https://www.youtube.com/embed/3BivXX1gImQ [Ceci est un lien intégré, mais vous ne pouvez pas consulter le contenu intégré directement sur le site car vous avez refusé les cookies nécessaires pour y accéder. Pour afficher le contenu intégré, vous devez accepter tous les cookies dans vos Paramètres des cookies]
Aujourd'hui, il y a beaucoup de bruit autour du LLM, de l'IA, etc. Les bases de données vectorielles en font partie, et il existe déjà de nombreuses réalisations différentes pour le support en dehors d'IRIS.
Pourquoi Vector?
Recherche de similarité : Les vecteurs assurent une recherche de similarité efficace, par exemple en trouvant les éléments ou les documents les plus similaires dans un ensemble de données. Les bases de données relationnelles classiques sont conçues pour des recherches de correspondances exactes, qui ne sont pas adaptées à des tâches telles que la recherche de similitudes d'images ou de textes.
Flexibilité : Les représentations vectorielles sont polyvalentes et peuvent être obtenues à partir de différents types de données, tels que du texte (via des embeddings comme Word2Vec, BERT), des images (via des modèles d'apprentissage profond), et autres.
Recherches multimodales** : Les vecteurs permettent d'effectuer des recherches dans différentes modalités de données. Par exemple, avec une représentation vectorielle d'une image, on peut rechercher des images similaires ou des textes connexes dans une base de données multimodale.
Et pour bien d'autres raisons encore.
Donc, pour ce concours python, j'ai décidé de mettre en place ce support. Et malheureusement, je n'ai pas réussi à le terminer à temps, je vais vous expliquer pourquoi.
Imaginons que vous soyez un développeur en Python ou que vous disposiez d'une équipe bien formée et spécialisée en Python, mais que le délai qui vous est imparti pour analyser certaines données dans IRIS soit serré. Bien sûr, InterSystems offre de nombreux outils pour toutes sortes d'analyses et de traitements. Cependant, dans le scénario donné, il est préférable de faire le travail en utilisant le bon vieux Pandas et de laisser IRIS pour une autre fois.
Pour le prochain Concours Python, j'aimerais faire une petite démo, sur la création d'une simple application REST en Python, qui utilisera IRIS comme base de données. Et utiliser les outils suivants
Le cadre FastAPI, très performant, facile à apprendre, rapide à coder, prêt pour la production.
SQLAlchemy est la boîte à outils SQL et le Mapping objet-relationnel de Python qui donne aux développeurs en Python toute la puissance et la flexibilité de SQL.
Alembic est un outil léger de migration de base de données à utiliser avec le SQLAlchemy Database Toolkit pour Python.
Uvicorn est une implémentation de serveur web ASGI pour Python.
Cette publication soutient la démonstration au Global Summit 2023 "Demos and Drinks" avec des détails très probablement perdus dans le bruit de l'événement.
La personnalisation des procédures stockées en ObjectScript s'est avérée utile pour accéder au stockage NoSQL et à la messagerie externe via l'intégration, afin de présenter la sortie sous forme de tableau.
Actuellement, les privilèges SQL (SELECT, INSERT, UPDATE, DELETE) sont gérés au niveau des tables, ce qui peut s'avérer très fastidieux lorsque vous devez administrer de nombreux rôles dans une organisation et les synchroniser avec des modèles de données en constante évolution. En gérant les privilèges au niveau des schémas, cela permettra d'accorder des privilèges SELECT et d'autres privilèges DML à *tous* ou *plusieurs schémas* à un rôle|utilisateur, corrigeant ainsi le besoin de synchroniser manuellement les nouvelles tables|vues avec les rôles.
J'ai une globale dont la structure est à plusieurs niveaux et j'essaie à travers une class et une requête SQL d'afficher un tableau qui comprend toutes les valeurs et les niveaux.
Imaginons que vous soyez un développeur Python ou que vous disposiez d'une équipe bien formée et spécialisée en Python, mais que le délai dont vous disposez pour analyser certaines données dans IRIS est serré. Bien entendu, InterSystems propose de nombreux outils pour toutes sortes d’analyses et de traitements. Cependant, dans le scénario donné, il est préférable de faire le travail en utilisant les bons vieux Pandas et de laisser l'IRIS pour une autre fois.
Je recherche dans DBeaver un moyen efficace permettant de filtrer les tables systèmes (ex: appartenant à un schéma commençant par "%").
En utilisant un utilisateur possédant le rôle %All, DBeaver nous affiche une longue liste de schémas systèmes, qui nous oblige à descendre la liste avant d'accéder aux tables utilisateurs.
En créant un utilisateur dans IRIS avec des droits restreints permet de réduire cette liste, mais on perd l'intérêt du rôle %All.
Nous sommes heureux d'annoncer que DBeaver prend en charge InterSystems IRIS dès la version 7.2.4. Vous n'avez plus besoin de le configurer manuellement, recherchez simplement l'icône IRIS dans la liste des connexions.
Est-il prévu que LOAD DATA prenne en compte plusieurs formats de DATE/DATETIME avec, par exemple un paramètre de indiquant le format utilisé dans les données sources ?
exemple :
LOAD DATA .../...
USING
{
"from": {
"file": {
"dateformat": "DD/MM/YYYY"
}
}
}
InterSystems IRIS Cloud SQL est un service cloud entièrement géré qui apporte la puissance des capacités de base de données relationnelles d'InterSystems IRIS utilisées par des milliers d'entreprises clientes à un large public de développeurs d'applications et de professionnels des données. InterSystems IRIS Cloud IntegratedML est une option de cette base de données en tant que service qui offre un accès facile à de puissantes capacités d'apprentissage automatique automatisé sous une forme SQL native, via un ensemble de commandes SQL simples qui peuvent facilement être intégrées dans le code d'application pour augmenter avec des modèles ML qui s'exécutent près des données.
Aujourd'hui, nous annonçons le programme d'accès pour les développeurs pour ces deux offres. Les développeurs d'applications peuvent désormais s'inscrire eux-mêmes au service, créer des déploiements et commencer à créer des applications composables et des services de données intelligents, l'approvisionnement, la configuration et l'administration étant entièrement pris en charge par le service.
La semaine dernière, lors du Global Summit, nous avons annoncé notre nouvelle fonctionnalité Foreign Tables, qui a été introduite en tant que fonctionnalité expérimentale avec la version 2023.1 plus tôt cette année.
Dans certains des derniers articles, j'ai parlé des types entre IRIS et Python, et il est clair qu'il n'est pas facile d'accéder aux objets d'un côté à l'autre.
Heureusement, un travail a déjà été fait pour créer SQLAlchemy-iris (suivez le lien pour le voir sur Open Exchange), qui rend tout beaucoup plus facile pour Python d'accéder aux objets d'IRIS, et je vais montrer les starters pour cela.
Apache Superset est une plate-forme moderne d'exploration et de visualisation des données. Superset peut remplacer ou augmenter les outils de business intelligence propriétaires pour de nombreuses équipes. Superset s'intègre bien à une variété de sources de données.
Désormais, il est également possible de l'utiliser avec InterSystems IRIS.
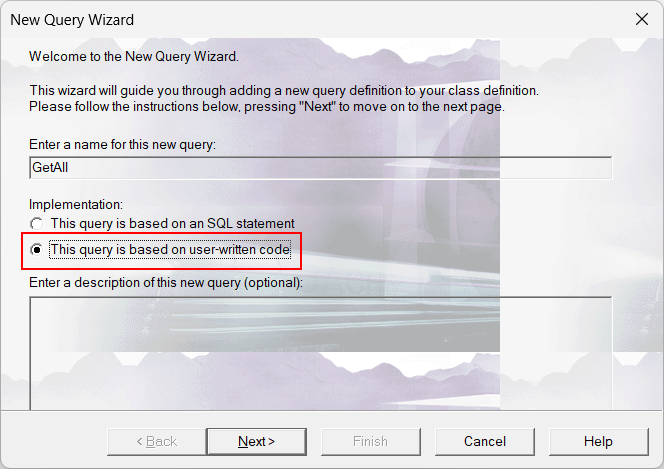
Dans ce didacticiel, j'aimerais parler des requêtes de classe (Class Query). Pour être plus précis, à propos des requêtes basées sur du code écrit par l'utilisateur :
J'ai récemment remarqué un jeu de données Kaggle permettant de prédire si un patient Covid-19 sera admis en soins intensifs. Il s'agit d'un tableur de 1925 enregistrements comprenant 231 colonnes de signes vitaux et d'observations, la dernière colonne " USI " valant 1 pour Oui ou 0 pour Non.
Nous aimerions vous inviter à participer à notre prochain concours dédié à la création des solutions d'IA/ML qui utilisent Cloud SQL pour travailler avec les données :
Voici un deuxième article de la série et celui-ci est dédié à SQL. Donc, si vous voulez en savoir plus sur l'utilisation du modèle relationnel dans IRIS, consultez les articles mentionnés.
Je vous présente mon nouveau projet, qui est irissqlcli, REPL (Read-Eval-Print Loop) pour InterSystems IRIS SQL
Mise en évidence de la syntaxe
Suggestions (tableaux, fonctions)
Plus de 20 formats de sortie
Support de stdin
Sortie vers des fichiers
L'installez avec pip
pip install irissqlcli
Ou lancez avec docker
docker run -it caretdev/irissqlcli irissqlcli iris://_SYSTEM:SYS@host.docker.internal:1972/USER
Connection à IRIS
$ irissqlcli iris://_SYSTEM@localhost:1972/USER -W
Password for _SYSTEM:
Server: InterSystems IRIS Version 2022.3.0.606 xDBC Protocol Version 65
Version: 0.1.0
[SQL]_SYSTEM@localhost:USER> select $ZVERSION
+---------------------------------------------------------------------------------------------------------+
| Expression_1 |
+---------------------------------------------------------------------------------------------------------+
| IRIS for UNIX (Ubuntu Server LTS for ARM64 Containers) 2022.3 (Build 606U) Mon Jan 30202309:05:12 EST |
+---------------------------------------------------------------------------------------------------------+
1 row in set
Time: 0.063s
[SQL]_SYSTEM@localhost:USER> help
+----------+-------------------+------------------------------------------------------------+
| Commande | Raccourci | Description |
+----------+-------------------+------------------------------------------------------------+
| .exit | \q | Sortie. |
| .mode | \T | Modifier le format de tableau utilisé pour les résultats. |
| .once | \o [-o] filename | Ajout du résultat suivant à un fichier de sortie (écraser en utilisant -o). |
| .schemas | \ds | Liste des schémas. |
| .tables | \dt [schema] | Liste des tableaux. |
| \e | \e | Commande d'édition avec éditeur (utilise $EDITOR). |
| help | \? | Montre cette utilité. |
| nopager | \n | Désactiver le pager, imprimer vers stdout. |
| notee | notee | Arrête l'écriture des résultats dans un fichier de sortie. |
| pager | \P [command] | Definition du PAGER. Impression des résultats de la requête via PAGER. |
| prompt | \R | Modification du format de l'invite. |
| quit | \q | Quit. |
| tee | tee [-o] filename | Ajout de tous les résultats à un fichier de sortie (écraser en utilisant -o). |
+----------+-------------------+------------------------------------------------------------+
Time: 0.012s
[SQL]_SYSTEM@localhost:USER>
Avec InterSystems IRIS 2022.2, nous avons introduit le stockage en colonne comme une nouvelle option pour la persistance de vos tables IRIS SQL qui peut booster vos requêtes analytiques d'un ordre de grandeur. La capacité est marquée comme expérimentale dans les versions 2022.2 et 2022.3, mais passera à une capacité de production entièrement prise en charge dans la prochaine version 2023.1.
La documentation du produit et cette vidéo d'introduction, décrivent déjà les différences entre le stockage en ligne, toujours la valeur par défaut sur IRIS et utilisé dans l'ensemble de notre clientèle, et le stockage en table en colonnes et fournissent des conseils de haut niveau sur le choix de la disposition de stockage appropriée pour votre cas d'utilisation. Dans cet article, nous développerons ce sujet et partagerons quelques recommandations basées sur les principes de modélisation des pratiques de l'industrie, les tests internes et les commentaires des participants au Early Access Program.
Comme vous vous en souvenez peut-être du Global Summit 2022 ou du webinaire de lancement 2022.2, nous lançons une nouvelle fonctionnalité passionnante à inclure dans vos solutions d'analyse sur InterSystems IRIS. Le stockage en colonnes introduit une autre façon de stocker vos données de table SQL qui offre une accélération d'ordre de grandeur pour les requêtes analytiques. Publié pour la première fois en tant que fonctionnalité expérimentale en 2022.2, le dernier Developer Preview 2022.3 comprend un tas de mises à jour qui, selon nous, valaient la peine d'être publiées ici.
J'essaie d'obtenir un compte de type de message spécifique avec une entrée spécifique et j'ai pensé que je pourrais construire la requête dans Message Viewer mais cela ne fournit pas de comptes (pour autant que je sache). Ainsi, lorsque je prends le SQL à partir de "Show Query", il omet les critères de segment comme le montre le code ci-dessous.
J'ai attaché les critères qui ont été exclus. Est-ce possible ?
Bonjour à tous, c'est avec grand plaisir que je vous annonce la V2 de mon application 'Contest-FHIR'.
Dans cette nouvelle version, j'ai utilisé de nouveaux outils et techniques que j'ai découverts lors de l'EUROPEAN HEALTHCARE HACKATHON auquel j'ai été invité par InterSystems en tant qu'invité et mentor pour présenter les multiples projets que j'ai réalisés lors de mon stage en avril 2022.
Aujourd'hui je vous présente la V2 de mon application, elle peut maintenant transformer un fichier CSV en FHIR en SQL en JUPYTER notebook.
Je veux faire une requête dans la base de données du Caché pour trouver les messages où un segment HL7 spécifique est égal à une valeur spécifique. Caché dispose-t-il d'une fonction d'interrogation de type "pipe to XML" ou "segment HL7" ?
Nous essayons de trouver la source des messages abandonnés et avons remarqué que nous sommes incapables d'interroger EnsLib.HL7.Message avec des clauses WHERE ou ORDER BY dans notre instruction SQL.
Je sais que EnsLib.HL7.Message est un tableau système, mais existe-t-il un moyen d'ajouter des index supplémentaires à ce tableau pour que la requête s'exécute mieux/plus rapidement sans affecter le système ?
Et pour discuter de toutes les fonctionnalités nouvelles et améliorées de celui-ci, nous aimerions vous inviter à notre webinaire Quoi de neuf dans InterSystems IRIS 2022.2.
 Par date
Par date

 Open Exchange app
Open Exchange app.png)
.png)
.png)
.png)