 Par vues
Par vues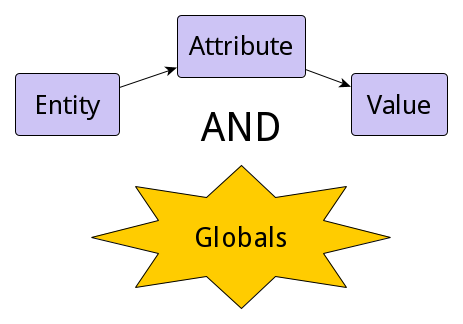
 Open Exchange app
Open Exchange appPour parler des différentes bases de données et des différents modèles de données qui existent, on doit premièrement comprendre ce qui est une base de données et comment les utiliser.
Une base de données est une collection organisée de données stockées et accessibles par voie électronique. Elle permet de stocker et de retrouver des données structurées, semi-structurées ou des données brutes souvent en rapport avec un thème ou une activité.
Au cœur de chaque base de données se trouve au moins un modèle utilisé pour décrire ses données. Et selon le modèle sur lequel elle est basée, elle peut avoir des caractéristiques un peu différentes et stocker différents types de données.
Pour inscrire, retrouver, modifier, trier, transformer ou imprimer les informations de la base de données on utilise un logiciel qui s’appelle système de gestion de base de données (SGBD, en anglais DBMS pour Database management system).
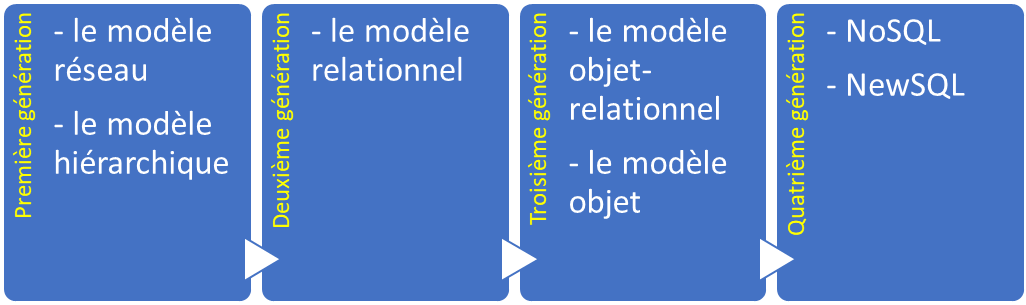
La taille, les capacités et les performances des bases de données et de leurs SGBD respectifs ont augmenté de plusieurs ordres de grandeur. Ces augmentations de performances ont été rendues possibles par les progrès technologiques dans différents domaines, tels que les domaines des processeurs, de la mémoire informatique, du stockage informatique et des réseaux informatiques. Le développement ultérieur de la technologie des bases de données peut être divisé en quatre générations basées sur le modèle ou la structure des données : navigation, relationnel, objet et post-relationnel.
.png)


.png)

.png)