Salut la Communauté !
Voici un deuxième article de la série et celui-ci est dédié à SQL. Donc, si vous voulez en savoir plus sur l'utilisation du modèle relationnel dans IRIS, consultez les articles mentionnés.
Salut la Communauté !
Voici un deuxième article de la série et celui-ci est dédié à SQL. Donc, si vous voulez en savoir plus sur l'utilisation du modèle relationnel dans IRIS, consultez les articles mentionnés.
Salut la Communauté !
Si le sujet FHIR vous intéresse, vous trouverez ci-dessous une sélection d'articles intéressants qui aideront les débutants à le comprendre et à approfondir les connaissances de ceux qui l'utilisent déjà.
| Nom de l'article | De quoi s'agit-il | |
| 1. | Bibliothèque de SMART sur FHIR JS et les exemples dans iris-on-fhir | Cet article décrit une bibliothèque JS pour accéder aux ressources FHIR avec deux exemples d'utilisation. |
| 2. | Présentation d'IRIS sur FHIR | Cet article montre en exemple d'utilisation de FHIR. |
| 3. |
Avec InterSystems IRIS 2022.2, nous avons introduit le stockage en colonne comme une nouvelle option pour la persistance de vos tables IRIS SQL qui peut booster vos requêtes analytiques d'un ordre de grandeur. La capacité est marquée comme expérimentale dans les versions 2022.2 et 2022.3, mais passera à une capacité de production entièrement prise en charge dans la prochaine version 2023.1.
La documentation du produit et cette vidéo d'introduction, décrivent déjà les différences entre le stockage en ligne, toujours la valeur par défaut sur IRIS et utilisé dans l'ensemble de notre clientèle, et le stockage en table en colonnes et fournissent des conseils de haut niveau sur le choix de la disposition de stockage appropriée pour votre cas d'utilisation. Dans cet article, nous développerons ce sujet et partagerons quelques recommandations basées sur les principes de modélisation des pratiques de l'industrie, les tests internes et les commentaires des participants au Early Access Program.
Comme vous vous en souvenez peut-être du Global Summit 2022 ou du webinaire de lancement 2022.2, nous lançons une nouvelle fonctionnalité passionnante à inclure dans vos solutions d'analyse sur InterSystems IRIS. Le stockage en colonnes introduit une autre façon de stocker vos données de table SQL qui offre une accélération d'ordre de grandeur pour les requêtes analytiques. Publié pour la première fois en tant que fonctionnalité expérimentale en 2022.2, le dernier Developer Preview 2022.3 comprend un tas de mises à jour qui, selon nous, valaient la peine d'être publiées ici.
Salut les Devs !
Pour moi, l'une des choses les plus pénibles à propos d'ObjectScript est de taper ##class(Class).Method() pour appeler une méthode de classe dans le code ou dans un terminal. J'ai même soumis une idée pour le simplifier en ObjectScript.
Mais! Il y a une nouvelle fonctionnalité dans VSCode ObjectScript qui vient d'être introduite dans le plugin - Copy Invocation !
Passez simplement le curseur sur le lien Copy Invocation au-dessus de chaque méthode de classe dans un code, cliquez dessus et l'invocation est copiée dans le buffer:
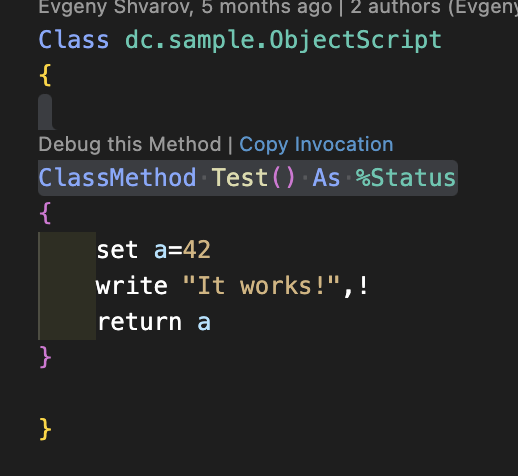
Collez-le où vous voulez qu'il s'exécute !
Comme vous l'avez probablement remarqué, la documentation en ligne de produits a énormément progressé ces dernières années. Parmi les nombreuses améliorations sous le capot, la documentation est devenue plus facile à lire et à naviguer. Et nous avons maintenant un puissant moteur de recherche qui vous permet d'accéder à ce dont vous avez besoin avec plus de précision que nous ne pourrions jamais le faire avec l'ancien système de documentation.
Salut la Communauté!
Parce que je n'avais aucune idée de comment construire une solution d'intégration pour HL7 et que je ne savais pas par où commencer, j'ai décidé de suivre le cours Building Basic HL7 Integrations with InterSystems sur le portail d’apprentissage en ligne InterSystems Learning pour avoir au moins l'idée par où commencer. Après avoir tout étudié, j'ai décidé que ce serait peut-être une bonne idée de partager mes pensées et mes réflexions à ce cours avec tout le monde.

Dans l'article précédent, nous avons vu le contenu du message ORM et du message de réponse ORU. Examinons maintenant de plus près le message ACK.
Chaque fois qu'une application réceptrice accepte un message et consomme les données du message, elle est censée renvoyer un message ACKnowledgement (ACK) à l'application émettrice. L'application émettrice est censée continuer à envoyer un message jusqu'à ce qu'elle ait reçu un message ACK. C'est une partie importante de la norme HL7, le protocole de la confirmation de réception.
.png)
Dans l'article précédent, nous avons vu le contenu du message ADT et un exemple de ADT^A04 avec toutes ses segments. Examinons maintenant de plus près d'autres types de messages largement utilisés comme ORM et le message de réponse ORU.
.png)
Dans l'article précédent, nous avons passé en revue les informations générales sur la norme HL7v2. Parlons maintenant de l'un des types de messages utilisés - ADT.
.png)
Messages HL7 ADT - Admission, sortie et transfert - sont utilisés pour communiquer les données démographiques des patients, les informations sur les visites et l'état du patient dans un établissement de santé.

HL7 (Health Level 7) est un ensemble de spécifications techniques pour les échanges informatisés de données cliniques, financières et administratives entre systèmes d'information hospitaliers (SIH). Ces spécifications sont diversement intégrées au corpus des normes formelles américaines (ANSI) et internationales (ISO).
La norme HL7 version 2 (également connue sous le nom de Pipehat) a pour objectif de prendre en charge les flux de travail hospitaliers. Il a été initialement créé en 1989.
Pour parler des différentes bases de données et des différents modèles de données qui existent, on doit premièrement comprendre ce qui est une base de données et comment les utiliser.
Une base de données est une collection organisée de données stockées et accessibles par voie électronique. Elle permet de stocker et de retrouver des données structurées, semi-structurées ou des données brutes souvent en rapport avec un thème ou une activité.
Au cœur de chaque base de données se trouve au moins un modèle utilisé pour décrire ses données. Et selon le modèle sur lequel elle est basée, elle peut avoir des caractéristiques un peu différentes et stocker différents types de données.
Pour inscrire, retrouver, modifier, trier, transformer ou imprimer les informations de la base de données on utilise un logiciel qui s’appelle système de gestion de base de données (SGBD, en anglais DBMS pour Database management system).
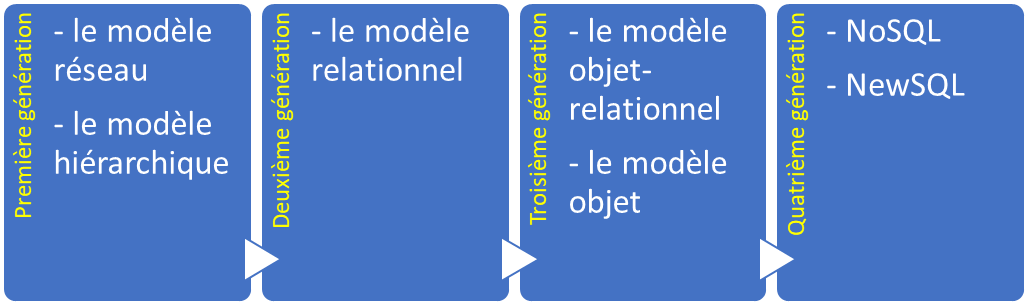
La taille, les capacités et les performances des bases de données et de leurs SGBD respectifs ont augmenté de plusieurs ordres de grandeur. Ces augmentations de performances ont été rendues possibles par les progrès technologiques dans différents domaines, tels que les domaines des processeurs, de la mémoire informatique, du stockage informatique et des réseaux informatiques. Le développement ultérieur de la technologie des bases de données peut être divisé en quatre générations basées sur le modèle ou la structure des données : navigation, relationnel, objet et post-relationnel.

Dans le premier article de cette série, nous avons vu comment lire un "gros" volume de données dans le corps brut d'une méthode HTTP POST et l'enregistrer dans une base de données en tant que propriété de flux d'une classe. Le deuxième article explique comment enregistrer des fichiers et leurs noms dans un format JSON.
Examinons maintenant de plus près l'idée d'envoyer des fichiers volumineux par parties au niveau du serveur. Il existe plusieurs approches que nous pouvons utiliser pour y parvenir. Cet article traite de l'utilisation de l'en-tête Transfer-Encoding pour indiquer un transfert par blocs. La spécification HTTP/1.1 a introduit l'en-tête Transfer-Encoding, et RFC 7230, section 4.1 l'a décrit, mais il n'est pas mentionné dans la spécification HTTP/2.
Dans le premier article de cette série, nous avons vu comment lire un "gros" volume de données dans le corps brut d'une méthode HTTP POST et l'enregistrer dans une base de données en tant que propriété de flux d'une classe. Voyons maintenant comment enregistrer de telles données et métadonnées au format JSON.
Une question a été posée dans la communauté des développeurs d'InterSystems concernant la possibilité de créer une interface TWAIN pour une application Caché. Il y a eu plusieurs suggestions intéressantes sur la façon d'obtenir des données d'un périphérique d'acquisition d'images sur un client Web vers un serveur, puis de stocker ces données dans une base de données
Toutefois, pour mettre en œuvre l'une de ces suggestions, vous devez être en mesure de transférer des données d'un client Web vers un serveur de base de données et de stocker les données reçues dans une propriété de classe (ou une cellule de tableau, comme c'était le cas dans la question). Cette technique peut être utile non seulement pour transférer des données d'images provenant d'un périphérique TWAIN, mais aussi pour d'autres tâches telles que l'organisation d'une archive de fichiers, d'un partage d'images, etc.
Ainsi, l'objectif principal de cet article est de montrer comment écrire un service RESTful pour obtenir des données du corps d'une commande HTTP POST, soit à l'état brut, soit enveloppées dans une structure JSON.

Quand on travaille avec les globales, on voit qu’il n’y a pas mantes fonction en ObjectScript (COS) à utiliser. C’est aussi le cas avec Python et Java. Toutefois, toutes ses fonctions sont indispensables quand on travaille directement avec les données sans utilisation des objets, des documents ou des tables.
Dans cet article je voudrais parler de différentes fonctions et commandes qui se servent à travailler avec les globales dans trois langues : ObjectScript, Python et Java (les deux derniers en utilisant Native API).