Comment rendre persistantes des données XML dans une base de données IRIS à l'aide de l'Interopérabilité d'IRIS ?
InterSystems IRIS dispose d'une série de dispositifs facilitant la capture, la persistance, l'interopérabilité et la génération d'informations analytiques à partir de données au format XML. Cet article vous montrera comment procéder:
- Capture du XML (via un fichier dans notre exemple);
- Traitement des données capturées en interopérabilité;
- Persistance du XML dans les entités/tables persistantes;
- Création des vues analytiques pour les données XML capturées.
Capture des données XML
L'InterSystems IRIS dispose de nombreux adaptateurs intégrés pour capturer des données, notamment les suivants:
- Adaptateur de fichiers : utilisé pour obtenir des fichiers à partir de dossiers de réseau.
- Adaptateur FTP : utilisé pour obtenir des fichiers à partir de serveurs FTP/SFTP.
- Adaptateur SOAP/Services Web : utilisé pour recevoir des données XML à partir d'opérations de services Web.
- Adaptateurs HTTP: utilisés pour acquérir des données et des fichiers XML à partir de points de terminaison HTTP.
- D'autres adaptateurs peu courants pour obtenir des données XML, par exemple des adaptateurs de messagerie. Vous pouvez les trouver à l'adresse suivante http://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_interop_protocols.
Pour capturer des données à l'aide de productions d'interopérabilité, il faut configurer une production et utiliser un service métier Business Service associé à un adaptateur approprié. Les services métier les plus courants sont énumérés ci-dessous:
- EnsLib.XML.Object.Service.FileService. C'est l'option que je préfère car elle utilise un adaptateur de fichier pour obtenir un fichier XML à partir du réseau et le charger sur des objets mappés en schéma XML. C'est l'approche que nous emploierons dans cet article.
- EnsLib.XML.Object.Service.FTPService. Il utilise un adaptateur FTP pour acquérir un fichier XML à partir d'un serveur FTP et le charger sur des objets mappés en schéma XML.
- EnsLib.XML.FileService. Il utilise un adaptateur de fichier pour obtenir un fichier XML à partir du réseau et le charger sur un flux de fichiers File Stream.
- EnsLib.XML.FTPService. Il utilise un adaptateur FTP pour obtenir un fichier XML à partir du serveur FTP et le charger sur un flux de fichiers File Stream.
- EnsLib.HTTP.GenericService et EnsLib.HTTP.Service. Ils utilisent un adaptateur HTTP pour consommer un point de terminaison HTTP et acquérir un contenu du fichier XML.
- EnsLib.SOAP.GenericService et EnsLib.SOAP.Service. Ils utilisent un adaptateur SOAP pour consommer un point de terminaison SOAP et recevoir un contenu du fichier XML.
Persistance et/ou interopérabilité du XML capturé
Pour rendre persistantes ou envoyer (interopérer) les données XML, vous pouvez utiliser tous les adaptateurs mentionnés ci-dessus, mais vous devez également inclure l'adaptateur SQL. Il est utilisé pour conserver les données dans les bases de données SGBDR, par exemple la base de données IRIS. Vous trouverez ci-dessous la liste des adaptateurs couramment utilisés pour l'interopérabilité:
- Adaptateur SQL : pour interopérer les données vers les bases de données cibles.
- Adaptateur Kafka: pour interopérer les données de manière asynchrone dans des rubriques Kafka.
- Adaptateur REST: pour interagir avec les API REST.
- Adaptateurs PEX: pour interagir avec les composants natifs Java, dotNet ou Python.
Pour interopérer ou conserver des données à l'aide de productions d'interopérabilité, il faut configurer une production et utiliser une opération métier associée à un adaptateur approprié. Les opérations métier les plus couramment utilisées sont les suivantes:
- EnsLib.SQL.Operation.GenericOperation: utilisée pour conserver les données capturées dans les bases de données SQL et IRIS.
- EnsLib.Kafka.Operation: utilisée pour publier les données capturées/traitées dans les rubriques Kafka.
- EnsLib.REPOS.GenericOperation: utilisée pour envoyer des données capturées/traitées aux méthodes des API REST, permettant des intégrations via des API REST.
- EnsLib.SAVON.GenericOperation: utilisée pour envoyer des données capturées/traitées aux méthodes de service Web SOAP, permettant des intégrations via des services Web SOAP.
- EnsLib.PEX.BusinessOperation: utilisée pour envoyer des données capturées/traitées aux composants Java, dotNet et Python natifs.
- EnsLib.XML.Objet.Opération.Ftoperation et EnsLib.XML.Objet.Opération.FileOperation: utilisées pour enregistrer des données XML sous forme de fichier à partir de données d'objet dans des serveurs FTP et des emplacements de système de fichiers Filesystem.
Entre les données capturées à l'aide des services métier et les données envoyées par les opérations métier, il est possible d'utiliser un processus métier pour mettre en œuvre des règles/logiques métier ou pour mapper et traduire le format et la structure des données du service métier à l'opération métier. Les types de processus métier les plus courants sont les suivants:
- Ens.BusinessProcessBPL. Il implémente la logique métier à l'aide du langage visuel BPL.
- EnsLib.MsgRouter.RoutingEngine. Il est utilisé pour mettre en œuvre la logique de mappage et de traduction afin de convertir les données capturées dans le protocole/la structure utilisé(e) par les opérations métier.
- EnsLib.PEX.BusinessProcess. Il est utilisé pour mettre en œuvre la logique métier via Java, DotNet ou Python.
En reprenant le système d'interopérabilité InterSystems IRIS, nous avons ce qui suit:
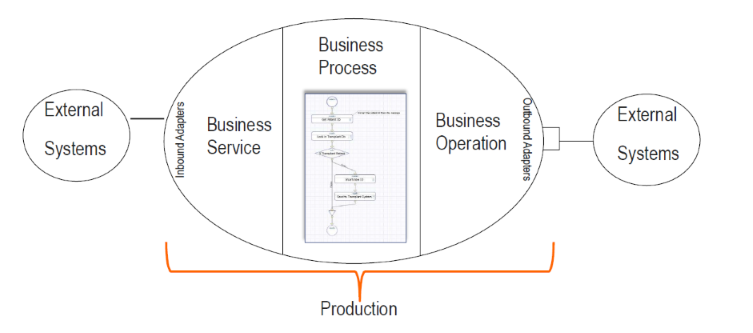
Pour illustrer et matérialiser l'interopérabilité des données XML, nous allons utiliser un exemple d'application Open Exchange.
Interopérabilité XML: un échantillon
Installer l'échantillon
1. Clone/git extrait le référentiel dans n'importe quel répertoire local.
$ git clone https://github.com/yurimarx/iris-xml-sample.git2. Ouvrez le terminal dans ce répertoire et lancez:
$ docker-compose build3. Lancez le conteneur IRIS avec votre projet:
$ docker-compose up -dLancement de la production d'échantillons
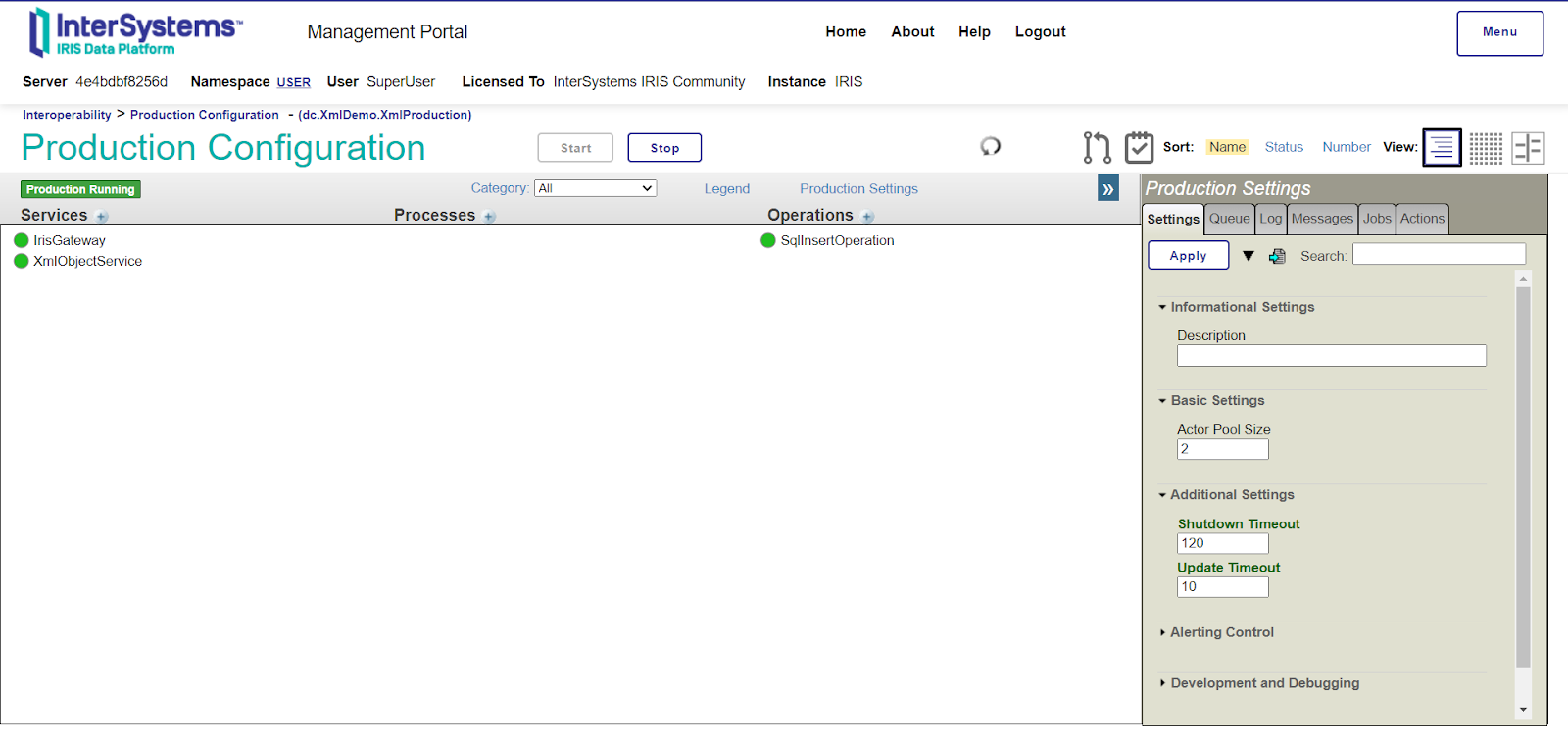
1. Ouvrez le lien http://localhost:52796/csp/user/EnsPortal.ProductionConfig.zen?$NAMESPACE=USER&$NAMESPACE=USER&
2. Cliquez sur le bouton Start et voyez tous les rubriques en vert:
CConfiguration du VSCode pour ce projet
1. Ouvrez le code source dans VSCode:
2. Dans le pied de page, recherchez le bouton ObjectScript (uniquement s'il n'est pas encore connecté):
3. Cliquez dessus et sélectionnez "Toggle Connection" en haut de la page:

4. Vous avez maintenant le VSCode et le serveur IRIS connectés à l'espace de noms de l'utilisateur USER:
Traitement d'un échantillon XML
1. Accédez à l'onglet Explorateur:
2. Sélectionnez le fichier books.xml et copiez-le dans le dossier xml_input:
3. Une ou deux secondes plus tard, le fichier books.xml sera traité et supprimé du dossier (VSCode affiche le fichier comme étant effacé et le supprime).
4. Vous pouvez maintenant voir les résultats dans l'éditeur de production: http://localhost:52796/csp/user/EnsPortal.ProductionConfig.zen?$NAMESPACE=USER&$NAMESPACE=USER&
5. Accédez à l'onglet Messages et cliquez sur la première session de la liste:
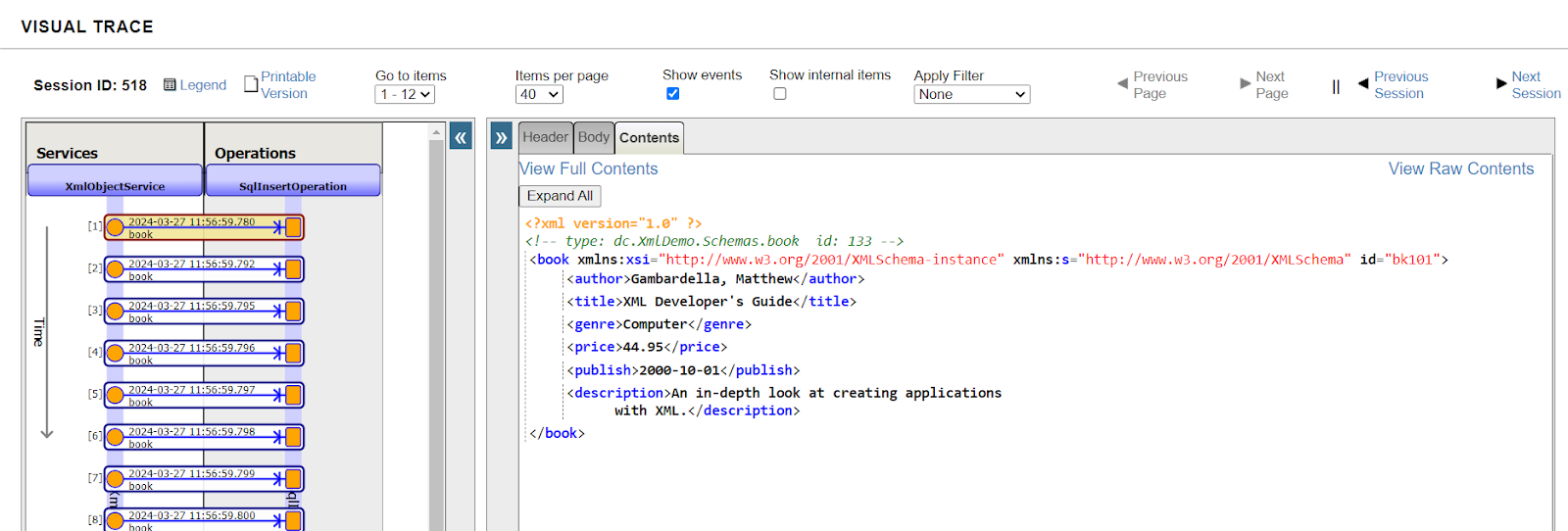
6. Consultez l'onglet Contenu:
7. Accédez maintenant à l'éditeur SQL: http://localhost:52796/csp/sys/exp/%25CSP.UI.Portal.SQL.Home.zen?$NAMESPACE=USER&$NAMESPACE=USER
8. Exécutez le SQL suivant et regardez les résultats:
SELECT
ID, author, description, genre, price, publish, title, totalDays
FROM dc_XmlDemo.Catalog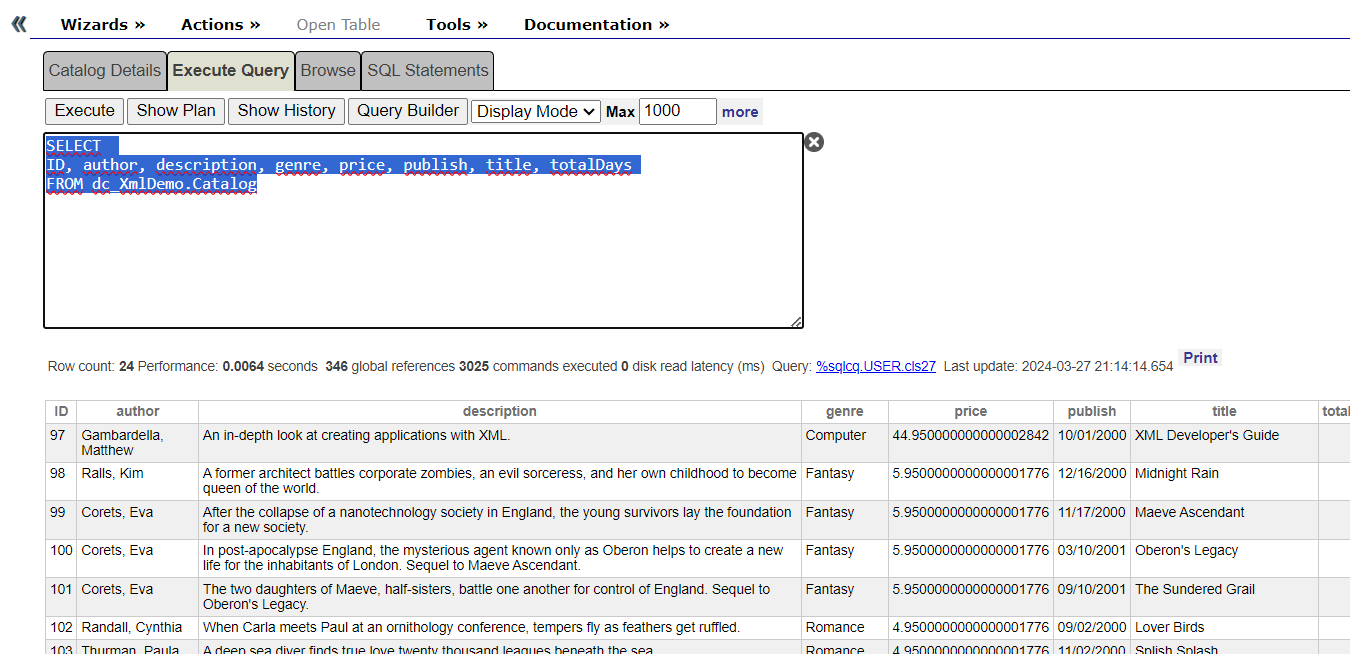
À ce stade, nous allons découvrir le code source de cet échantillon.
Derrière les coulisses : le code source
Création d'un mappage de classe pour le schéma XML
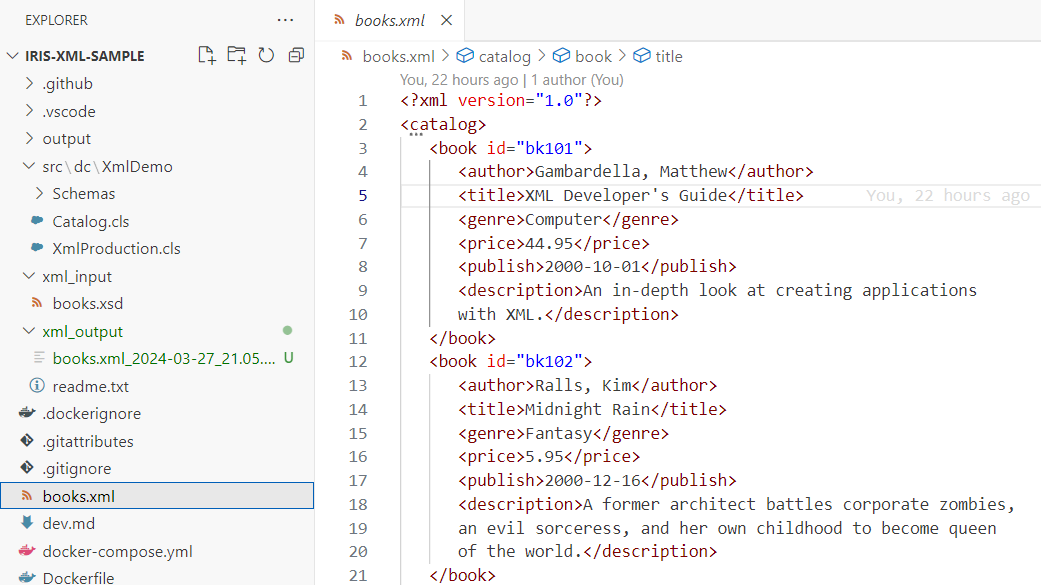
1. Ouvrez le fichier books.xml et copiez son contenu:
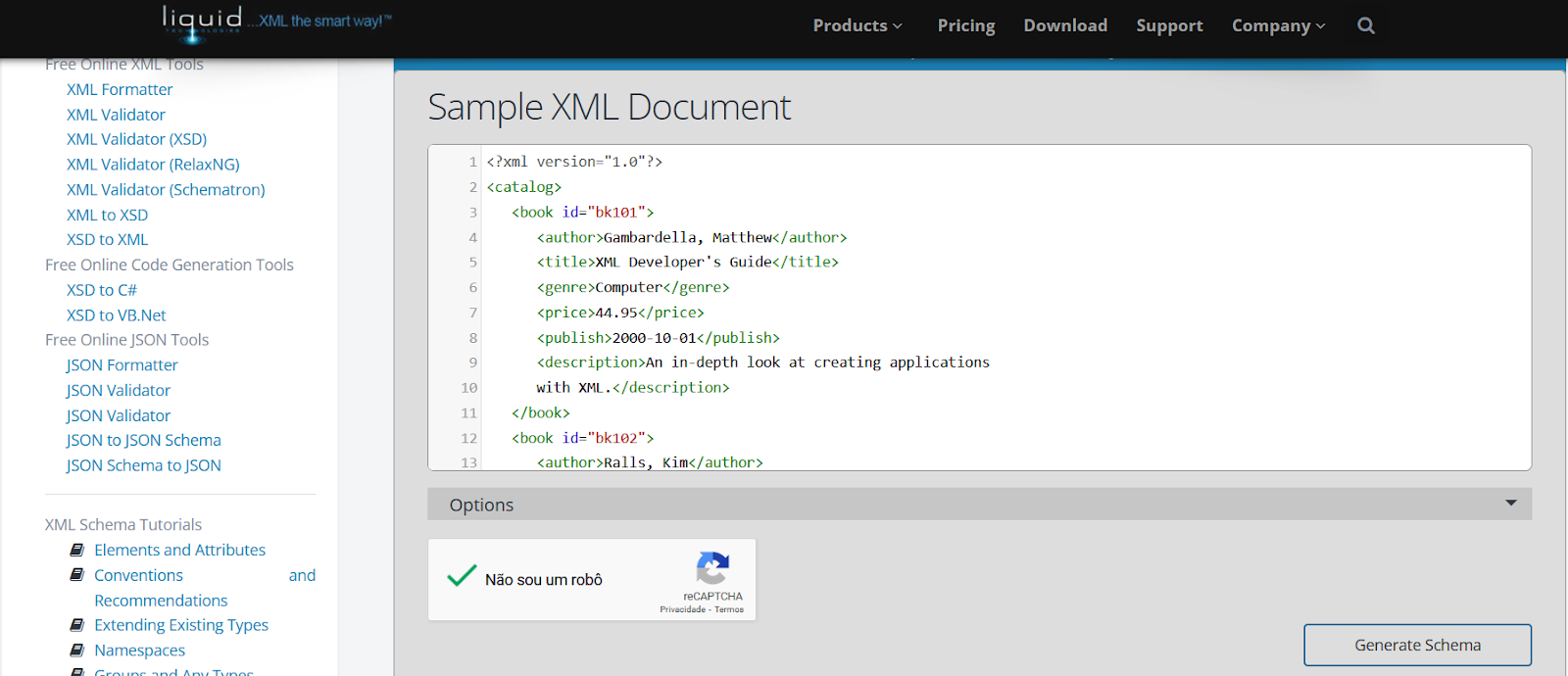
2. Nous devons créer un schéma XML pour ce fichier XML au cas où il n'existerait pas encore. J'ai utilisé ce site : https://www.liquid-technologies.com/online-xml-to-xsd-converter. Cependant, il existe de nombreuses autres possibilités en ligne. Il faut donc insérer le contenu XML et cliquer sur Générer un schéma.
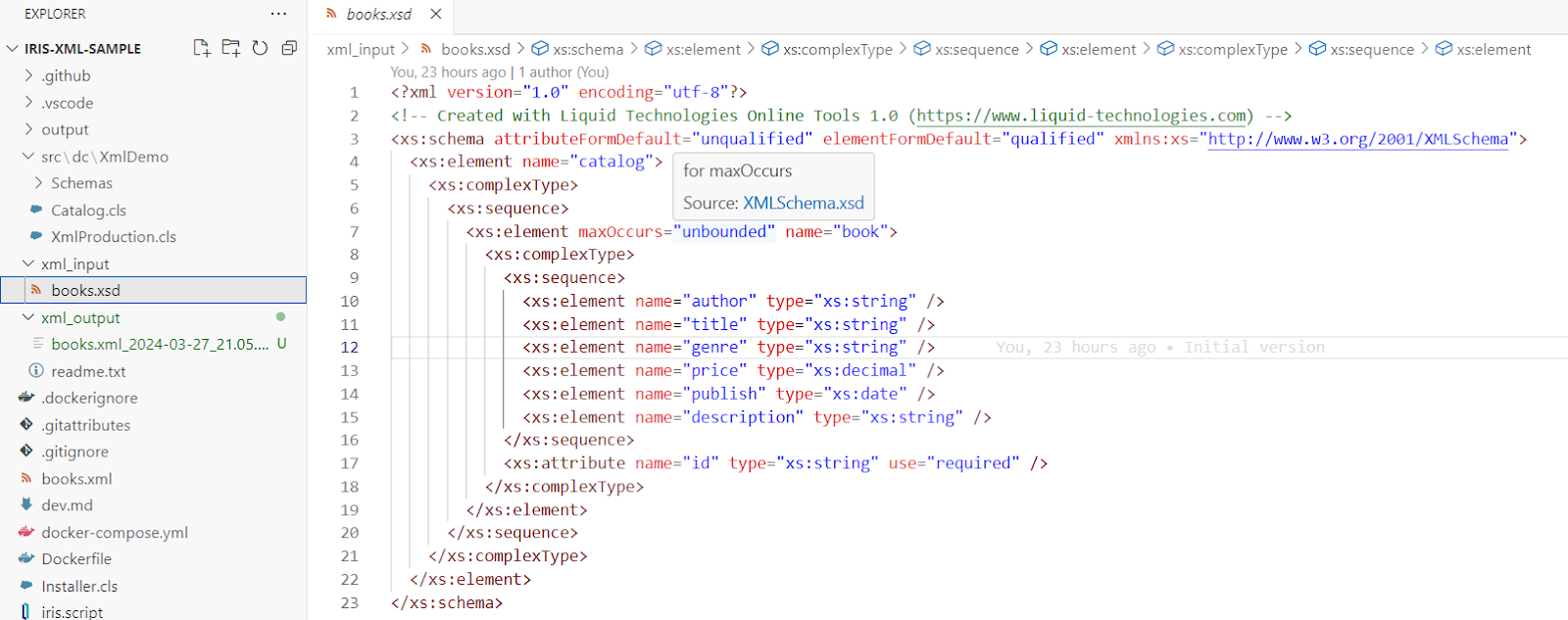
3. Copiez le schéma XML généré et créez le fichier books.xsd avec son contenu.:
4. Accédez au terminal IRIS. Pour ce faire, cliquez sur le bouton docker:iris:52796[USER] dans le pied de page et sélectionnez l'option Ouvrir le terminal dans Docker:
5. Écrivez les commandes comme indiqué ci-dessous:
USER>set reader = ##class(%XML.Utils.SchemaReader).%New()
USER>do reader.Process("/home/irisowner/dev/xml_input/books.xsd","dc.XmlDemo.Schemas")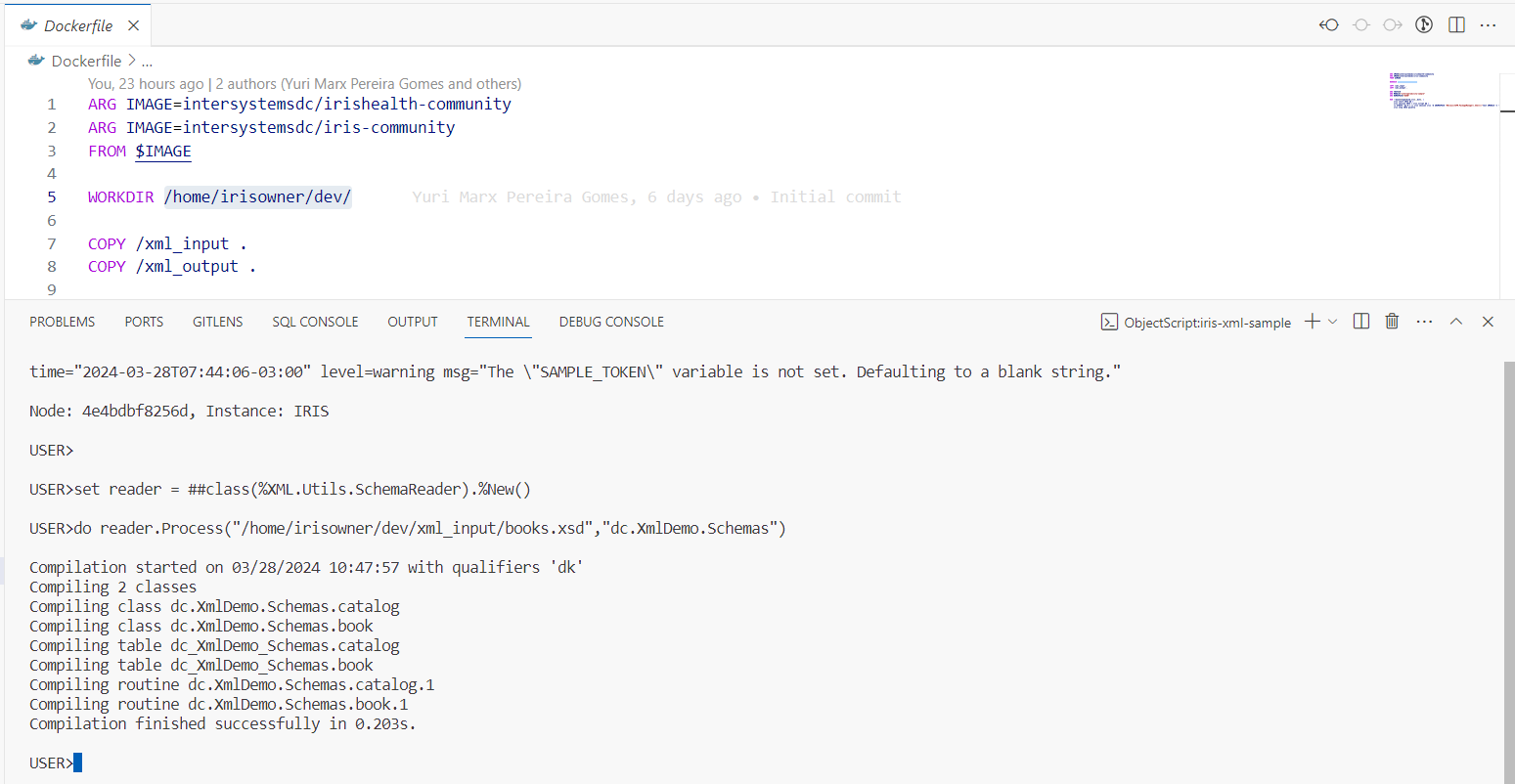
6. Cette méthode de classe IRIS crée pour vous des classes qui correspondent à la structure XML, ce qui vous permet d'accéder au XML par le biais de classes, de propriétés et de méthodes:

Création de la classe persistante pour stocker les livres ingérés à partir de données XML
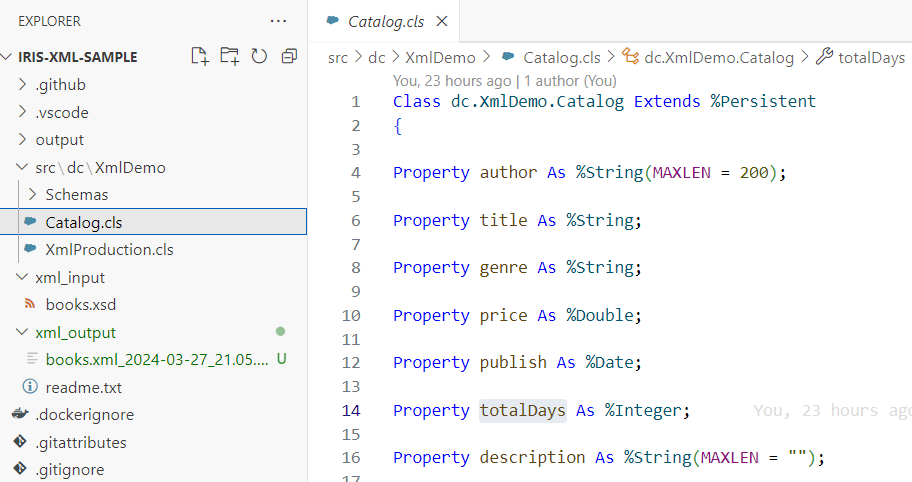
1. Créez le fichier Catalog.cls dans le dossier src/dc/XmlDemo avec le contenu suivant:
Class dc.XmlDemo.Catalog Extends %Persistent
{
Property author As %String(MAXLEN = 200);
Property title As %String;
Property genre As %String;
Property price As %Double;
Property publish As %Date;
Property totalDays As %Integer;
Property description As %String(MAXLEN = "");
}
2. Je ne comprends pas bien cette phrase. Peut-être que l'auteur voulait dire : "Cette classe élargit la classe %Persistent, ce qui nous permet de stocker des données persistantes dans la base de données".
3. Ces propriétés reflètent les données XML. Cependant, l'une d'entre elles, totalDays, n'est pas présente dans les données XML. Elle sera calculée en fonction du nombre de jours écoulés entre la publication et le jour actuel. Vous devez enregistrer cette classe pour la créer sur le serveur IRIS.
Création des informations d'identification pour accéder à la base de données IRIS à partir de la production
1. Accéder à Interopérabilité > Configuration > Informations d'identification et créer une référence IrisCreds:
- Identifiant: IrisCreds
- Nom de l'utilisateur: _SYSTEM
- Mot de passe: SYS
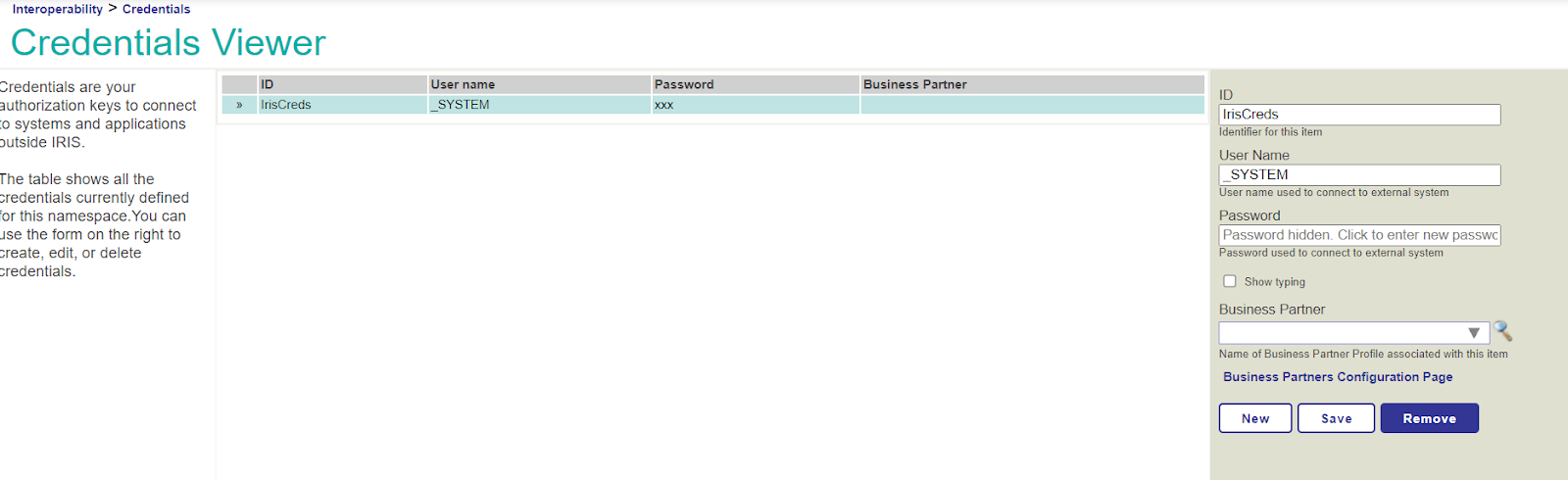
2. Cliquez sur Enregistrer (Save).
Création de la Production d'Interopérabilité
1. Accéder à Interopérabilité > ; Liste > ; Productions:
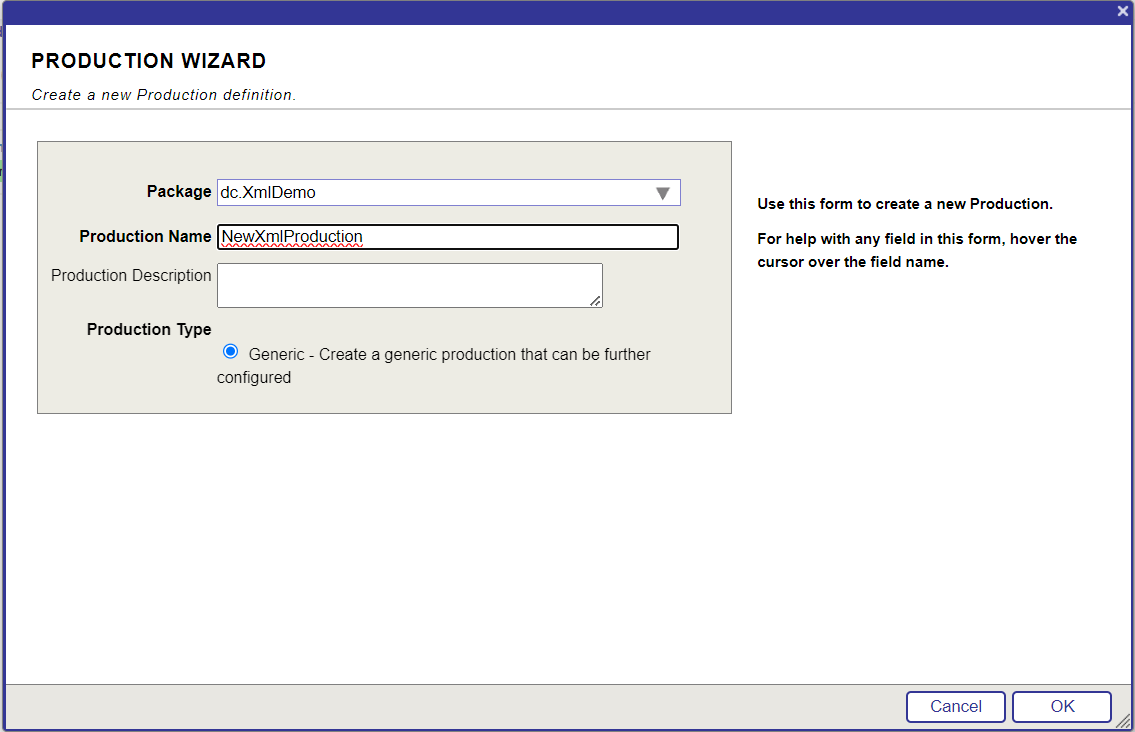
2. Créez une nouvelle production en cliquant sur le bouton Nouveau (New).
3. Saisissez les valeurs conformément à l'image ci-dessous et cliquez sur le bouton OK:
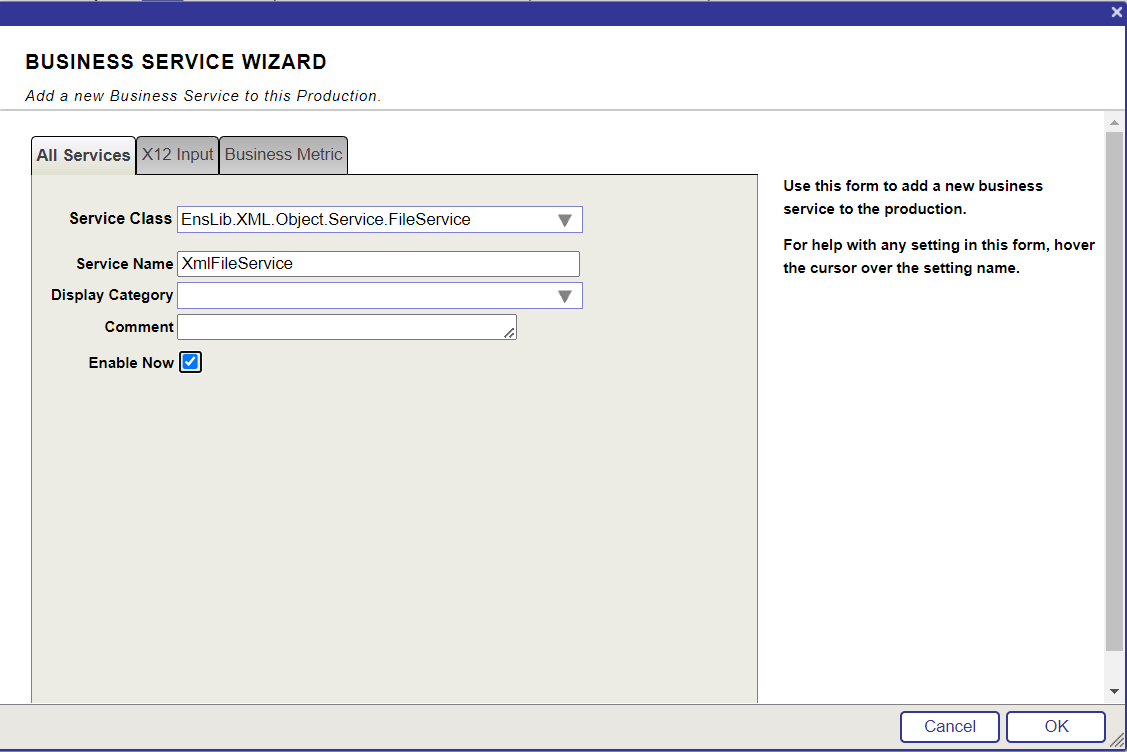
4. Cliquez sur le bouton + à côté des Services:

5. Définissez les options comme indiqué ci-dessous:
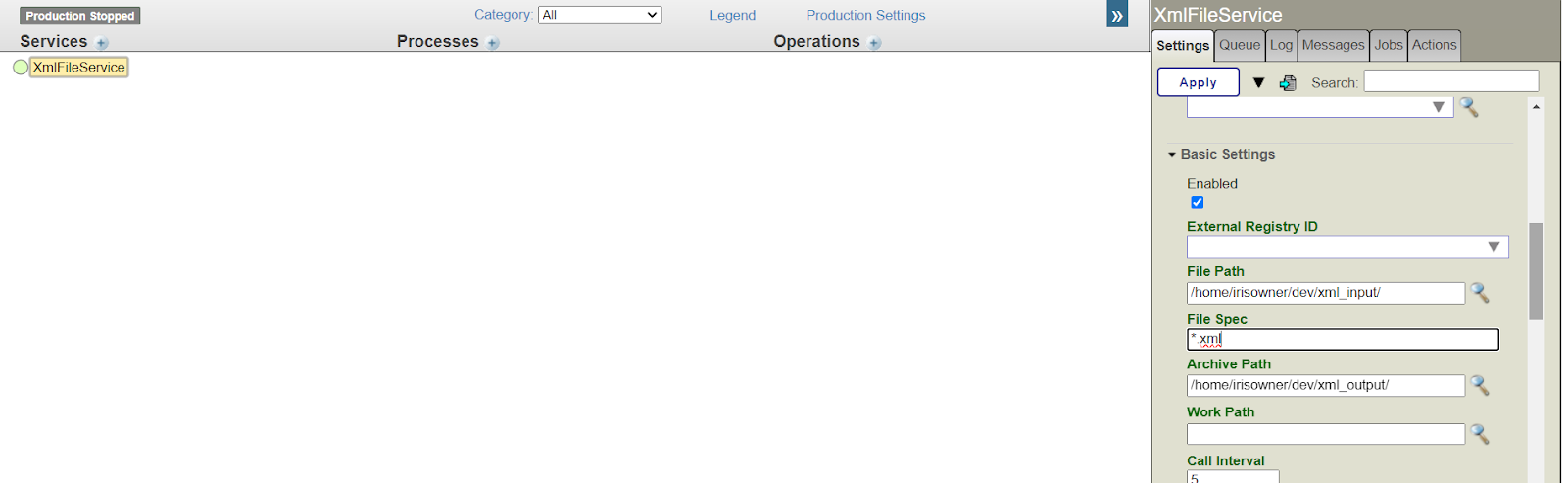
6. Remplissez les chemins d'accès au fichier XML avec les données suivantes:
- Chemin d'accès au fichier: /home/irisowner/dev/xml_input/
- Spécification du fichier: .xml
- Chemin d'accès à l'Archive: /home/irisowner/dev/xml_output/
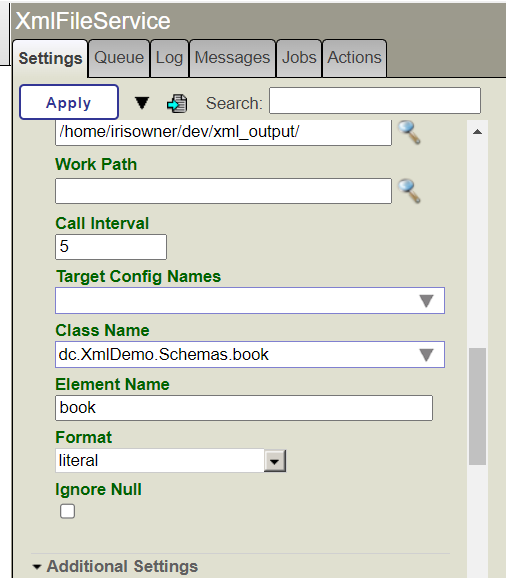
7. Saisissez le nom de la classe et le nom du composant pour obtenir les données relatives aux éléments du livre au moment de l'exécution:
8. Cliquez sur le bouton Appliquer (Apply).
9. À ce stade, il est préférable d'utiliser Java Gateway car nous allons établir une connexion JDBC avec la base de données du serveur IRIS pour envoyer des commandes d'insertion SQL et sauvegarder les données. Cette approche est valable pour tous les fournisseurs de bases de données, y compris Oracle, SQL Server, DB2, MySQL et PostgreSQL, lorsque vous devez rendre persistantes des données XML dans une table SQL.
10. Cliquez à nouveau sur le bouton + à côté des Services. Saisissez les champs comme illustré ci-dessous et cliquez sur le bouton OK:
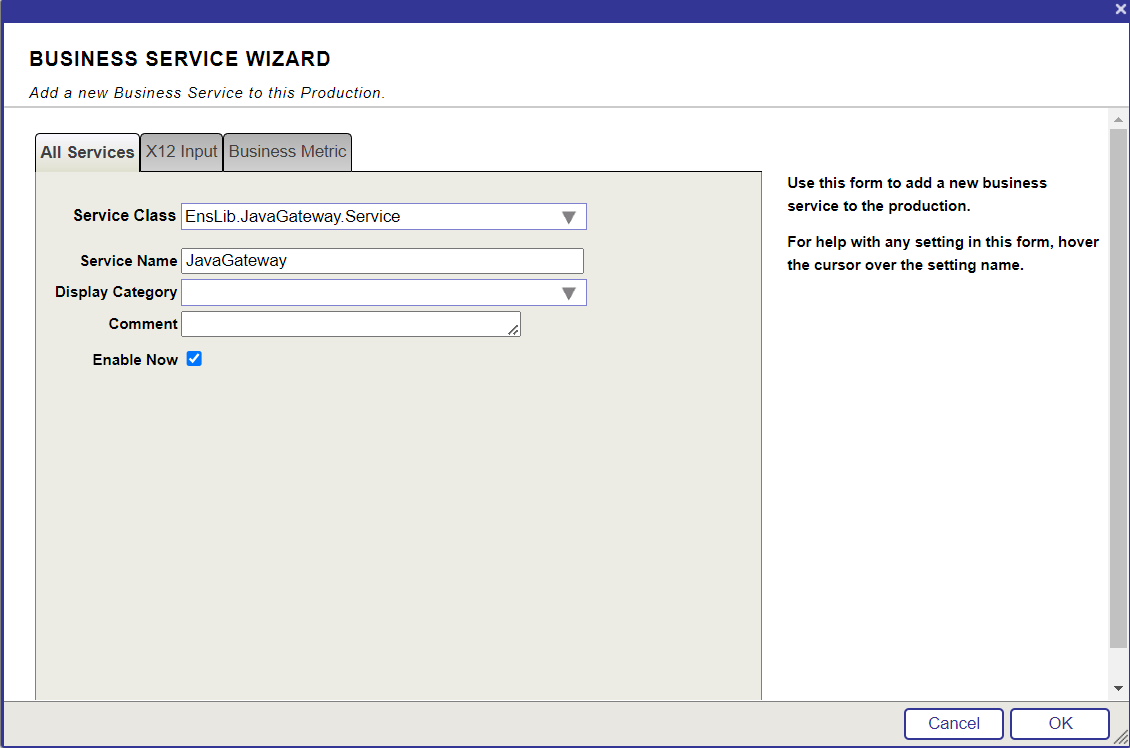
11. Choisissez la passerelle JavaGateway et saisissez les données suivantes dans le champ de chemin d'acces à la classe:
- Chemin d'acces à la classe: /usr/irissys/dev/java/lib/1.8/.jar
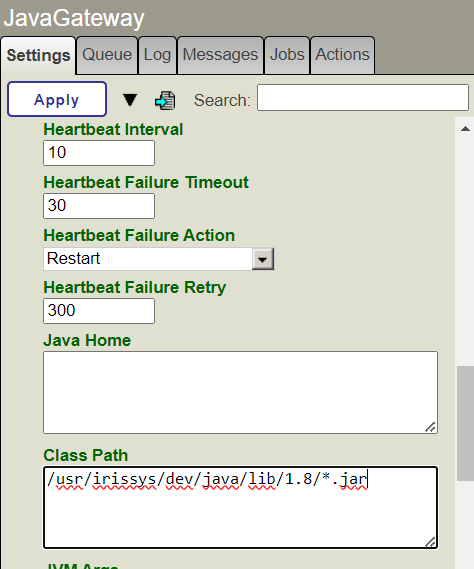
12. Ce chemin contient le pilote JDBC de la base de données IRIS.
13. Cliquez sur le bouton Appliquer (Apply).
14. Cliquez sur le bouton + à côté des Opérations.
15. Saisissez les valeurs et cliquez sur le bouton OK:
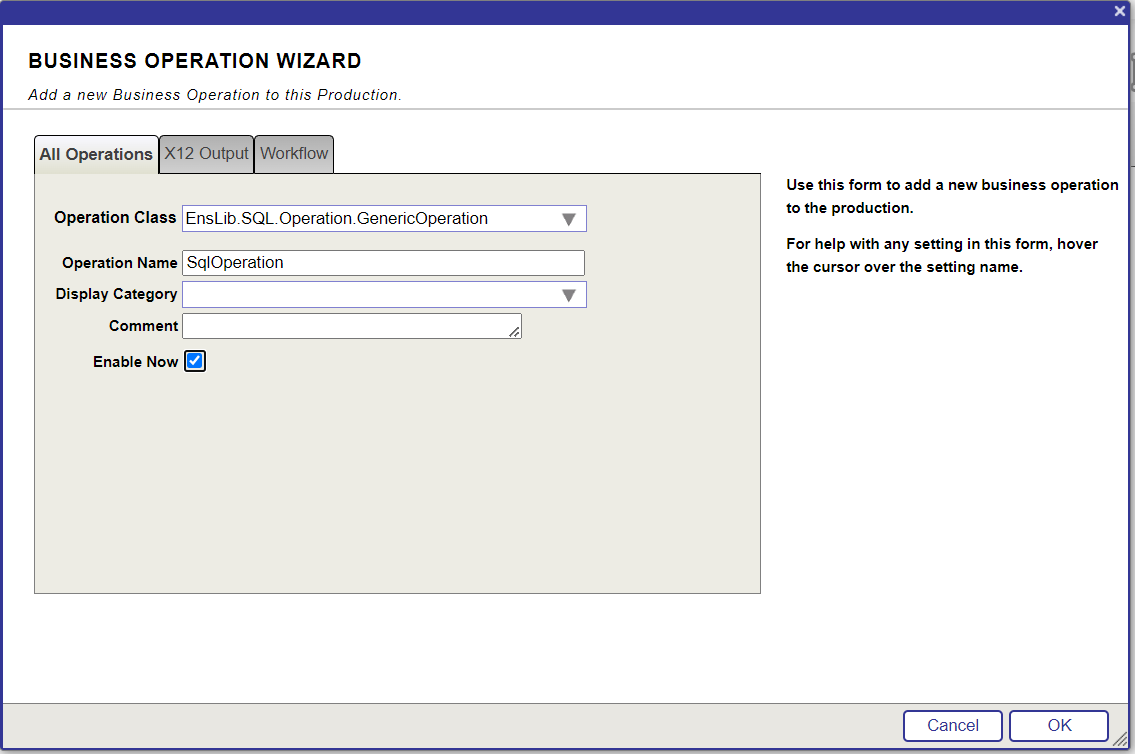
16. Choisissez SqlOperation et saisissez le DSN avec le nom de l'utilisateur (espace de noms dans lequel la table SQL du livre est disponible).
17. Sélectionnez IrisCreds dans le champ des Informations d'identification.
18. Écrivez la commande SQL suivante dans le champ de requête:
insert into dc_XmlDemo.Catalog(author, description, genre, price, publish, title,totalDays) values (?,?,?,?,DATE(?),?,DATEDIFF('d',?,CURRENT_DATE))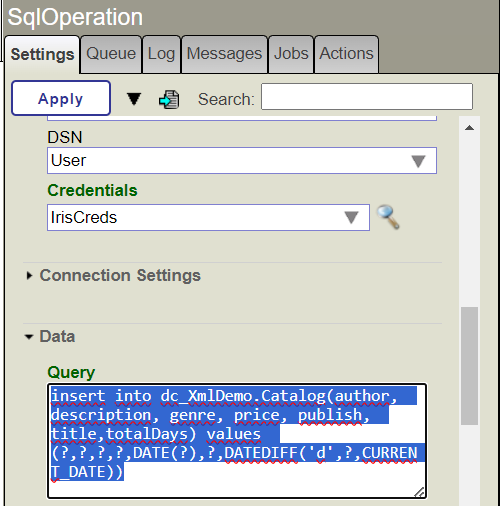
19. Saisissez la valeur dc.XmlDemo.Schemas.book dans RequestClass:

20. Cliquez sur le bouton + à côté de Ajouter (Add) et cliquez sur le bouton Liste à côté du bouton X pour choisir le champ du premier paramètre ‘?’:
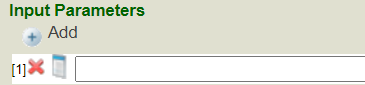
21. Sélectionnez *author et cliquez sur le bouton OK:
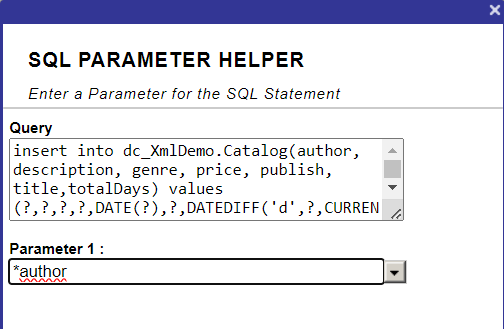
22. Incluez plus de paramètres pour obtenir les résultats affichés ci-dessous:
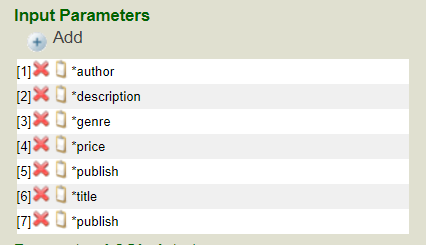
23. Il est essentiel de vérifier si vos valeurs ont * avant le champ.
24. Cliquez sur le bouton Appliquer (Apply).
25. Maintenant, choisissez à nouveau XmlFileService et définissez le champ des noms de configuration cible (Target Config Names) sur SqlOperation. Cela permettra au service de recevoir les données XML et d'envoyer les valeurs à l'opération SqlOperation enregistrée dans la base de données.

26. Arrêtez la production créée dans l'exemple avant de lancer celle que vous avez développée:
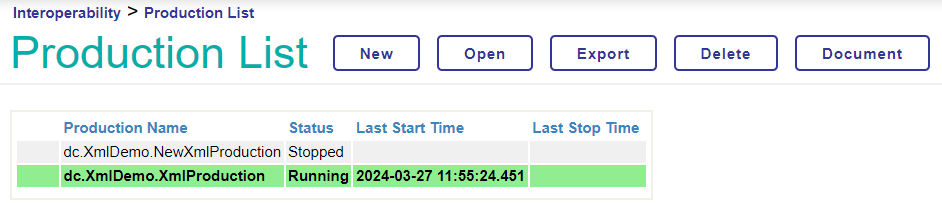
27. Cliquez sur Ouvrir (Open) et l'arrêter (Stop):
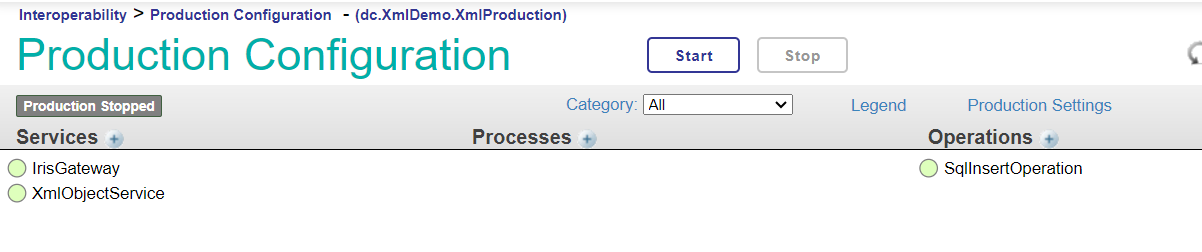
28. Sélectionnez la production dont vous avez besoin:
29. Sélectionnez votre nouvelle production, ouvrez-la et démarrez-la.
30. Dans VSCode, copiez le fichier books.xml dans le dossier xml_input pour tester votre production.
31. Observez les résultats comme indiqué dans la section d'échantillon XML de processus (Process XML Sample) et profitez-en!