 Par vues
Par vues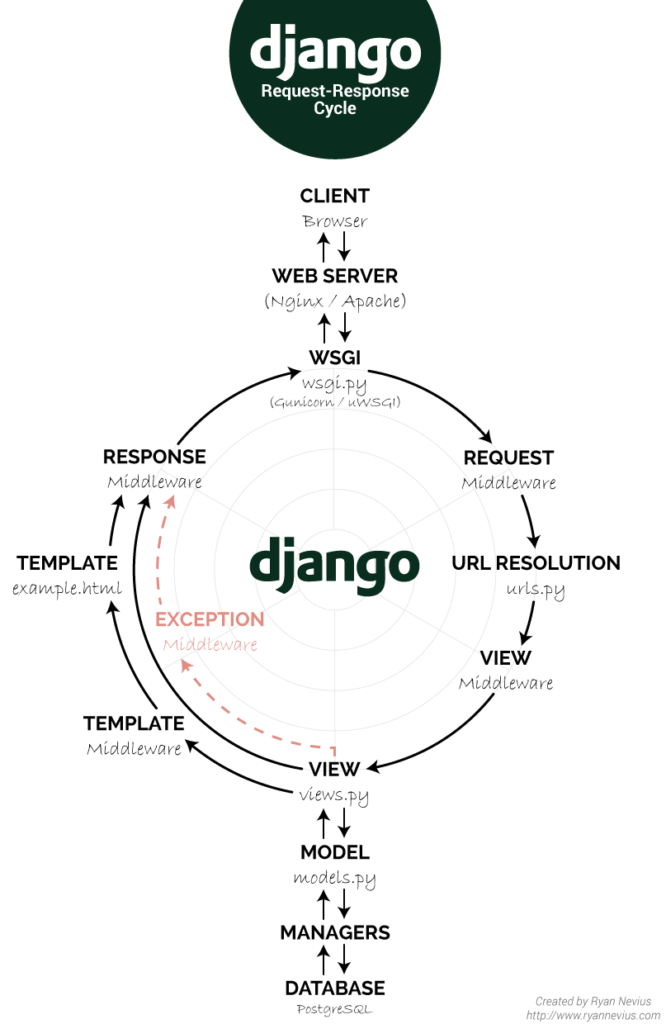

 Open Exchange app
Open Exchange app
Pourquoi normaliser les données ?

La normalisation des données au sein d’un EDS est fondamentale pour en assurer une bonne exploitation.
Les données capturées de différentes sources et dans différents formats doivent être saines avant d’être stockées c’est à dire unifiées, nettoyées et prêtes à être exploitées.
Les grandes étapes de normalisation des données sont :
- Agrégation
- Rapprochement
- Déduplication
- Alignement terminologique
.png)


.png)

