons exécuter rapidement en fonction de notre propre sélection de colonnes de caractéristiques. Commençons par une exécution rapide du classificateur LR pour le pipeline de formation :
data2 = pd.concat([idf[df_selected_columns],idf['USI'], df_cat['FENÊTRE']],1)
data2.AGE_ABOVE65 = data2.AGE_ABOVE65.astype(int) data2.ICU = data2.ICU.astype(int) X2 = data2.drop("USI",1) y2 = data2.ICUfrom sklearn.preprocessing import LabelEncoder label_encoder = LabelEncoder() X2.WINDOW = label_encoder.fit_transform(np.array(X2["FENÊTRE"].astype(str)).reshape((-1,)))
confusion_matrix2 = pd.crosstab(y2_test, y2_hat, rownames=['Réel'], colnames=['Prédit']) sns.heatmap(confusion_matrix2, annot=Vrai, fmt = 'g', cmap = 'Reds') print("ORIGINAL") print(classification_report(y_test, y_hat)) print("USI = ",roc_auc_score(y_test, y_hat),'\n\n') print("ENCODAGE D'ÉTIQUETTE") print(classification_report(y2_test, y2_hat)) print("ASC = ",roc_auc_score(y2_test, y2_hat)) y2hat_probs = LR.predict_proba(X2_test) y2hat_probs = y2hat_probs[:, 1] fpr2, tpr2, _ = roc_curve(y2_test, y2hat_probs) plt.figure(figsize=(10,7)) plt.plot([0, 1], [0, 1], 'k--') plt.plot(fpr, tpr, label="Base") plt.plot(fpr2,tpr2,label="Étiquette encodée") plt.xlabel('Taux de faux positifs') plt.ylabel('Taux de vrais positifs') plt.title('Courbe ROC') plt.legend(loc="meilleur") plt.show()
ORIGINAL précision rappel score f1 support 0 0.88 0.94 0.91 171 1 0.76 0.57 0.65 54 exactitude 0.85 225 moyenne macro 0.82 0.76 0.78 225 moyenne pondérée 0.85 0.85 0.85 225 ASC= 0.7577972709551657 LABEL ENCODING précision rappel score f1 support 0 0.88 0.93 0.90 171 1 0.73 0.59 0.65 54 accuracy 0.85 225 moyenne macro 0.80 0.76 0.78 225 moyenne pondérée 0.84 0.85 0.84 225 ASC = 0.7612085769980507


Il semble qu'il atteigne une AUC de 76 %, avec une précision de 85 %, mais le rappel pour les patients admis en réanimation n'est que de 59 % - il semble y avoir trop de faux négatifs. Ce n'est certainement pas l'idéal - nous ne voulons pas passer à côté des risques réels de l'USI pour le dossier d'un patient. Toutes les tâches suivantes seront donc axées sur l'objectif sur la manière d'augmenter le taux de rappel, en réduisant le FN, avec une précision globale quelque peu équilibrée, nous l'espérons.
Dans les sections précédentes, nous avons mentionné des données déséquilibrées, de sorte que notre premier réflexe serait de stratifier l'ensemble de test et de le MODIFIER pour obtenir un ensemble de données plus équilibré.
#stratifier les données de test, afin de s'assurer que les données de train et de test ont le même ratio de 1:0 X3_train,X3_test,y3_train,y3_test = train_test_split(X2,y2,test_size=225/1925,random_state=42, stratify = y2, shuffle = Vrai) <span> </span>former et prédire
LR.fit(X3_train,y3_train) y3_hat = LR.predict(X3_test)
#MODIFIER les données pour faire de l'UCI 1:0 une distribution équilibrée from imblearn.over_sampling import SMOTE sm = SMOTE(random_state = 42) X_train_res, y_train_res = sm.fit_sample(X3_train,y3_train.ravel()) LR.fit(X_train_res, y_train_res) y_res_hat = LR.predict(X3_test)
#recréer la matrice de confusion, etc. confusion_matrix3 = pd.crosstab(y3_test, y_res_hat, rownames=['Actual'], colnames=['Predicted']) sns.heatmap(confusion_matrix3, annot=Vrai, fmt = 'g', cmap="YlOrBr") print("LABEL ENCODING + STRATIFY") print(classification_report(y3_test, y3_hat)) print("ASC = ",roc_auc_score(y3_test, y3_hat),'\n\n') print("SMOTE") print(classification_report(y3_test, y_res_hat)) print("ASC = ",roc_auc_score(y3_test, y_res_hat)) y_res_hat_probs = LR.predict_proba(X3_test) y_res_hat_probs = y_res_hat_probs[:, 1] fpr_res, tpr_res, _ = roc_curve(y3_test, y_res_hat_probs) plt.figure(figsize=(10,10))
#Et tracez la courbe ROC comme précédemment.
LABEL ENCODING + STRATIFY (CODAGE D'ÉTIQUETTES + STRATIFICATION) précision rappel f1 score support 0 0.87 0.99 0.92 165 1 0.95 0.58 0.72 60 exactitude 0.88 225 moyenne macro 0.91 0.79 0.82 225 moyenne pondérée 0.89 0.88 0.87 225 ASC = 0.7856060606060606 SMOTE précision rappel f1 score support 0 0.91 0.88 0.89 165 1 0.69 0.75 0.72 60 exactitude 0.84 225 moyenne macro 0.80 0.81 0.81 225 moyenne pondérée 0.85 0.84 0.85 225 ASC = 0.8143939393939393


Les traitements des données par STRATIFY (stratification) et SMOT (optimisation) semblent donc améliorer le rappel, qui passe de 0,59 à 0,75, avec une précision globale de 0,84.
Maintenant que le traitement des données est largement effectué comme d'habitude pour le ML traditionnel, nous voulons savoir quel pourrait être le(s) meilleur(s) modèle(s) dans ce cas ; peuvent-ils faire mieux, et pouvons-nous alors essayer une comparaison globale relative ?
Comparaison de l'entraînement à la course de différents modèles:
Poursuivons l'évaluation de quelques algorithmes de ML couramment utilisés, et générons un tableau de bord de résultats à comparer à l'aide de diagrammes en boîte à moustaches :
# comparer les algorithmes from matplotlib import pyplot from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score from sklearn.model_selection import StratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC #Importer un modèle arborescent aléatoire from sklearn.ensemble import RandomForestClassifier from xgboost import XGBClassifier
# Répertorier les algorithmes ensemble models = [] models.append(('LR', <strong>LogisticRegression</strong>(solver='liblinear', multi_class='ovr'))) models.append(('LDA', LinearDiscriminantAnalysis())) models.append(('KNN', <strong>KNeighborsClassifier</strong>())) models.append(('CART', <strong>DecisionTreeClassifier</strong>())) models.append(('NB', <strong>GaussianNB</strong>())) models.append(('SVM', <strong>SVC</strong>(gamma='auto'))) models.append(('RF', <strong>RandomForestClassifier</strong>(n_estimators=100))) models.append(('XGB', <strong>XGBClassifier</strong>())) #clf = XGBClassifier()# évaluer chaque modèle à tour de rôle résultats = [] noms = [] pour nom, modèler dans modèles : kfold = StratifiedKFold(n_splits=10, random_state=1) cv_results = cross_val_score(model, X_train_res, y_train_res, cv=kfold, scoring='f1') ## exactitude, précision, rappel results.append(cv_results) names.append(name) print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))
# Comparer les performances de tous les modèles. Question - Souhaitez-vous voir un article intégré sur le site ? pyplot.figure(4, figsize=(12, 8)) pyplot.boxplot(résultats, étiquettes=noms) pyplot.title('Comparaison des algorithmes') pyplot.show()LR: 0.805390 (0.021905) LDA: 0.803804 (0.027671) KNN: 0.841824 (0.032945) CART: 0.845596 (0.053828) NB: 0.622540 (0.060390) SVM: 0.793754 (0.023050) RF: 0.896222 (0.033732) XGB: 0.907529 (0.040693)
Ce qui précède semble montrer que le classificateur XGB et le classificateur de la forêt aléatoire "Random Forest" obtiendraient un meilleur score F1 que les autres modèles.
Comparons leurs résultats réels sur le même ensemble de données de test normalisées :
Temps d'importation from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.svm import SVC
pour nom, modèler dans modèles : print(name + ':\n\r') start = time.clock() model.fit(X_train_res, y_train_res) print("Temps de formation pour ", model, " ", time.clock() - start) predictions = model.predict(X3_test) #(X_validation) # Evaluate predictions print(accuracy_score(y3_test, predictions)) # Y_validation print(confusion_matrix(y3_test, predictions)) print(classification_report(y3_test, predictions))LR: Temps de formation pour LogisticRegression(multi_class='ovr', solver='liblinear') 0.02814499999999498 0.8444444444444444 [[145 20] [ 15 45]] précision rappel f1 score support 0 0.91 0.88 0.89 165 1 0.69 0.75 0.72 60 exactitude 0.84 225 moyenne macro 0.80 0.81 0.81 225 moyenne pondérée 0.85 0.84 0.85 225LDA: Temps de formation pour LinearDiscriminantAnalysis() 0.2280070000000194 0.8488888888888889 [[147 18] [ 16 44]] précision rappel f1 score support 0 0.90 0.89 0.90 165 1 0.71 0.73 0.72 60 exactitude 0.85 225 moyenne macro 0.81 0.81 0.81 225 moyenne pondérée 0.85 0.85 0.85 225
KNN: Temps de formation pour KNeighborsClassifier() 0.13023699999999394 0.8355555555555556 [[145 20] [ 17 43]] précision rappel f1 score support 0 0.90 0.88 0.89 165 1 0.68 0.72 0.70 60 exactitude 0.84 225 moyenne macro 0.79 0.80 0.79 225 moyenne pondérée 0.84 0.84 0.84 225
CART: Temps de formation pour DecisionTreeClassifier() 0.32616000000001577 0.8266666666666667 [[147 18] [ 21 39]] précision rappel f1 score support 0 0.88 0.89 0.88 165 1 0.68 0.65 0.67 60 exactitude 0.83 225 moyenne macro 0.78 0.77 0.77 225 moyenne pondérée 0.82 0.83 0.83 225
NB: Temps de formation pour GaussianNB() 0.0034229999999979555 0.8355555555555556 [[154 11] [ 26 34]] précision rappel f1 score support 0 0.86 0.93 0.89 165 1 0.76 0.57 0.65 60 exactitude 0.84 225 moyenne macro 0.81 0.75 0.77 225 moyenne pondérée 0.83 0.84 0.83 225
SVM: Temps de formation pour SVC(gamma='auto') 0.3596520000000112 0.8977777777777778 [[157 8] [ 15 45]] précision rappel f1 score support 0 0.91 0.95 0.93 165 1 0.85 0.75 0.80 60 exactitude 0.90 225 moyenne macro 0.88 0.85 0.86 225 moyenne pondérée 0.90 0.90 0.90 225
RF: Temps de formation pour RandomForestClassifier() 0.50123099999999 0.9066666666666666 [[158 7] [ 14 46]] précision rappel f1 score support 0 0.92 0.96 0.94 165 1 0.87 0.77 0.81 60 exactitude 0.91 225 moyenne macro 0.89 0.86 0.88 225 moyenne pondérée 0.91 0.91 0.90 225
XGB: Temps de formation pour XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1, importance_type='gain', interaction_constraints='', learning_rate=0.300000012, max_delta_step=0, max_depth=6, min_child_weight=1, missing=nan, monotone_constraints='()', n_estimators=100, n_jobs=0, num_parallel_tree=1, random_state=0, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1, tree_method='exact', validate_parameters=1, verbosity=Aucun) 1.649520999999993 0.8844444444444445 [[155 10] [ 16 44]] précision rappel f1 score support 0 0.91 0.94 0.92 165 1 0.81 0.73 0.77 60 exactitude 0.88 225 moyenne macro 0.86 0.84 0.85 225 moyenne pondérée 0.88 0.88 0.88 225
Le résultat semble être que RF est en fait meilleur que XGB. Cela pourrait signifier que XGB est peut-être un peu plus surajouté d'une manière ou d'une autre. Le résultat de RFC est également légèrement meilleur que celui de LR.
Exécuter le modèle sélectionné en poursuivant "Ajustement des paramètres via la recherche par quadrillage"
Supposons maintenant que nous ayons choisi le modèle de classificateur de la forêt aléatoire "Random Forest Classifier". Nous pouvons effectuer une nouvelle recherche sur la grille de ce modèle pour voir s'il est possible d'obtenir des résultats un peu plus performants.
Rappelez-vous que notre objectif est toujours d'optimiser le rappel dans ce cas, en minimisant le nombre de faux négatifs concernant les risques possibles pour l'USI lors de la rencontre avec le patient, nous utiliserons donc 'recall_score' pour réajuster le quadrillage ci-dessous. Une fois de plus, la validation croisée 10 fois sera utilisée comme d'habitude, étant donné que notre ensemble de test ci-dessus a toujours été fixé à environ 12 % de ces 2915 enregistrements.
from sklearn.model_selection import GridSearchCVCréer la grille de paramètres sur la base des résultats de la recherche aléatoire
param_grid = {'bootstrap': [Vrai], 'ccp_alpha': [0.0], 'class_weight': [Aucun], 'criterion': ['gini', 'entropy'], 'max_depth': [Aucun], 'max_features': ['auto', 'log2'],
'max_leaf_nodes': [Aucun], 'max_samples': [Aucun], 'min_impurity_decrease': [0.0], 'min_impurity_split': [Aucun], 'min_samples_leaf': [1, 2, 4], 'min_samples_split': [2, 4], 'min_weight_fraction_leaf': [0.0], 'n_estimators': [100, 125], #'n_jobs': [Aucun], 'oob_score': [False], 'random_state': [Aucun], #'verbose': 0, 'warm_start': [False] }
#Ajuster par matrice de confusion from sklearn.metrics import roc_curve, précision_recall_curve, auc, make_scorer, recall_score, accuracy_score, précision_score, confusion_matrix scorers = { 'recall_score': make_scorer(recall_score), 'précision_score': make_scorer(précision_score), 'accuracy_score': make_scorer(accuracy_score) }
# Créer un modèle de base rfc = RandomForestClassifier()Instancier le modèle de quadrillage
grid_search = GridSearchCV(estimator = rfc, param_grid = param_grid, scoring=scorers, refit='recall_score', cv = 10, n_jobs = -1, verbose = 2)
train_features = X_train_resgrid_search.fit(train_features, train_labels)rf_best_grid = grid_search.best_estimator_rf_best_grid.fit(train_features, train_labels) rf_predictions = rf_best_grid.predict(X3_test) print(accuracy_score(y3_test, rf_predictions))
print(confusion_matrix(y3_test, rf_predictions)) print(classification_report(y3_test, rf_predictions))

0.92 [[ 46 14] [ 4 161]] précision rappel f1 score support 0 0.92 0.77 0.84 60 1 0.92 0.98 0.95 165 exactitude 0.92 225 moyenne macro 0.92 0.87 0.89 225 moyenne pondérée 0.92 0.92 0.92 225
Le résultat a montré qu'un quadrillage a permis d'augmenter légèrement la précision globale, tout en maintenant le FN au même niveau.
Traçons également les comparaisons avec l'ASC :
confusion_matrix4 = pd.crosstab(y3_test, rf_predictions, rownames=['Actual'], colnames=['Predicted']) sns.heatmap(confusion_matrix4, annot=Vrai, fmt = 'g', cmap="YlOrBr")print("LABEL ENCODING + STRATIFY") print(classification_report(y3_test, 1-y3_hat)) print("ASC = ",roc_auc_score(y3_test, 1-y3_hat),'\n\n')print("SMOTE") print(classification_report(y3_test, 1-y_res_hat)) print("ASC = ",roc_auc_score(y3_test, 1-y_res_hat), '\n\n')print("SMOTE + LBG Selected Weights + RF Grid Search") print(classification_report(y3_test, rf_predictions)) print("ASC = ",roc_auc_score(y3_test, rf_predictions), '\n\n\n')
y_res_hat_probs = LR.predict_proba(X3_test) y_res_hat_probs = y_res_hat_probs[:, 1]
predictions_rf_probs = rf_best_grid.predict_proba(X3_test) #(X_validation) predictions_rf_probs = predictions_rf_probs[:, 1]
fpr_res, tpr_res, _ = roc_curve(y3_test, 1-y_res_hat_probs) fpr_rf_res, tpr_rf_res, _ = roc_curve(y3_test, predictions_rf_probs)
plt.figure(figsize=(10,10)) plt.plot([0, 1], [0, 1], 'k--') plt.plot(fpr, tpr, label="Base") plt.plot(fpr2,tpr2,label="Label Encoded") plt.plot(fpr3,tpr3,label="Stratify") plt.plot(fpr_res,tpr_res,label="SMOTE") plt.plot(fpr_rf_res,tpr_rf_res,label="SMOTE + RF GRID") plt.xlabel('False positive rate') plt.ylabel('Vrai positive rate') plt.title('ROC curve') plt.legend(loc="best") plt.show()
CODAGE D'ÉTIQUETTES + STRATIFICATION précision rappel f1 score support 0 0.95 0.58 0.72 60 1 0.87 0.99 0.92 165 exactitude 0.88 225 moyenne macro 0.91 0.79 0.82 225 moyenne pondérée 0.89 0.88 0.87 225 ASC = 0.7856060606060606MODIFICATION précision rappel f1 score support 0 0.69 0.75 0.72 60 1 0.91 0.88 0.89 165 exactitude 0.84 225 moyenne macro 0.80 0.81 0.81 225 moyenne pondérée 0.85 0.84 0.85 225 ASC = 0.8143939393939394
MODIFICATION + LBG Pondérations sélectionnées + Quadrillage RF précision rappel f1 score support 0 0.92 0.77 0.84 60 1 0.92 0.98 0.95 165 exactitude 0.92 225 moyenne macro 0.92 0.87 0.89 225 moyenne pondérée 0.92 0.92 0.92 225 ASC = 0.8712121212121211

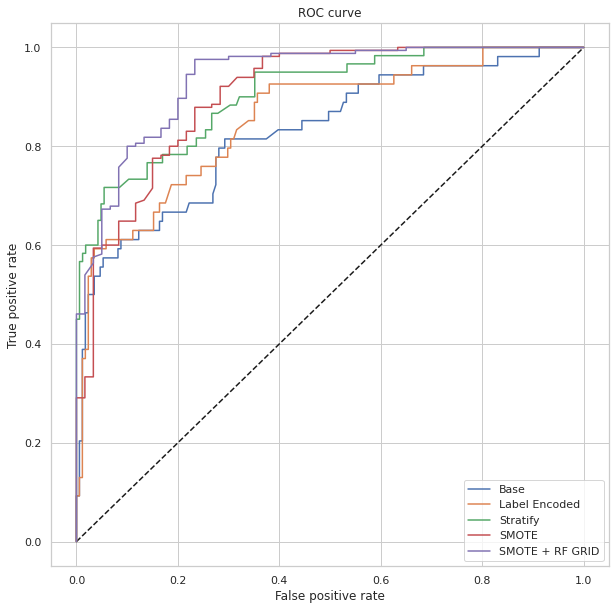
Le résultat a montré qu'après des comparaisons d'algorithmes et un quadrillage suivant, nous avons réussi à faire passer l'ASC de 78 % à 87 %, avec une précision globale de 92 % et un rappel de 77 %.
Récapitulatif de l'approche "ML traditionnelle"
Qu'en est-il réellement de ce résultat ? Il est correct pour un processus manuel de base avec des algorithmes ML traditionnels. Comment ce résultat apparaît-il dans les tableaux de compétition Kaggle ? Eh bien, il ne figurerait pas dans le tableau de classement. J'ai passé le jeu de données brutes par le service AutoML actuel de DataRobot, le meilleur résultat serait un ASC équivalent de ~90+% (à confirmer avec des données similaires) avec le modèle " Classificateur arborescent XGB avec fonctions d'apprentissage non supervisé " (XGB Trees Classifier with Unsupervised Learning Features), sur une comparaison des 43 meilleurs modèles. C'est peut-être le genre de modèle de base que nous devrions utiliser si nous voulons vraiment être compétitifs sur Kaggle. Je joindrai également la liste des meilleurs résultats par rapport aux modèles dans le github. Finalement, pour les cas réels spécifiques aux sites de soins, j'ai le sentiment que nous devons également intégrer un certain degré d'approches d'apprentissage profond personnalisées, comme mentionné dans la section "Données et tâches" de ce billet. Bien sûr, dans les cas réels, l'endroit où collecter des colonnes de données de qualité pourrait également être une question initiale.
L'approche IntegratedML?
Ce qui précède est un processus de ML dit traditionnel, qui comprend normalement l'EDA des données, l'ingénierie des caractéristiques, la sélection des caractéristiques, la sélection des modèles, et l'optimisation des performances par la quadrillage, etc. C'est l'approche la plus simple à laquelle j'ai pu penser jusqu'à présent pour cette tâche, et nous n'avons même pas encore abordé le déploiement du modèle et les cycles de vie de la gestion des services - nous le ferons dans le prochain article, en examinant comment nous pourrions tirer parti de Flask/FastAPI/IRIS et déployer ce modèle de ML de base dans une pile de services de démonstration de la radiographie de Covid-19.
IRIS dispose désormais d'IntegratedML, qui est une enveloppe SQL élégante d'options puissantes d'AutoMLs. Dans la deuxième partie, nous verrons comment accomplir la tâche susmentionnée dans le cadre d'un processus simplifié, de sorte que nous n'aurons plus à nous préoccuper de la sélection des caractéristiques, de la sélection des modèles, de l'optimisation des performances, etc.
Jusqu'ici, cet article pourrait être trop long pour une note de 10 minutes visant à intégrer rapidement les mêmes données, c'est pourquoi je le déplace vers l'article suivant, partie II.