Effacer le filtre
Annonce
Irène Mykhailova · Sept 15, 2022
Salut la communauté,
C'est l'heure de voter ! Soumettez vos votes pour les meilleures applications du concours d'interopérabilité : Créer des solutions durables
🔥 VOTEZ POUR LES MEILLEURES APPLICATIONS 🔥
Comment voter ? Détails ci-dessous.
Nomination des experts
Le jury expérimenté d'InterSystems choisira les meilleures applications pour la nomination des prix dans le cadre de la nomination des experts. Veuillez accueillir nos experts :
⭐️ @Alexander.Koblov, Support Specialist⭐️ @Alexander.Woodhead, Technical Specialist⭐️ @Guillaume.Rongier7183, Sales Engineer⭐️ @Alberto.Fuentes, Sales Engineer⭐️ @Dmitry.Zasypkin, Senior Sales Engineer⭐️ @Daniel.Kutac, Senior Sales Engineer⭐️ @Eduard.Lebedyuk, Senior Cloud Engineer⭐️ @Steve.Pisani, Senior Solution Architect⭐️ @James.MacKeith, Principal Systems Developer⭐️ @Nicholai.Mitchko, Manager, Solution Partner Sales Engineering⭐️ @Timothy.Leavitt, Development Manager⭐️ @Benjamin.DeBoe, Product Manager⭐️ @Robert.Kuszewski, Product Manager⭐️ @Stefan.Wittmann, Product Manager⭐️ @Raj.Singh5479, Product Manager⭐️ @Jeffrey.Fried, Director of Product Management⭐️ @Evgeny.Shvarov, Developer Ecosystem Manager
Community nomination:
Pour chaque utilisateur, un score plus élevé est sélectionné parmi les deux catégories ci-dessous :
Conditions
Place
1ère
2ème
3ème
Si vous avez un article publié sur DC et une application téléchargée sur Open Exchange (OEX)
9
6
3
Si vous avez au moins 1 article posté sur le DC ou 1 application téléchargée sur OEX
6
4
2
Si vous apportez une contribution valable au DC (commentaire/question, etc.).
3
2
1
Niveau
Place
1ère
2ème
3ème
Niveau VIP Global Masters ou ISC Product Manager
15
10
5
Niveau Ambassador GM
12
8
4
Niveau Expert GM ou DC Moderators
9
6
3
Niveau Specialist GM
6
4
2
Niveau Advocate GM or ISC Employee
3
2
1
Vote à l'aveugle !
Le nombre de votes pour chaque application sera caché à tous. Une fois par jour, nous publierons le classement dans les commentaires de ce post.
L'ordre des projets sur la page du concours sera le suivant : plus une application a été soumise tôt au concours, plus elle sera en haut de la liste.
P.S. N'oubliez pas de vous abonner à ce billet (cliquez sur l'icône de la cloche) pour être informé des nouveaux commentaires.
Pour participer au vote, vous devez :
Vous connecter à Open Exchange – les informations d'identification DC fonctionneront.
Apporter une contribution valide à la communauté des développeurs - répondre ou poser des questions, écrire un article, contribuer à des applications sur Open Exchange - et vous pourrez voter. Consultez cet article sur les options permettant d'apporter des contributions utiles à la communauté des développeurs.
Si vous changez d'avis, annulez le choix et donnez votre vote à une autre application !
Soutenez l'application que vous aimez !
Remarque : les participants au concours sont autorisés à corriger les bugs et à apporter des améliorations à leurs applications pendant la semaine de vote, alors ne manquez pas de vous abonner aux versions des applications !
Article
Lucas Enard · Sept 14, 2022
# 1. Fhir-client-python
Ceci est un client fhir simple en python pour s'exercer avec les ressources fhir et les requêtes CRUD vers un serveur FHIR.
Notez que pour la plupart, l'autocomplétion est activée, c'est la principale raison d'utiliser fhir.resources.
[GitHub](https://github.com/LucasEnard/fhir-client-python)
- [1. Fhir-client-python](#1-fhir-client-python)
- [2. Préalables](#2-préalables)
- [3. Installation](#3-installation)
- [3.1. Installation pour le dévelopment](#31-installation-pour-le-développement)
- [3.2. Portail de gestion et VSCode](#32-portail-de-gestion-et-VSCode)
- [3.3. Avoir le dossier ouvert à l'intérieur du conteneur](#33-avoir-le-dossier-ouvert-à-l'intérieur-du-conteneur)
- [4. Serveur FHIR](#4-serveur-FHIR)
- [5. Présentation pas à pas](#5-présentation)
- [5.1. Partie 1](#51-partie-1)
- [5.2. Partie 2](#52-partie-2)
- [5.3. Partie 3](#53-partie-3)
- [5.4. Partie 4](#54-partie-4)
- [5.5. Conclusion de la présentation](#55-conclusion-de-la-présentation)
- [6. Comment ça marche](#6-comment-ça-marche)
- [6.1. Les importations](#61-le-importations)
- [6.2. Cree le client](#62-creaer-le-client)
- [6.3. Travailler sur nos ressources](#63-travailler-sur-nos-ressources)
- [6.4. Sauvegarder nos changements](#64-sauvegarder-nos-changements)
- [7. Comment commencer le codage](#7-comment-commencer-le-codage)
- [8. Ce qu'il y a dans le référentiel](#8-ce-qu'il-y-a-dans-le-référentiel)
- [8.1. Dockerfile](#81-dockerfile)
- [8.2. .vscode/settings.json](#82-vscodesettingsjson)
- [8.3. .vscode/launch.json](#83-vscodelaunchjson)
# 2. Préalables
Assurez-vous que [git](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git) et [Docker desktop](https://www.docker.com/products/docker-desktop) sont installé.
Si vous travaillez à l'intérieur du conteneur, comme il est montré dans [3.3.](#33-having-the-folder-open-inside-the-container), vous n'avez pas besoin d'installer fhirpy et fhir.resources.
Si vous n'êtes pas dans le conteneur, vous pouvez utiliser `pip` pour installer `fhirpy` et `fhir.resources`. Vérifiez [fhirpy](https://pypi.org/project/fhirpy/#resource-and-helper-methods) et [fhir.resources](https://pypi.org/project/fhir.resources/) pour plus d'information.
# 3. Installation
## 3.1. Installation pour le développement
Clone/git tire le repo dans n'importe quel répertoire local, par exemple comme indiqué ci-dessous :
```
git clone https://github.com/LucasEnard/fhir-client-python.git
```
Ouvrez le terminal dans ce répertoire et lancez :
```
docker build.
```
## 3.2. Portail de gestion et VSCode
Ce référentiel est prêt pour [VS Code](https://code.visualstudio.com/).
Ouvrez le dossier `fhir-client-python` cloné localement dans VS Code.
Si vous y êtes invité (coin inférieur droit), installez les extensions recommandées.
## 3.3. Avoir le dossier ouvert à l'intérieur du conteneur
Vous pouvez être *à l'intérieur* du conteneur avant de coder si vous le souhaitez.
Pour cela, il faut que docker soit activé avant d'ouvrir VSCode.
Ensuite, dans VSCode, lorsque vous y êtes invité ( coin inférieur droit ), rouvrez le dossier à l'intérieur du conteneur afin de pouvoir utiliser les composants python qu'il contient.
La première fois que vous effectuez cette opération, cela peut prendre plusieurs minutes, le temps que le conteneur soit préparé.
Si vous n'avez pas cette option, vous pouvez cliquer dans le coin inférieur gauche et cliquer sur `Ouvrir à nouveau dans le conteneur` puis sélectionner `De Dockerfile`
[Plus d'informations ici](https://code.visualstudio.com/docs/remote/containers)

En ouvrant le dossier à distance, vous permettez à VS Code et à tous les terminaux que vous ouvrez dans ce dossier d'utiliser les composants python dans le conteneur.
# 4. Serveur FHIR
Pour réaliser cette présentation, vous aurez besoin d'un serveur FHIR.
Vous pouvez soit utiliser le vôtre, soit vous rendre sur le site [InterSystems free FHIR trial](https://portal.live.isccloud.io) et suivre les étapes suivantes pour le configurer.
En utilisant notre essai gratuit, il suffit de créer un compte et de commencer un déploiement, puis dans l'onglet `Overview` vous aurez accès à un endpoint comme `https://fhir.000000000.static-test-account.isccloud.io` que nous utiliserons plus tard.
Ensuite, en allant dans l'onglet d'informations d'identification `Credentials`, créez une clé api et enregistrez-la quelque part.
C'est maintenant terminé, vous avez votre propre serveur fhir pouvant contenir jusqu'à 20 Go de données avec une mémoire de 8 Go.
# 5. Présentation pas à pas
La présentation pas à pas du client se trouve à `src/client.py`.
Le code est divisé en plusieurs parties, et nous allons couvrir chacune d'entre elles ci-dessous.
## 5.1. Partie 1
Dans cette partie, nous connectons notre client à notre serveur en utilisant fhirpy et nous obtenons nos ressources Patient à l'intérieur de la variable `patients_resources`.
A partir de cette variable nous pourrons fecth n'importe quel Patient et même les trier ou obtenir un Patient en utilisant certaines conditions.
```python
#Partie 1----------------------------------------------------------------------------------------------------------------------------------------------------
#Créer notre client connecté à notre serveur
client = SyncFHIRClient(url='url', extra_headers={"x-api-key":"api-key"})
#Obtenir les ressources de notre patient dans lesquelles nous pourrons aller chercher et rechercher
patients_resources = client.resources('Patient')
```
Afin de vous connecter à votre serveur, vous devez modifier la ligne :
```python
client = SyncFHIRClient(url='url', extra_headers={"x-api-key":"api-key"})
```
L`'url'` est un point de terminaison tandis que l'`"api-key"` est la clé d'api pour accéder à votre serveur.
Notez que si **vous n'utilisez pas** un serveur InterSystems, vous pouvez vérifier comment changer `extra_headers={"x-api-key":"api-key"}` en `authorization = "api-key"`.
Comme ça, nous avons un client FHIR capable d'échanger directement avec notre serveur.
## 5.2. Partie 2
Dans cette partie, nous créons un Patient en utilisant Fhir.Model et nous le complétons avec un HumanName, en suivant la convention FHIR, `use` et `family` sont des chaînes et `given` est une liste de chaînes. e la même manière, un patient peut avoir plusieurs HumanNames, donc nous devons mettre notre HumanName dans une liste avant de le mettre dans notre patient nouvellement créé.
```python
#Partie 2----------------------------------------------------------------------------------------------------------------------------------------------------
#Nous voulons créer un patient et l'enregistrer sur notre serveur
#Créer un nouveau patient en utilisant fhir.resources
patient0 = Patient()
#Créer un HumanName et le remplir avec les informations de notre patient
name = HumanName()
name.use = "official"
name.family = "familyname"
name.given = ["givenname1","givenname2"]
patient0.name = [name]
#Vérifier notre patient dans le terminal
print()
print("Our patient : ",patient0)
print()
#Sauvegarder (post) notre patient0, cela va le créer sur notre serveur
client.resource('Patient',**json.loads(patient0.json())).save()
```
Après cela, nous devons sauvegarder notre nouveau Patient sur notre serveur en utilisant notre client.
Notez que si vous lancez `client.py` plusieurs fois, plusieurs Patients ayant le nom que nous avons choisi seront créés. C'est parce que, suivant la convention FHIR, vous pouvez avoir plusieurs Patients avec le même nom, seul l' `id` est unique sur le serveur.
Alors pourquoi n'avons-nous pas rempli notre Patient avec un `id` de la même façon que nous avons rempli son nom ? Parce que si vous mettez un id à l'intérieur de la fonction save(), la sauvegarde agira comme une mise à jour avant d'agir comme un sauveur, et si l'id n'est en fait pas déjà sur le serveur, il le créera comme prévu ici. Mais comme nous avons déjà des patients sue notre serveur, ce n'est pas une bonne idée de créer un nouveau patient et d'allouer à la main un Identifiant puisque la fonction save() et le serveur sont faits pour le faire à votre place.
Nous conseillons donc de commenter la ligne après le premier lancement.
## 5.3. Partie 3
Dans cette partie, nous avons un client qui cherche dans nos `patients_resources` un patient nommé d'après celui que nous avons créé précédemment.
```python
#Partie 3----------------------------------------------------------------------------------------------------------------------------------------------------
#Maintenant, nous voulons obtenir un certain patient et ajouter son numéro de téléphone et changer son nom avant de sauvegarder nos changements sur le serveur
#Obtenez le patient en tant que fhir.resources Patient de notre liste de ressources de patients qui a le bon nom, pour la commodité, nous allons utiliser le patient que nous avons créé avant
patient0 = Patient.parse_obj(patients_resources.search(family='familyname',given='givenname1').first().serialize())
#Créer le nouveau numéro de téléphone de notre patient
telecom = ContactPoint()
telecom.value = '555-748-7856'
telecom.system = 'phone'
telecom.use = 'home'
#Ajouter le téléphone de notre patient à son dossier
patient0.telecom = [telecom]
#Changer le deuxième prénom de notre patient en "un autre prénom"
patient0.name[0].given[1] = "anothergivenname"
#Vérifiez notre Patient dans le terminal
print()
print("Notre patient avec le numéro de téléphone et le nouveau prénom : ",patient0)
print()
#Sauvegarder (mettre) notre patient0, ceci sauvera le numéro de téléphone et le nouveau prénom au patient existant de notre serveur
client.resource('Patient',**json.loads(patient0.json())).save()
```
Une fois que nous l'avons trouvé, nous ajoutons un numéro de téléphone à son profil et nous changeons son prénom en un autre.
Maintenant nous pouvons utiliser la fonction de mise à jour de notre client pour mettre à jour notre patient sur le serveur.
## 5.4. Partie 4
Dans cette partie, nous voulons créer une observation pour notre patient précédent, pour ce faire, nous cherchons d'abord notre `patients_resources` pour notre patient, puis nous obtenons son identifiant, qui est son identificateur unique.
```python
#Partie 4----------------------------------------------------------------------------------------------------------------------------------------------------
#Maintenant nous voulons créer une observation pour notre client
#Obtenir l'identifiant du patient auquel vous voulez attacher l'observation
id = Patient.parse_obj(patients_resources.search(family='familyname',given='givenname1').first().serialize()).id
print("id of our patient : ",id)
#Placer notre code dans notre observation, code qui contient des codages qui sont composés de système, code et affichage
coding = Coding()
coding.system = "https://loinc.org"
coding.code = "1920-8"
coding.display = "Aspartate aminotransférase [Activité enzymatique/volume] dans le sérum ou le plasma"
code = CodeableConcept()
code.coding = [coding]
code.text = "Aspartate aminotransférase [Activité enzymatique/volume] dans le sérum ou le plasma"
#Créer une nouvelle observation en utilisant fhir.resources, nous entrons le statut et le code dans le constructeur car ils sont nécessaires pour valider une observation
observation0 = Observation(status="final",code=code)
#Définir notre catégorie dans notre observation, catégorie qui détient les codages qui sont composés de système, code et affichage
coding = Coding()
coding.system = "https://terminology.hl7.org/CodeSystem/observation-category"
coding.code = "laboratoire"
coding.display = "laboratoire"
category = CodeableConcept()
category.coding = [coding]
observation0.category = [category]
#Définir l'heure de notre date effective dans notre observation
observation0.effectiveDateTime = "2012-05-10T11:59:49+00:00"
#Régler l'heure de notre date d'émission dans notre observation
observation0.issued = "2012-05-10T11:59:49.565+00:00"
#Définir notre valueQuantity dans notre observation, valueQuantity qui est composée d'un code, d'un unir, d'un système et d'une valeur
valueQuantity = Quantity()
valueQuantity.code = "U/L"
valueQuantity.unit = "U/L"
valueQuantity.system = "https://unitsofmeasure.org"
valueQuantity.value = 37.395
observation0.valueQuantity = valueQuantity
#Définir la référence à notre patient en utilisant son identifiant
reference = Reference()
reference.reference = f"Patient/{id}"
observation0.subject = reference
#Vérifiez notre observation dans le terminal
print()
print("Notre observation : ",observation0)
print()
#Sauvegarder (poster) notre observation0 en utilisant notre client
client.resource('Observation',**json.loads(observation0.json())).save()
```
Ensuite, nous enregistrons notre observation à l'aide de la fonction save().
## 5.5. Conclusion de la présentation
Si vous avez suivi ce parcours, vous savez maintenant exactement ce que fait client.py, vous pouvez le lancer et vérifier votre Patient et votre Observation nouvellement créés sur votre serveur.
# 6. Comment ça marche
## 6.1. Les importations
```python
from fhirpy import SyncFHIRClient
from fhir.resources.patient import Patient
from fhir.resources.observation import Observation
from fhir.resources.humanname import HumanName
from fhir.resources.contactpoint import ContactPoint
import json
```
La première importation ***est*** le client, ce module va nous aider à nous connecter au serveur, à obtenir et exporter des ressources.
Le module fhir.resources nous aide à travailler avec nos ressources et nous permet, grâce à l'auto-complétion, de trouver les variables dont nous avons besoin.
La dernière importation est json, c'est un module nécessaire pour échanger des informations entre nos 2 modules.
## 6.2. Création du client
```python
client = SyncFHIRClient(url='url', extra_headers={"x-api-key":"api-key"})
```
L'`'url'` est ce que nous avons [appelé avant](#) un point de terminaison tandis que l'`"api-key"`' est la clé que vous avez générée plus tôt.
Notez que si **vous n'utilisez pas** un serveur InterSystems, vous voudrez peut-être changer le `extra_headers={"x-api-key" : "api-key"}` en `authorization = "api-key"`
Comme ça, nous avons un client FHIR capable d'échanger directement avec notre serveur.
Par exemple, vous pouvez accéder à vos ressources Patient en faisant `patients_resources = client.resources('Patient')` , fà partir de là, vous pouvez soit obtenir vos patients directement en utilisant `patients = patients_resources.fetch()` ou en allant chercher après une opération, comme :
`patients_resources.search(family='familyname',given='givenname').first()` cette ligne vous donnera le premier patient qui sort ayant pour nom de famille 'familyname' et pour nom donné 'givenname'.
## 6.3. Travailler sur nos ressources
Une fois que vous avez les ressources que vous voulez, vous pouvez les analyser dans une ressource fhir.resources.
Par exemple :
```python
patient0 = Patient.parse_obj(patients_resources.search(family='familyname',given='givenname1').first().serialize())
```
patient0 est un patient de fhir.resources, pour l'obtenir nous avons utilisé nos patients_resources comme cela a été montré précédemment où nous avons `sélectionné` un certain nom de famille et un prénom, après cela nous avons pris le `premier` qui est apparu et l'avons `sérialisé`. En mettant ce patient sérialisé à l'intérieur d'un Patient.parse_obj nous allons créer un patient de fhir.resources .
Maintenant, vous pouvez accéder directement à n'importe quelle information que vous voulez comme le nom, le numéro de téléphone ou toute autre information.Pour ce faire, utilisez juste par exemple :
```python
patient0.name
```
Cela renvoie une liste de HumanName composée chacune d'un attribut `use` un attribut `family` un attribut `given`
as the FHIR convention is asking. Cela signifie que vous pouvez obtenir le nom de famille de quelqu'un en faisant :
```python
patient0.name[0].family
```
## 6.4. Sauvegarder nos changements
Pour enregistrer toute modification de notre serveur effectuée sur un fhir.resources ou pour créer une nouvelle ressource serveur, nous devons utiliser à nouveau notre client.
```python
client.resource('Patient',**json.loads(patient0.json())).save()
```
En faisant cela, nous créons une nouvelle ressource sur notre client, c'est-à-dire un patient, qui obtient ses informations de notre fhir.resources patient0. Ensuite, nous utilisons la fonction save() pour poster ou mettre notre patient sur le serveur.
# 7. Comment commencer le codage
Ce référentiel est prêt à être codé dans VSCode avec les plugins InterSystems.
Ouvrez `/src/client.py` pour commencer à coder ou utiliser l'autocomplétion.
# 8. Ce qu'il y a dans le référentiel
## 8.1. Dockerfile
Le dockerfile le plus simple pour démarrer un conteneur Python.
Utilisez `docker build .` pour construire et rouvrir votre fichier dans le conteneur pour travailler à l'intérieur de celui-ci.
## 8.2. .vscode/settings.json
Fichier de paramètres.
## 8.3. .vscode/launch.json
Fichier de configuration si vous voulez déboguer.
Article
Irène Mykhailova · Mars 24, 2023
Salut la Communauté !
Ce jour que vous avez attendu avec impatience, est enfin arrivé ! La 10ème édition de Hacking Health Camp est lancée aujourd'hui et nous, vos modérateurs favoris, sommes présents pour accompagner les équipes à mener à bien leurs projets ! Alors, restez à l'écoute pour plus de nouvelles!
L'événement est l'occasion de nombreuses rencontres. Nouveaux visages et favoris familiers :) Cette fois, nous sommes tombés sur @Laurent.Viquesnel :
@Lorenzo.Scalese, @Guillaume.Rongier7183 et @Laurent.Viquesnel.
Mise à jour 17h00
Le HHC 2023 a commencé par les témoignages de beaux projets issus des précédentes éditions de Hacking Health Camp. Tout le monde pourrait s'inspirer de leur expérience entrepreneuriale.
Pixacare - Promotion 2018
L’utilisation des photos en médecine est quotidienne. Ces photos sont souvent 95% des cas faitent avec un smartphone et cela crée les problemes avec de sécurité, de temps de gestion des images etc.
Solution - c'est de gestion des photos intelligente et sécurisée.
Présent aujourd’hui dans 20 établissements de santé.
L’entreprise est toujours là aujourd’hui car elle a su développé un modèle économique pérenne.
Importance d’avoir des investisseurs et de la visibilité pour pouvoir démarrer et se développer dans la durée.
Les partenaires de l’écosystème :
5ans après :
20 salariés
2 millions € levés
22 centres utilisateurs
40 000 patients suivis e
t +250k photo.
Entreprendre en santé est du basejump …. Les barrières à l’entrée sont très élevées et les temps de décisions très long … mais très valorisant et valorisable !
Préférons le chameau à la licorne !
Fizimed
Présence internationale
La recommendation: profitez de ces 3 jours. N’ayez pas peur de la falaise. Les montagnes russes se lisseront avec le temps !
CES : Fizimed, Vedette française. Prix de l’innovation. Cet événement a véritablement boosté le développement de la start-up.
France. Allemagne (produit 100% remboursé), US, Asie ….
EANQA
EANQA - Ne cherchez plus un psy, trouvez le vôtre !
Synapse Médecine
Croissance forte ces 45 dernières années France, US, Japon.
Environ 100 collaborateurs.
40 millions levée de fond.
Solutions de prescriptions médicamenteuses.
Notre mission : aide à la décision
Persévérance works
How the team your are building is the company you are building
Osez ! Lancez vous! Faites !
Se tromper fait partie du process.
L’humain est le plus important.
HypnoVR
HHC Promotion 2016
Un service rendu aux patients.
Un contexte favorable : les thérapies digitales et non médicamenteuses.
Une prise de conscience : un usage raisonné de la pharmacologie.
La réalité virtuelle déjà évaluée. +de 20 ans d’utilisation
Un logiciel qui évolue en permanence.
Des cas d’usages qui se développent … avec toujours la difficulté de choisir entre l’exploitation et le focus.
Et puis un jour, il faut vendre et être au clair sur ce qu’on propose :
Licence logiciel
Pack matériel
Service
Et on vend à qui ?
Et ils achètent ? Yes
350 établissements nous font confiance !
Point essentiel : être bien entouré ! On ne fait pas tout seul ! L’équipe mais aussi l’écosystème.
Et l’aventure vaut le coup !!!!!
Notre ambition est de proposer HypnoVR partout dans le monde, car c’est une vraie alternative au traitement médicamenteux
C'est tout pour le moment. Vous puvez voire tout la premiere partie sur YouTube :
Mise à jour 16h00
Après la petite pause, le Hackathon a commencé ! Et pour rendre les choses intéressantes, cela a commencé par la présentation d'InterSystems par @Guillaume.Rongier7183 ! Vous pouvez regarder sa performance dans la vidéo ci-dessous :
Plus d'info sur notre Challenge est disponible ici.
Après cela, les pitchs des participants ont commencé.
Au milieu de cette action, les organisateurs ont décidé d'organiser une méditation et un léger échauffement pour soulager les tensions.
Après tous les pitches, les équipes commencent à se former. 1 coeur = 1 projet et c'est parti pour 50h de folie créative et collaborative !
Et c'est tout pour aujourd'hui. A demain !
Article
Lorenzo Scalese · Mai 12, 2022
IRIS External Table est un projet Open Source de la communauté InterSystems, qui vous permet d'utiliser des fichiers stockés dans le système de fichiers local et le stockage d'objets en nuage comme AWS S3, en tant que tables SQL.
![IRIS External Table][IRIS External Table]
Il peut être trouvé sur Github Open Exchange et est inclus dans InterSystems Package Manager ZPM.
Pour installer External Table depuis GitHub, utilisez :
git clone https://github.com/antonum/IRIS-ExternalTable.git
iris session iris
USER>set sc = ##class(%SYSTEM.OBJ).LoadDir("/IRIS-ExternalTable/src", "ck",,1)
Pour installer avec ZPM Package Manager, utilisez :
USER>zpm "install external-table"
## Travailler avec des fichiers locaux
Créons un fichier simple qui ressemble à ceci :
a1,b1
a2,b2
Ouvrez votre éditeur préféré et créez le fichier ou utilisez simplement une ligne de commande sous linux/mac :
echo $'a1,b1\na2,b2' > /tmp/test.txt
Dans IRIS SQL, créez une table pour représenter ce fichier :
create table test (col1 char(10),col2 char(10))
Convertissez la table pour utiliser le stockage externe :
CALL EXT.ConvertToExternal(
'test',
'{
"adapter":"EXT.LocalFile",
"location":"/tmp/test.txt",
"delimiter": ","
}')
Et enfin - interrogez la table :
select * from test
Si tout fonctionne comme prévu, vous devriez voir un résultat comme celui-ci :
col1 col2
a1 b1
a2 b2
Retournez maintenant dans l'éditeur, modifiez le contenu du fichier et réexécutez la requête SQL. Ta-Da !!! Vous lisez les nouvelles valeurs de votre fichier local en SQL.
col1 col2
a1 b1
a2 b99
## Lecture de données à partir de S3
Sur , vous pouvez avoir accès à des données constamment mises à jour sur le COVID, stockées par AWS dans la réserve publique de données.
Essayons d'accéder à l'une des sources de données de cette réserve de données : `s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states`
Si vous avez installé l'outil de ligne de commande AWS, vous pouvez répéter les étapes ci-dessous. Sinon, passez directement à la partie SQL. Vous n'avez pas besoin d'installer quoi que ce soit de spécifique à AWS sur votre machine pour suivre la partie SQL.
$ aws s3 ls s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/
2020-12-04 17:19:10 510572 us-states.csv
$ aws s3 cp s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv .
download: s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv to ./us-states.csv
$ head us-states.csv
date,state,fips,cases,deaths
2020-01-21,Washington,53,1,0
2020-01-22,Washington,53,1,0
2020-01-23,Washington,53,1,0
2020-01-24,Illinois,17,1,0
2020-01-24,Washington,53,1,0
2020-01-25,California,06,1,0
2020-01-25,Illinois,17,1,0
2020-01-25,Washington,53,1,0
2020-01-26,Arizona,04,1,0
Nous avons donc un fichier avec une structure assez simple. Cinq champs délimités.
Pour exposer ce dossier S3 en tant que table externe - d'abord, nous devons créer une table "normal" avec la structure désirée :
-- create external table
create table covid_by_state (
"date" DATE,
"state" VARCHAR(20),
fips INT,
cases INT,
deaths INT
)
Notez que certains noms de champs comme "Date" sont des mots réservés dans IRIS SQL et doivent être entourés de guillemets doubles.
Ensuite - nous devons convertir cette table "régulière" en table "externe", basé sur le godet AWS S3 et le type de CSV.
-- convertissez le tableau en stockage externe
call EXT.ConvertToExternal(
'covid_by_state',
'{
"adapter":"EXT.AWSS3",
"location":"s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/",
"type": "csv",
"delimiter": ",",
"skipHeaders": 1
}'
)
Si vous regardez de près - les arguments des procédures EXT.ExternalTable sont le nom de la table et ensuite une chaîne JSON, contenant plusieurs paramètres, tels que l'emplacement pour rechercher les fichiers, l'adaptateur à utiliser, le délimiteur, etc. En plus de AWS S3 External Table supporte le stockage Azure BLOB, Google Cloud Buckets et le système de fichiers local. GitHub Repo contient des références pour la syntaxe et les options supportées pour tous les formats.
Et enfin - faites une requête sur le tableau :
-- faites une requête sur le tableau :
select top 10 * from covid_by_state order by "date" desc
[SQL]USER>>select top 10 * from covid_by_state order by "date" desc
2. select top 10 * from covid_by_state order by "date" desc
date état fips cas morts
2020-12-06 Alabama 01 269877 3889
2020-12-06 Alaska 02 36847 136
2020-12-06 Arizona 04 364276 6950
2020-12-06 Arkansas 05 170924 2660
2020-12-06 California 06 1371940 19937
2020-12-06 Colorado 08 262460 3437
2020-12-06 Connecticut 09 127715 5146
2020-12-06 Delaware 10 39912 793
2020-12-06 District of Columbia 11 23136 697
2020-12-06 Florida 12 1058066 19176
L'interrogation des données de la tableau distant prend naturellement plus de temps que celle de la table "IRIS natif" ou global, mais ces données sont entièrement stockées et mises à jour sur le nuage et sont introduites dans IRIS en coulisse.
Explorons quelques autres caractéristiques de la table externe.
## %PATH et tables, sur la base de plusieurs fichiers
Dans notre exemple, le dossier du godet ne contient qu'un seul fichier. Le plus souvent, il contient plusieurs fichiers de la même structure, où le nom de fichier identifie soit l'horodatage, soit le numéro de périphérique, soit un autre attribut que nous voulons utiliser dans nos requêtes.
Le champ %PATH est automatiquement ajouté à chaque table externe et contient le chemin d'accès complet au fichier à partir duquel la ligne a été récupérée.
select top 5 %PATH, * from covid_by_state
%PATH date state fips cases deaths
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-21 Washington 53 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-22 Washington 53 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-23 Washington 53 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-24 Illinois 17 1 0
s3://covid19-lake/rearc-covid-19-nyt-data-in-usa/csv/us-states/us-states.csv 2020-01-24 Washington 53 1 0
Vous pouvez utiliser ce champ %PATH dans vos requêtes SQL comme n'importe quel autre champ.
## Données ETL vers des " tables réguliers "
Si votre tâche consiste à charger des données de S3 dans une table IRIS - vous pouvez utiliser l'External Table comme un outil ETL. Il suffit de le faire :
INSERT INTO internal_table SELECT * FROM external_table
Dans notre cas, si nous voulons copier les données COVID de S3 dans la table local :
--create local table
create table covid_by_state_local (
"date" DATE,
"state" VARCHAR(100),
fips INT,
cases INT,
deaths INT
)
--ETL from External to Local table
INSERT INTO covid_by_state_local SELECT TO_DATE("date",'YYYY-MM-DD'),state,fips,cases,deaths FROM covid_by_state
## JOIN entre IRIS tables natif et External Table. Requêtes fédérées
External Table est une table SQL. Il peut être joint à d'autres tables, utilisé dans des sous-sélections et des UNIONs. Vous pouvez même combiner la table IRIS "Régulier" et deux ou plusieurs tables externes provenant de sources différentes dans la même requête SQL.
Essayez de créer une table régulier, par exemple en faisant correspondre les noms d'État aux codes d'État, comme Washington - WA. Et joignez-la à notre table basé sur S3.
create table state_codes (name varchar(100), code char(2))
insert into state_codes values ('Washington','WA')
insert into state_codes values ('Illinois','IL')
select top 10 "date", state, code, cases from covid_by_state join state_codes on state=name
Remplacez 'join' par 'left join' pour inclure les lignes pour lesquelles le code d'état n'est pas défini. Comme vous pouvez le constater, le résultat est une combinaison de données provenant de S3 et de votre table IRIS natif.
## Accès sécurisé aux données
La réserve de données AWS Covid est publique. N'importe qui peut y lire des données sans aucune authentification ou autorisation. Dans la vie réelle, vous souhaitez accéder à vos données de manière sécurisée, afin d'empêcher les étrangers de jeter un coup d'œil à vos fichiers. Les détails complets de la gestion des identités et des accès (IAM) d'AWS n'entrent pas dans le cadre de cet article. Mais le minimum, vous devez savoir que vous avez besoin au moins de la clé d'accès au compte AWS et du secret afin d'accéder aux données privées de votre compte.
AWS utilise l'authentification par clé de compte/secrète autentification pour signer les demandes. https://docs.aws.amazon.com/general/latest/gr/aws-sec-cred-types.html#access-keys-and-secret-access-keys
Si vous exécutez IRIS External Table sur une instance EC2, la méthode recommandée pour gérer l'authentification est d'utiliser les rôles d'instance EC2 https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/iam-roles-for-amazon-ec2.html IRIS External Table sera en mesure d'utiliser les permissions de ce rôle. Aucune configuration supplémentaire n'est requise.
Sur une instance locale/non EC2, vous devez spécifier AWS_ACCESS_KEY_ID et AWS_SECRET_ACCESS_KEY en spécifiant des variables d'environnement ou en installant et en configurant le client AWS CLI.
export AWS_ACCESS_KEY_ID=AKIAEXAMPLEKEY
export AWS_SECRET_ACCESS_KEY=111222333abcdefghigklmnopqrst
Assurez-vous que la variable d'environnement est visible dans votre processus IRIS. Vous pouvez le vérifier en exécutant :
USER>write $system.Util.GetEnviron("AWS_ACCESS_KEY_ID")
Il doit renvoi la valeur de clé.
ou installer AWS CLI, en suivant les instructions ici https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2-linux.html et exécuter :
aws configure
External Table sera alors en mesure de lire les informations d'identification à partir des fichiers de configuration aws cli. Votre shell interactif et votre processus IRIS peuvent être exécutés sous différents comptes - assurez-vous d'exécuter `aws configure` sous le même compte que votre processus IRIS.
[IRIS External Table]: https://github.com/intersystems-community/IRIS-ExternalTable/raw/master/images/ExternalTableDiagram.png
Article
Iryna Mykhailova · Avr 18
IRIS propose une fonctionnalité dédiée à la gestion des documents JSON, appelée DocDB.
Plateforme de données DocDB d'InterSystems IRIS® est une fonctionnalité permettant de stocker et de récupérer des données de base de données. Elle est compatible avec le stockage et la récupération de données de tables et de champs SQL traditionnels (classe et propriété), mais en est distincte. Elle est basée sur JSON (JavaScript Object Notation) qui prend en charge l'échange de données sur le Web. InterSystems IRIS prend en charge le développement de bases de données et d'applications DocDB en REST et en ObjectScript, ainsi que le support SQL pour la création ou l'interrogation de données DocDB.
De par sa nature, la base de données documentaire InterSystems IRIS est une structure de données sans schéma. Cela signifie que chaque document a sa propre structure, qui peut différer de celle des autres documents de la même base de données. Cela présente plusieurs avantages par rapport au SQL, qui nécessite une structure de données prédéfinie.
Le mot « document » est utilisé ici comme un terme technique spécifique à l'industrie, en tant que structure de stockage de données dynamique. Le « document », tel qu'utilisé dans DocDB, ne doit pas être confondu avec un document textuel ou avec la documentation.
Voyons comment DocDB peut permettre de stocker JSON dans la base de données et de l'intégrer dans des projets qui reposent uniquement sur des protocoles xDBC.
Commençons!
DocDB définit deux composants clés:
%DocDB.Database - Bien qu'il s'attende à la création d'une "base de données", ce qui peut prêter à confusion puisque nous avons déjà une base de données en termes SQL, il s'agit essentiellement d'une classe en ObjectScript. Pour ceux qui sont plus familiers avec SQL, elle fonctionne comme une table.
%DocDB.Document - Classe de base pour une 'base de données' qui étend la classe %Persistent et introduit des propriétés spécifiques à DocDB:
%DocumentId - IdKey
%Doc As %DynamicAbstractObject - Le stockage actuel du document JSON
%LastModified - Un horodatage mis à jour automatiquement pour chaque insertion et mise à jour
Création d'une table (base de données)
Passons maintenant à la création de notre première table, ou plutôt de notre première « base de données ». Il semble que l'on ne s'attendait pas à la création d'une base de données DocDB.Database uniquement à l'aide de SQL. Par conséquent, il n'est pas possible de créer une nouvelle « base de données » en utilisant uniquement SQL. Pour le vérifier, nous allons utiliser une approche ObjectScript classique. Voici un exemple de définition d'une classe qui étend %DocDB.Document:
Class User.docdb Extends %DocDB.Document [ DdlAllowed ]
{
}
La vérification de la table nouvellement créée à l'aide de SQL permet de s'assurer de son bon fonctionnement.
Il est temps de faire un premier essai et d'insérer quelques données
Nous pouvons insérer n'importe quelles données sans validation, ce qui signifie qu'il n'y a aucune restriction sur ce qui peut être inséré dans %Doc. La mise en place d'une validation serait bénéfique.
Extraction de valeurs d'un document
La base de données %DocDB.Database permet d'extraire des propriétés des documents et de les rendre disponibles sous forme de colonnes dédiées. Cela permet également d'effectuer une indexation sur ces propriétés.
Il faudrait d'abord obtenir la base de données.
USER>set docdb=##class(%DocDB.Database).%GetDatabase("User.docdb")
<THROW>%GetDatabase+5^%DocDB.Database.1 *%Exception.StatusException ERROR #25351: DocDB Database 'User.docdb' does not exist.
USER 2e1>w $SYSTEM.DocDB.Exists("User.docdb")
0
Euh, la base de données "n'existe pas", d'accord, créons-la alors
USER>set docdb=##class(%DocDB.Database).%CreateDatabase("User.docdb")
<THROW>%CreateDatabase+13^%DocDB.Database.1 *%Exception.StatusException ERROR #25070: The generated class name for the database 'User.docdb' conflicts with another class: User.docdb
USER 2e1>
Ainsi, une simple définition de classe ne suffit pas. Il faut utiliser %DocDB.Database dès le début, ce qui n'est pas pratique, surtout lors de l'utilisation du contrôle de code source.
Pour résoudre ce problème, nous supprimons la classe existante et créons correctement la base de données:
USER>do $system.OBJ.Delete("User.docdb")
Deleting class User.docdb
USER>set docdb=##class(%DocDB.Database).%CreateDatabase("User.docdb")
USER>zwrite docdb
docdb=6@%DocDB.Database ; <OREF,refs=1>
+----------------- general information ---------------
| oref value: 6
| class name: %DocDB.Database
| %%OID: $lb("3","%DocDB.Database")
| reference count: 1
+----------------- attribute values ------------------
| %Concurrency = 1 <Set>
| ClassName = "User.docdb"
| DocumentType = ""
| Name = "User.docdb"
| Resource = ""
| SqlNameQualified = "SQLUser.docdb"
+-----------------------------------------------------
Cette fois, cela fonctionne et les données précédemment insérées restent intactes.
Supposons que nous ayons un document comme celui-ci
{"name":"test", "some_value":12345}
Extrayons ces deux champs à l'aide de la méthode %CreateProperty
USER>do docdb.%CreateProperty("name","%String","$.name",0)
USER>do docdb.%CreateProperty("someValue","%String","$.some_value",0)
Et vérifions la table
En vérifiant cette table, nous constatons que deux nouvelles colonnes ont été ajoutées, mais que celles-ci contiennent des valeurs nulles. Il semble que ces propriétés ne s'appliquent pas rétroactivement aux données existantes. Si un développeur ajoute ultérieurement des propriétés et des index à des fins d'optimisation, les données existantes ne refléteront pas automatiquement ces modifications.
Mettez à jour en utilisant la même valeur et vérifiez si %doc est json. Et nous obtenons notre valeur.
Jetons maintenant un coup d'œil à la classe, qui est entièrement créée et mise à jour par %DocDB.Database
Class User.docdb Extends %DocDB.Document [ Owner = {irisowner}, ProcedureBlock ]
{
Property name As %String [ SqlComputeCode = { set {*}=$$%EvaluatePathOne^%DocDB.Document({%Doc},"$.name")
}, SqlComputed, SqlComputeOnChange = %Doc ];
Property someValue As %String [ SqlComputeCode = { set {*}=$$%EvaluatePathOne^%DocDB.Document({%Doc},"$.some_value")
}, SqlComputed, SqlComputeOnChange = %Doc ];
Index name On name;
Index someValue On someValue;
}
Ainsi, les propriétés créées contiennent un code pour extraire la valeur de %Doc, et oui, elles ne sont remplies que lorsque %Doc est modifié. Et des index ont été créés pour les deux champs, sans que personne ne le demande. Le fait d'avoir de nombreuses valeurs extraites augmentera l'utilisation des variables globales simplement par le nombre d'index.
Il sera possible de mettre à jour ces propriétés créées, sans nuire au %Doc original, mais les valeurs deviendront inutiles.
Insertion de données non valides
Insert NULL
Chaîne vide ou tout texte non-json.
Réponse franchement moche, rien à ajouter, la validation des tentatives d'insertion de quelque chose d'illégal dans une table semble raisonnable, donc, le message d'erreur serait au moins quelque chose de significatif.
La base de données %DocDB.Database avec une méthode %GetProperty
USER>zw docdb.%GetPropertyDefinition("someValue")
{"Name":"someValue","Type":"%Library.String"} ; <DYNAMIC OBJECT>
USER>zw docdb.%GetPropertyDefinition("name")
{"Name":"name","Type":"%Library.String"} ; <DYNAMIC OBJECT>
Le chemin d'accès à la valeur qui a été utilisé dans %CreateProperty a disparu, il n'y a aucun moyen de le valider. Si le chemin d'accès est incorrect, pour le mettre à jour, il faut d'abord appeler %DropProperty puis à nouveau %CreateProperty.
%FindDocuments
%%DocDB.Database vous permet de rechercher des documents
Pour trouver un ou plusieurs documents dans une base de données et renvoyer ceux-ci au format JSON, appelez la méthode %FindDocuments(). Cette méthode accepte n'importe quelle combinaison de trois prédicats positionnels facultatifs : une matrice de restriction, une matrice de projection et une paire clé/valeur limite.
Plus important encore, %FindDocuments ne se soucie pas de %Doc lui-même, il ne fonctionne que sur les propriétés. Assez fragile, il lève des exceptions sur tout ce qui ne correspond pas à ce qui est attendu. En fait, il construit simplement une requête SQL et l'exécute.
USER>do docdb.%FindDocuments(["firstName","B","%STARTSWITH"]).%ToJSON()
<THROW>%FindDocuments+37^%DocDB.Database.1 *%Exception.StatusException ERROR #25541: DocDB Property 'firstName' does not exist in 'User.docdb'
USER>do docdb.%FindDocuments(["name","test","in"],["name"]).%ToJSON()
{"sqlcode":100,"message":null,"content":[{"name":"test"}]}
USER>do docdb.%FindDocuments(["name","","in"],["name"]).%ToJSON()
<THROW>%FindDocuments+37^%DocDB.Database.1 *%Exception.SQL -12 -12 A term expected, beginning with either of: identifier, constant, aggregate, $$, (, :, +, -, %ALPHAUP, %EXACT, %MVR %SQLSTRING, %SQLUPPER, %STRING, %TRUNCATE, or %UPPER^ SELECT name FROM SQLUser . docdb WHERE name IN ( )
USER>do docdb.%FindDocuments(["name","test","="]).%ToJSON()
{"sqlcode":100,"message":null,"content":[{"%Doc":"{\"name\":\"test\", \"some_value\":12345}","%DocumentId":"1","%LastModified":"2025-02-05 12:25:02.405"}]}
USER 2e1>do docdb.%FindDocuments(["Name","test","="]).%ToJSON()
<THROW>%FindDocuments+37^%DocDB.Database.1 *%Exception.StatusException ERROR #25541: DocDB Property 'Name' does not exist in 'User.docdb'
USER>do docdb.%FindDocuments(["%Doc","JSON","IS"]).%ToJSON()
<THROW>%FindDocuments+37^%DocDB.Database.1 *%Exception.StatusException ERROR #25540: DocDB Comparison operator is not valid: 'IS'
USER 2e1>do docdb.%FindDocuments(["%Doc","","IS JSON"]).%ToJSON()
<THROW>%FindDocuments+37^%DocDB.Database.1 *%Exception.StatusException ERROR #25540: DocDB Comparison operator is not valid: 'IS JSON'
L'utilisation de SQL simple serait bien plus fiable
Enregistrement
Un autre aspect très intéressant est l'efficacité avec laquelle JSON est enregistré dans la base de données.
^poCN.bvx3.1(1)=$lb("","2025-02-05 12:25:02.405","test",12345)
^poCN.bvx3.1(1,"%Doc")="{""name"":""test"", ""some_value"":12345}"
^poCN.bvx3.1(2)=$lb("","2025-02-05 12:25:02.405")
^poCN.bvx3.1(2,"%Doc")="[1,2,3]"
^poCN.bvx3.1(3)=$lb("","2025-02-05 12:01:18.542")
^poCN.bvx3.1(3,"%Doc")="test"
^poCN.bvx3.1(4)=$lb("","2025-02-05 12:01:19.445")
^poCN.bvx3.1(4,"%Doc")=$c(0)
^poCN.bvx3.1(5)=$lb("","2025-02-05 12:01:20.794")
Le JSON est stocké sous forme de texte brut, tandis que d'autres bases de données utilisent des formats binaires pour un enregistrement et une recherche plus efficaces. La base de données DocDB d'IRIS ne prend pas en charge la recherche directe dans le contenu des documents, sauf si JSON_TABLE est utilisé, ce qui nécessite tout de même l'analyse du JSON dans un format binaire interne.
Dans la version 2025.1, %DynamicAbstractObject introduit les méthodes %ToPVA et %FromPVA, ce qui semble enregistrer le JSON dans un format binaire.
USER>do ({"name":"value"}).%ToPVA($name(^JSON.Data(1)))
USER>zw ^JSON.Data
^JSON.Data(1,0,0)="PVA1"_$c(134,0,6,0,2,0,0,0,0,0,14,0,15,0,2,0,21,9,6,136,0,1,6,0,1,0,2,1,137,0,1,5,8,1,6)_"value"_$c(6,0,6)_"name"_$c(5)
USER>zw {}.%FromPVA($name(^JSON.Data(1)))
{"name":"value"} ; <DYNAMIC OBJECT,refs=1>
Cependant, le traitement de certaines structures présente des incohérences.
USER>do ({}).%ToPVA($name(^JSON.Data(1)))
<SYSTEM>%ToPVA+1^%Library.DynamicAbstractObject.1
USER>do ({"name":{}}).%ToPVA($name(^JSON.Data(1)))
<SYSTEM>%ToPVA+1^%Library.DynamicAbstractObject.1
Conclusion
Actuellement, %DocDB n'est vraiment pratique qu'avec ObjectScript et a des limites en SQL. Des problèmes de performances apparaissent lorsqu'il s'agit de traiter de grands ensembles de données. Tout ce que %DocDB offre peut être réalisé en utilisant du SQL de base tout en conservant un support SQL complet. Compte tenu de l'implémentation actuelle, il y a peu d'intérêt à utiliser DocDB plutôt que des approches SQL de base.
Article
Sylvain Guilbaud · Juin 12, 2023
Il y a souvent des questions concernant la configuration idéale du Serveur Web HTTPD Apache pour HealthShare. Le contenu de cet article décrit la configuration initiale recommandée du serveur Web pour tout produit HealthShare.
APour commencer, la version 2.4.x (64 bits) d'Apache HTTPD est recommandée. Des versions antérieures comme 2.2.x sont disponibles, mais la version 2.2 n'est pas recommandée pour les performances et l'évolutivité de HealthShare.
## **Configuration d'Apache**
### Module API Apache sans NSD {#ApacheWebServer-ApacheAPIModulewithoutNSD}
HealthShare requiert l'option d'installation Apache API Module without NSD. La version des modules liés dynamiquement dépend de la version d'Apache :
* CSPa24.so (Apache Version 2.4.x)
La configuration de Caché Server Pages dans le fichier Apache httpd.conf doit être effectuée par l'installation de HealthShare qui est détaillée plus loin dans ce document. Cependant, la configuration peut être effectuée manuellement. Pour plus d'informations, veuillez consulter le guide de configuration d'Apache dans la documentation d'InterSystems : Recommended Option: Apache API Module without NSD (CSPa24.so)
## **Recommandations concernant le module multiprocesseur d'Apache (MPM)** {#ApacheWebServer-ApacheMulti-ProcessingModule(MPM)Recommendations}
### Apache Prefork MPM Vs. Worker MPM {#ApacheWebServer-ApachePreforkMPMVs.WorkerMPM}
Le serveur web HTTPD Apache est livré avec trois modules multiprocesseurs (MPM) : Prefork, Worker et Event. Les MPM sont responsables de la liaison avec les ports réseau de la machine, de l'acceptation des requêtes et de l'envoi de fils pour traiter ces requêtes. Par défaut, Apache est généralement configuré avec le MPM Prefork, qui n'est pas adapté à des charges de travail importantes en termes de transactions ou d'utilisateurs simultanés.
Pour les systèmes de production HealthShare, le MPM Apache **_Worker_** doit être activé pour des raisons de performance et d'évolutivité. Worker MPM est préféré pour les raisons suivantes :
* Prefork MPM utilise plusieurs processus enfants avec un fil d'exécution chacun et chaque processus gère une connexion à la fois. Lorsque Prefork est utilisé, les demandes simultanées souffrent car, comme chaque processus ne peut traiter qu'une seule demande à la fois, les demandes sont mises en attente jusqu'à ce qu'un processus serveur se libère. De plus, afin d'évoluer, il faut plus de processus enfants Prefork, ce qui consomme des quantités importantes de mémoire.
* Worker MPM utilise plusieurs processus enfants avec de nombreux fils d'exécution chacun. Chaque fil d'exécution gère une connexion à la fois, ce qui favorise la concurrence et réduit les besoins en mémoire. Worker gère mieux la concurrence que Prefork, car il y aura généralement des fils d'exécution libres disponibles pour répondre aux demandes au lieu des processus Prefork à un seul fil d'exécution qui peuvent être occupés.
### Paramètres MPM pour Apache Worker {#ApacheWebServer-ApacheWorkerMPMParameters}
En utilisant des fils d'exécution pour servir les demandes, Worker est capable de servir un grand nombre de demandes avec moins de ressources système que le serveur basé sur le processus Prefork.
Les directives les plus importantes utilisées pour contrôler le MPM de Worker sont **ThreadsPerChild** qui contrôle le nombre de fils d'exécution déployés par chaque processus enfant et **MaxRequestWorkers** qui contrôle le nombre total maximum de fils d'exécution pouvant être lancés.
Les valeurs recommandées de la directive commune Worker MPM sont détaillées dans le tableau ci-dessous :
<caption>Paramètres recommandés pour le serveur web HTTPD Apache</caption>
Les Directives MPM pour Apache Worker
Valeur recommandée
Commentaires
MaxRequestWorkers
Nombre maximal d'utilisateurs simultanés de HealthShare Clinical Viewer, ou des quatre autres composants de HealthShare, fixé à la somme de toutes les tailles de pool de services commerciaux entrants pour toutes les productions d'interfaces définies. * Note : Si toutes les inconnues au moment de la configuration commencent par une valeur de '1000'
MaxRequestWorkers fixe la limite du nombre de demandes simultanées qui seront servies, c'est-à-dire qu'il restreint le nombre total de fils d'exécution qui seront disponibles pour servir les clients. Il est important que MaxRequestWorkers soit défini correctement car s'il est trop faible, les ressources seront gaspillées et s'il est trop élevé, les performances du serveur seront affectées. Notez que lorsque le nombre de connexions tentées est supérieur au nombre de travailleurs, les connexions sont placées dans une file d'attente. La file d'attente par défaut peut être ajustée avec la directive ListenBackLog.
MaxSpareThreads
250
MaxSpareThreads traite les threads inactifs à l'échelle du serveur. S'il y a trop de threads inactifs dans le serveur, les processus enfants sont tués jusqu'à ce que le nombre de threads inactifs soit inférieur à ce nombre. L'augmentation du nombre de threads inutilisés par rapport à la valeur par défaut permet de réduire les risques de réactivation des processus.
MinSpareThreads
75
MinSpareThreads traite les fils d'exécution inactifs à l'échelle du serveur. S'il n'y a pas assez de fils d'exécution libres dans le serveur, des processus enfants sont créés jusqu'à ce que le nombre de fils d'exécution libres soit supérieur à ce nombre. En réduisant le nombre de fils d'exécution inutilisés par rapport à la valeur par défaut, on réduit les risques de réactivation des processus.
ServerLimit
MaxRequestWorkers divisé par ThreadsPerChild
Valeur maximale de MaxRequestWorkers pour la durée de vie du serveur. ServerLimit est une limite stricte du nombre de processus enfants actifs, et doit être supérieure ou égale à la directive MaxRequestWorkers divisée par la directive ThreadsPerChild. Avec worker, n'utilisez cette directive que si vos paramètres MaxRequestWorkers et ThreadsPerChild nécessitent plus de 16 processus serveur (valeur par défaut).
StartServers
20
La directive StartServers définit le nombre de processus de serveur enfant créés au démarrage. Comme le nombre de processus est contrôlé dynamiquement en fonction de la charge, il y a généralement peu de raisons d'ajuster ce paramètre, sauf pour s'assurer que le serveur est prêt à gérer un grand nombre de connexions dès son démarrage.
ThreadsPerChild
25
Cette directive définit le nombre de threads créés par chaque processus enfant, 25 par défaut. Il est recommandé de conserver la valeur par défaut car l'augmenter pourrait conduire à une dépendance excessive vis-à-vis d'un seul processus.
Pour plus d'informations, veuillez consulter la documentation relative à la version d'Apache concernée :
* [Apache 2.4 Directives communes de MPM](http://httpd.apache.org/docs/2.4/mod/mpm_common.html)
### Exemple de configuration MPM du travailleur Apache 2.4 {#ApacheWebServer-ExampleApache2.4WorkerMPMConfiguration}
Cette section explique comment configurer Worker MPM pour un serveur Web RHEL7 Apache 2.4 nécessaire pour prendre en charge jusqu'à 500 utilisateurs simultanés de TrakCare.
1. Vérifiez d'abord le MPM en utilisant la commande suivante :
2. Modifiez le fichier de configuration /etc/httpd/conf.modules.d/00-mpm.conf selon les besoins, en ajoutant et en supprimant le caractère de commentaire # afin que seuls les modules Worker MPM soient chargés. Modifiez la section Worker MPM avec les valeurs suivantes dans le même ordre que ci-dessous :
3. Redémarrer Apache
4. Après avoir redémarré Apache avec succès, validez les processus worker en exécutant les commandes suivantes. Vous devriez voir quelque chose de similaire à ce qui suit confirmant le processus httpd.worker :
## **Renforcement d'Apache** {#ApacheWebServer-ApacheHardening}
### Modules requis pour Apache {#ApacheWebServer-ApacheRequiredModules}
L'installation du paquetage officiel d'Apache activera par défaut un ensemble spécifique de modules Apache. Cette configuration par défaut d'Apache chargera ces modules dans chaque processus httpd. Il est recommandé de désactiver tous les modules qui ne sont pas nécessaires à HealthShare pour les raisons suivantes :
* réduire l'empreinte du processus du démon httpd.
* réduire le risque d'un défaut de segmentation dû à un module malveillant.
* réduire les vulnérabilités en matière de sécurité.
Le tableau ci-dessous détaille les modules Apache recommandés pour HealthShare. Tout module qui ne figure pas dans la liste ci-dessous peut être désactivé :
| Nom du module | Description |
| ----------- | --------------------------------------------------------------------------------------------- |
| alias | Mappage des différentes parties du système de fichiers de l'hôte dans l'arborescence du document et pour la redirection des URL. |
| authz_host | Fournit un contrôle d'accès basé sur le nom d'hôte du client, l'adresse IP. |
| dir | Permet de rediriger les barres obliques et de servir les fichiers d'index des répertoires. |
| headers | Pour contrôler et modifier les en-têtes de demande et de réponse HTTP |
| log_config | Journalisation des requêtes adressées au serveur. |
| mime | Associe les extensions du nom de fichier demandé avec le comportement et le contenu du fichier|
| negotiation | Permet de sélectionner le contenu du document qui correspond le mieux aux capacités du client.|
| setenvif | Permet de définir des variables d'environnement en fonction des caractéristiques de la demande|
| status | Affiche l'état du serveur et les statistiques de performance |
### Désactivation des modules
Les modules inutiles doivent être désactivés pour renforcer la configuration qui réduira les vulnérabilités de sécurité. Le client est responsable de la politique de sécurité du serveur web. Au minimum, les modules suivants doivent être désactivés.
| Nom du module | Description |
| ---------- | -------------------------------------------------------------------------------------------------------------------- |
| asis | Envoie des fichiers qui contiennent leurs propres titres HTTP |
| autoindex | Génère des indices de répertoire et affiche la liste des répertoires lorsqu'aucun fichier index.html n'est présent |
| env | Modifie la variable d'environnement transmise aux scripts CGI et aux pages SSI |
| cgi | cgi - Exécution de scripts CGI |
| actions | Exécution de scripts CGI en fonction du type de média ou de la méthode de demande, déclenchement d'actions sur les demandes |
| include | Documents HTML analysés par le serveur (Server Side includes) |
| filter | Filtrage intelligent des demandes |
| version | Gestion des informations de version dans les fichiers de configuration à l'aide de IfVersion |
| userdir | Mappage des requêtes vers des répertoires spécifiques à l'utilisateur. Par exemple, ~nom d'utilisateur dans l'URL sera traduit en un répertoire dans le serveur |
## **Apache SSL/TLS** {#ApacheWebServer-ApacheSSL/TLS}
Pour protéger les données en transit, assurer la confidentialité et l'authentification, InterSystems recommande que toutes les communications TCP/IP entre les serveurs et les clients de HealthShare soient cryptées avec SSL/TLS, et InterSystems recommande également d'utiliser HTTPS pour toutes les communications entre le navigateur client des utilisateurs et la couche serveur web de l'architecture proposée. Veillez à consulter les politiques de sécurité de votre organisation pour vous assurer de la conformité à toute exigence de sécurité spécifique de votre organisation.
Le client est responsable de la fourniture et de la gestion des certificats SSL/TLS.
Si vous utilisez des certificats SSL, ajoutez le module ssl\_ (mod\_ssl.so).
## **Paramètres supplémentaires de durcissement d'Apache** {#ApacheWebServer-AdditionalHardeningApacheParameters}
Pour renforcer la configuration d'Apache, apportez les modifications suivantes au fichier httpd.conf :
* TraceEnable doit être désactivé pour éviter les problèmes potentiels de traçage intersites.

* ServerSignature doit être désactivé afin que la version du serveur web ne soit pas affichée.

## Paramètres de configuration supplémentaires d'Apache {#ApacheWebServer-SupplementalApacheConfigurationParameters}
### Keep-Alive {#ApacheWebServer-Keep-Alive}
Le paramètre Apache Keep-Alive permet d'utiliser la même connexion TCP pour la communication HTTP au lieu d'ouvrir une nouvelle connexion pour chaque nouvelle demande, c'est-à-dire que Keep-Alive maintient une connexion persistante entre le client et le serveur. Lorsque l'option Keep-Alive est activée, l'amélioration des performances provient de la réduction de l'encombrement du réseau, de la réduction de la latence des requêtes ultérieures et de la diminution de l'utilisation du CPU causée par l'ouverture simultanée de connexions. L'option Keep-Alive est activée par défaut et la norme HTTP v1.1 stipule qu'elle doit être présumée activée.
Cependant, l'activation de la fonction Keep-Alive présente des inconvénients : Internet Explorer doit être IE10 ou supérieur pour éviter les problèmes de délai d'attente connus avec les anciennes versions d'IE. De même, les intermédiaires tels que les pare-feu, les équilibreurs de charge et les proxies peuvent interférer avec les "connexions TCP persistantes" et entraîner une fermeture inattendue des connexions.
Lorsque vous activez la fonction "Keep-Alive", vous devez également définir le délai d'attente de cette fonction. Le délai d'attente par défaut pour Apache est trop faible et doit être augmenté pour la plupart des configurations, car des problèmes peuvent survenir en cas de rupture des requêtes AJAX (c'est-à-dire hyperevent). Ces problèmes peuvent être évités en s'assurant que le délai d'attente du serveur est supérieur à celui du client. En d'autres termes, c'est le client, et non le serveur, qui devrait fermer la connexion. Des problèmes surviennent - principalement dans IE mais dans une moindre mesure dans d'autres navigateurs - lorsque le navigateur tente d'utiliser une connexion (en particulier pour un POST) dont il s'attend à ce qu'elle soit ouverte.
Voir ci-dessous les valeurs recommandées de KeepAlive et KeepAliveTimeout pour un serveur Web HealthShare.
Pour activer KeepAlive dans Apache, apportez les modifications suivantes au fichier httpd.conf :

### Psserelle CSP {#ApacheWebServer-CSPGateway}
Pour le paramètre CSP Gateway KeepAlive, laissez la valeur par défaut No Action car le statut KeepAlive est déterminé par les titres de la réponse HTTP pour chaque requête.
Article
Guillaume Rongier · Avr 6, 2022

Dans les parties précédentes ([1](https://community.intersystems.com/post/globals-are-magic-swords-managing-data-part-1) et [2](https://community.intersystems.com/post/globals-magic-swords-storing-data-trees-part-2)) nous avons parlé des globales en tant qu'arbres. Dans cet article, nous allons les considérer comme des listes éparses.
[Une liste éparse](https://en.wikipedia.org/wiki/Sparse_matrix) - est un type de liste où la plupart des valeurs ont une valeur identique.
En pratique, vous verrez souvent des listes éparses si volumineuses qu'il est inutile d'occuper la mémoire avec des éléments identiques. Il est donc judicieux d'organiser les listes éparses de telle sorte que la mémoire ne soit pas gaspillée pour stocker des valeurs en double.
Dans certains langages de programmation, les listes éparses font partie intégrante du langage - par exemple, [in J](http://www.jsoftware.com/help/dictionary/d211.htm), [MATLAB](http://www.mathworks.com/help/matlab/ref/sparse.html). Dans d'autres langages, il existe des bibliothèques spéciales qui vous permettent de les utiliser. Pour le C++, [il s'agit de Eigen](http://eigen.tuxfamily.org/dox-devel/GettingStarted.html) et d'autres bibliothèques de ce type.
Les globales sont de bons candidats pour la mise en œuvre de listes éparses pour les raisons suivantes :
1. Ils stockent uniquement les valeurs de nœuds particuliers et ne stockent pas les valeurs indéfinies ;
2. L'interface d'accès à une valeur de nœud est extrêmement similaire à ce que de nombreux langages de programmation proposent pour accéder à un élément d'une liste multidimensionnelle.
Set ^a(1, 2, 3)=5
Write ^a(1, 2, 3)
3. Une structure globale est une structure de niveau assez bas pour le stockage des données, ce qui explique pourquoi les globales possèdent des caractéristiques de performance exceptionnelles (des centaines de milliers à des dizaines de millions de transactions par seconde selon le matériel, voir [1](http://www.intersystems.com/library/library-item/data-scalability-with-intersystems-cache-and-intel-processors/))
> Puisqu'une globale est une structure persistante, il n'est logique de créer des listes éparses sur leur base que dans les situations où vous savez à l'avance que vous disposerez de suffisamment de mémoire pour elles.
L'une des nuances de la mise en œuvre des listes éparses est le retour d'une certaine valeur par défaut si vous vous adressez à un élément indéfini.
Ceci peut être mis en œuvre en utilisant la fonction [$GET](http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_fget) dans COS. Prenons l'exemple d'une liste tridimensionnelle.
SET a = $GET(^a(x,y,z), defValue)
Quel type de tâches nécessite des listes éparses et comment les globales peuvent-elles vous aider ?
## Matrice d'adjacence
[Ces matrices](https://en.wikipedia.org/wiki/Adjacency_matrix) sont utilisées pour la représentation des graphiques :
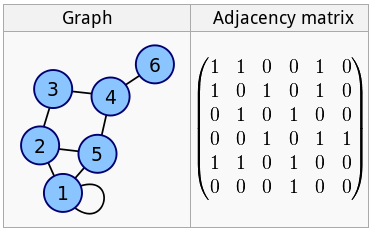
Il est évident que plus un graphe est grand, plus il y aura de zéros dans la matrice. Si nous regardons le graphe d'un réseau social, par exemple, et que nous le représentons sous la forme d'une matrice de ce type, il sera principalement constitué de zéros, c'est-à-dire qu'il s'agira d'une liste éparse.
Set ^m(id1, id2) = 1
Set ^m(id1, id3) = 1
Set ^m(id1, id4) = 1
Set ^m(id1) = 3
Set ^m(id2, id4) = 1
Set ^m(id2, id5) = 1
Set ^m(id2) = 2
....
Dans cet exemple, nous allons sauvegarder la matrice d'adjacence dans le **^m** globale, ainsi que le nombre d'arêtes de chaque nœud (qui est ami et avec qui et le nombre d'amis).
Si le nombre d'éléments du graphique ne dépasse pas 29 millions (ce nombre est calculé comme 8 * [longueur maximale de la chaîne](http://docs.intersystems.com/cache201512/csp/docbook/DocBook.UI.Page.cls?KEY=GORIENT_appx_limits_long_string)), il existe même une méthode plus économique pour stocker de telles matrices - les chaines binaires, car elles optimisent les grands espaces d'une manière spéciale.
Les manipulations de chaînes binaires sont effectuées à l'aide de la fonction [$BIT](http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_fbit).
; setting a bit
SET $BIT(rowID, positionID) = 1
; getting a bit
Write $BIT(rowID, positionID)
## Tableau des commutateurs FSM
Le graphe des commutateurs FSM étant un graphe régulier, le tableau des commutateurs FSM est essentiellement la même matrice d'adjacence dont nous avons parlé précédemment.
## Automates cellulaires

L'automate cellulaire le plus célèbre est [le jeu "Life"](https://en.wikipedia.org/wiki/Conway%27s_Game_of_Life), dont les règles (lorsqu'une cellule a de nombreux voisins, elle meurt) en font essentiellement une liste éparse.
Stephen Wolfram estime que les automates cellulaires représentent un [nouveau domaine de la science](https://en.wikipedia.org/wiki/A_New_Kind_of_Science). En 2002, il a publié un livre de 1280 pages intitulé "A New Kind of Science", dans lequel il affirme que les réalisations dans le domaine des automates cellulaires ne sont pas isolées, mais sont plutôt stables et importantes pour tous les domaines de la science.
Il a été prouvé que tout algorithme qui peut être traité par un ordinateur peut également être mis en œuvre à l'aide d'un automate cellulaire. Les automates cellulaires sont utilisés pour simuler des environnements et des systèmes dynamiques, pour résoudre des problèmes algorithmiques et à d'autres fins.
Si nous avons un champ considérable et que nous devons enregistrer tous les états intermédiaires d'un automate cellulaire, il est logique d'utiliser les globales.
## Cartographie
La première chose qui me vient à l'esprit lorsqu'il s'agit d'utiliser des listes éparses est la cartographie.
En règle générale, les cartes comportent beaucoup d'espace vide. Si nous imaginons que la carte du monde est composée de grands pixels, nous verrons que 71 % de tous les pixels de la Terre seront occupés par le réseau creux de l'océan. Et si nous ajoutons uniquement des structures artificielles à la carte, il y aura plus de 95 % d'espace vide.
Bien sûr, personne ne stocke les cartes sous forme de tableaux bitmap, tout le monde utilise plutôt la représentation vectorielle.
Mais en quoi consistent les cartes vectorielles ? C'est une sorte de cadre avec des polylignes et des polygones.
En fait, il s'agit d'une base de données de points et de relations entre eux.
L'une des tâches les plus difficiles en cartographie est la création d'une carte de notre galaxie réalisée par le télescope Gaia. Au sens figuré, notre galaxie est un gigantesque réseau creux : d'immenses espaces vides avec quelques points lumineux occasionnels - des étoiles. C'est 99,999999.......% d'espace absolument vide. Caché, une base de données basée sur des globales, a été choisie pour stocker la carte de notre galaxie.
Je ne connais pas la structure exacte des globales dans ce projet, mais je peux supposer que c'est quelque chose comme ça :
Set ^galaxy(b, l, d) = 1; le numéro de catalogue de l'étoile, s'il existe
Set ^galaxy(b, l, d, "name") = "Sun"
Set ^galaxy(b, l, d, "type") = "normal" ; les autres options peuvent inclure un trou noir, quazar, red_dwarf et autres.
Set ^galaxy(b, l, d, "weight") = 14E50
Set ^galaxy(b, l, d, "planetes") = 7
Set ^galaxy(b, l, d, "planetes", 1) = "Mercure"
Set ^galaxy(b, l, d, "planetes", 1, weight) = 1E20
...
_Où b, l, d représentent_ _[coordonnées galactiques](https://en.wikipedia.org/wiki/Galactic_coordinate_system): la latitude, la longitude et la distance par rapport au Soleil._
La structure flexible des globales vous permet de stocker toutes les caractéristiques des étoiles et des planètes, puisque les bases de données basées sur les globales sont exemptes de schéma.
Caché a été choisi pour stocker la carte de notre univers non seulement en raison de sa flexibilité, mais aussi grâce à sa capacité à sauvegarder rapidement un fil de données tout en créant simultanément des globales d'index pour une recherche rapide.
Si nous revenons à la Terre, les globales ont été utilisées dans des projets axés sur les cartes comme [OpenStreetMap XAPI](http://wiki.openstreetmap.org/wiki/Xapi) et FOSM, un branchement d'OpenStreetMap.
Récemment, lors d'un hackathon Caché, un groupe de développeurs a mis en œuvre des [index géospatiaux](https://github.com/intersystems-ru/spatialindex) en utilisant cette technologie. Pour plus de détails, consultez [l'article](https://community.intersystems.com/post/creating-custom-index-type-cach%C3%A9).
### Mise en œuvre d'index géospatiaux à l'aide de globales dans OpenStreetMap XAPI
[Les illustrations sont tirées de cette présentation](http://www.slideshare.net/george.james/fosdem-2010-gtm-and-openstreetmap).
Le globe entier est divisé en carrés, puis en sous-carrés, puis en encore plus de sous-carrés, et ainsi de suite. Au final, nous obtenons une structure hiérarchique pour laquelle les globales ont été créées.

À tout moment, nous pouvons instantanément demander n'importe quelle case ou la vider, et toutes les sous-carrés seront également retournées ou vidées.
Un schéma détaillé basé sur les globales peut être mis en œuvre de plusieurs façons.
Variante 1:
Set ^m(a, b, a, c, d, a, b,c, d, a, b, a, c, d, a, b,c, d, a, 1) = idPointOne
Set ^m(a, b, a, c, d, a, b,c, d, a, b, a, c, d, a, b,c, d, a, 2) = idPointTwo
...
Variante 2:
Set ^m('abacdabcdabacdabcda', 1) = idPointOne
Set ^m('abacdabcdabacdabcda', 2) = idPointTwo
...
Dans les deux cas, il ne sera pas très difficile dans COS/M de demander des points situés dans un carré de n'importe quel niveau. Il sera un peu plus facile de dégager des segments d'espace carrés de n'importe quel niveau dans la première variante, mais cela est rarement nécessaire.
Un exemple de carré de bas niveau :

Et voici quelques globales du projet XAPI : représentation d'un index basé sur des globales :

La globale **^voie** est utilisé pour stocker les sommets des [polylines](https://en.wikipedia.org/wiki/Polygonal_chain) (routes, petites rivières, etc.) et des polygones (zones fermées : bâtiments, bois, etc.).
## Une classification approximative de l'utilisation des listes éparses dans les globales.
1. Nous stockons les coordonnées de certains objets et leur état (cartographie, automates cellulaires).
2. Nous stockons des matrices creuses.
Dans la variante 2), lorsqu'une certaine coordonnée est demandée et qu'aucune valeur n'est attribuée à un élément, nous devons obtenir la valeur par défaut de l'élément de la liste éparse.
## Les avantages que nous obtenons en stockant des matrices multidimensionnelles dans les globales
**Suppression et/ou sélection rapide de segments d'espace qui sont des multiples de chaînes, de surfaces, de cubes, etc.** Pour les cas avec des index intégraux, il peut être pratique de pouvoir supprimer et/ou sélectionner rapidement des segments d'espace qui sont des multiples de chaînes, de surfaces, de cubes, etc.
La commande [Kill](http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_ckill) permet de supprimer un élément autonome, une chaîne de caractères et même une surface entière. Grâce aux propriétés de la globale, elle se produit très rapidement, mille fois plus vite que la suppression élément par élément.
L'illustration montre un tableau tridimensionnel dans la globale **^a** et différents types d'enlèvements.
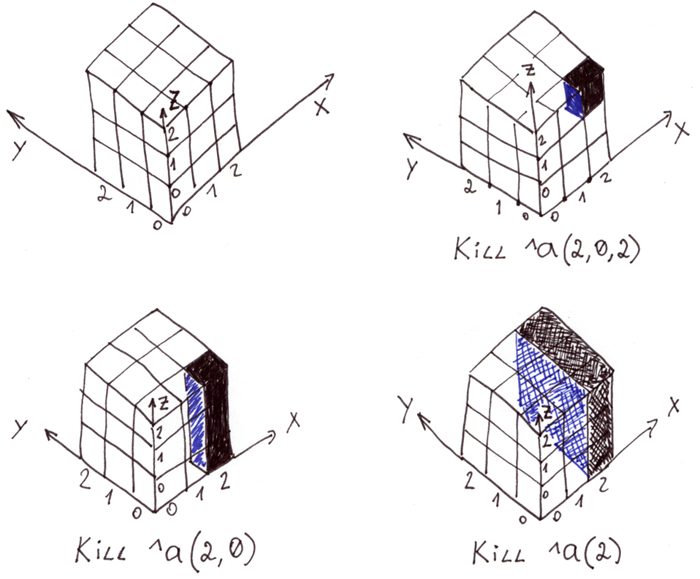
Pour sélectionner des segments d'espace par des indices connus, vous pouvez utiliser la commande [Merge](http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_cmerge).
Sélection d'une colonne de la matrice dans la colonne Variable :
; Définissons un tableau tridimensionnel creux 3x3x3
Set ^a(0,0,0)=1,^a(2,2,0)=1,^a(2,0,1)=1,^a(0,2,1)=1,^a(2,2,2)=1,^a(2,1,2)=1
Colonne de fusion = ^a(2,2)
; Produisons la colonne Variable
Zwrite colonne
Produit :
Column(0)=1
Colonne(2)=1
Ce qui est intéressant, c'est que nous avons obtenu un tableau épars dans la colonne Variable que vous pouvez adresser via [$GET](http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_fget) puisque les valeurs par défaut ne sont pas stockées ici.
La sélection de segments d'espace peut également se faire à l'aide d'un petit programme utilisant la fonction [$Order](http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_forder). Ceci est particulièrement utile pour les espaces dont les indices ne sont pas quantifiés (cartographie).
## Conclusion
Les réalités d'aujourd'hui posent de nouveaux défis. Les graphes peuvent comporter des milliards de sommets, les cartes peuvent avoir des milliards de points, certains peuvent même vouloir lancer leur propre univers basé sur des automates cellulaires ([1](http://lenta.ru/news/2009/08/28/universe/), [2](http://www.worldscientific.com/worldscibooks/10.1142/4702)).
Lorsque le volume de données dans les listes éparses ne peut pas être comprimé dans la RAM, mais que vous devez quand même travailler avec elles, vous devriez envisager de mettre en œuvre de tels projets en utilisant des globales et des COS.
Clause de non-responsabilité :: cet article et les commentaires le concernant reflètent uniquement mon opinion et n'ont rien à voir avec la position officielle de la société d'InterSystems.
Article
Irène Mykhailova · Juin 7, 2022
Pour chaque propriété, requête ou index défini, plusieurs méthodes correspondantes seraient automatiquement générées lors de la compilation d'une classe. Ces méthodes peuvent être très utiles. Dans cet article, je décrirai certaines d'entre elles.
Properties
Disons que vous avez défini une propriété nommée "Property". Les méthodes suivantes seraient automatiquement disponibles (la propriété indiquée en gras est une partie variable, égale au nom de la propriété) :
ClassMethod PropertyGetStored(id)
Pour les propriétés de type de données, cette méthode renvoie leur valeur logique, pour les propriétés d'objet, elle renvoie l'id. C'est une référence globale wrappée à la globale de données de la classe et le moyen le plus rapide de récupérer la valeur de la propriété singulière. Cette méthode n'est disponible que pour les propriétés stockées.
Method PropertyGet()
C'est un getter de propriété. Peut être redéfini.
Method PropertySet(val) As %Status
C'est un définisseur de propriété. Peut être redéfini.
Propriétés de l'objet
S'il s'agit d'une propriété objet, certaines méthodes supplémentaires, liées à l'accès aux ID et OID, deviennent disponibles :
Method PropertySetObjectId(id)
Cette méthode définit la valeur de la propriété par ID, il n'est donc pas nécessaire d'ouvrir un objet pour le définir comme valeur de la propriété.
Method PropertyGetObjectId()
Cette méthode renvoie l'ID de la valeur de la propriété.
Method PropertySetObject(oid)
Cette méthode définit la valeur de la propriété par OID.
Method PropertyGetObject()
Cette méthode renvoie l'OID de la valeur de la propriété.
Propriétés du type de données
Pour une propriété de type de données, plusieurs autres méthodes de conversion entre différents formats sont disponibles :
ClassMethod PropertyDisplayToLogical(val)
ClassMethod PropertyLogicalToDisplay(val)
ClassMethod PropertyOdbcToLogical(val)
ClassMethod PropertyLogicalToOdbc(val)
ClassMethod PropertyXSDToLogical(val)
ClassMethod PropertyLogicalToXSD(val)
ClassMethod PropertyIsValid(val) As %Status
Vérification de la validité de la valeur de la propriété
ClassMethod PropertyNormalize(val)
Renvoi de la valeur logique normalisée
**Remarques**
* Les relations constituent des propriétés et peuvent être obtenues ou définies à l'aide des méthodes suivantes
L'entrée val est toujours une valeur logique, sauf pour les méthodes de conversion de format.
Index
Pour un index nommé "Index", les méthodes suivantes seraient automatiquement disponibles
ClassMethod IndexExists(val) As %Boolean
Renvoi de 1 ou 0 selon l'existence d'un objet avec ce val, où val est une valeur logique de la propriété indexée.
Index uniques
Pour les index uniques, des méthodes supplémentaires sont disponibles :
ClassMethod IndexExists(val, Output id) As %Boolean
Renvoi de 1 ou 0 en fonction de l'existence d'un objet avec ce val, où val est une valeur logique de la propriété indexée. Renvoi également de l'identifiant de l'objet (s'il a été trouvé) comme second argument.
ClassMethod IndexDelete(val, concurrency = -1) As %Status
Suppression de l'entrée dont la valeur d'index est égale à val.
ClassMethod IndexOpen(val, concurrency, sc As %Status)
Renvoi de l'objet existant dont l'indice est égal à val.
**Remarques:**
a) Étant donné qu'un index peut être basé sur plusieurs propriétés, la signature de la méthode serait modifiée pour avoir plusieurs valeurs en entrée, par exemple, considérez cet index :
Index MyIndex On (Prop1, Prop2);
La méthode IndexExists aurait alors la signature suivante :
ClassMethod IndexExists(val1, val2) As %Boolean
Où val1 correspond à la valeur de Prop1 et val2 correspond à la valeur de Prop2. Les autres méthodes suivent la même logique.
b) Caché génère un index IDKEY qui indexe le champ ID (RowID). Il peut être redéfini par l'utilisateur et peut également contenir plusieurs propriétés. Par exemple, pour vérifier si une classe a une propriété définie, exécutez :
Write ##class(%Dictionary.PropertyDefinition).IDKEYExists(class, property)
c) Toutes les méthodes d'indexation vérifient la présence d'une valeur logique
d) Documentation
Requêtes
En ce qui concerne une requête (qui peut être une simple requête SQL ou une requête de classe personnalisée, voici mon [post](https://community.intersystems.com/post/class-queries-intersystems-cache%CC%81) à ce sujet) nommée "Query", la méthode Func est générée :
ClassMethod QueryFunc(Arg1, Arg2) As %SQL.StatementResult
qui renvoie un %SQL.StatementResult utilisé pour itérer sur la requête. Par exemple, la classe Sample.Person de l'espace de noms Samples possède une requête ByName acceptant un paramètre. Elle peut être appelée depuis le contexte objet au moyen de ce code :
Set ResultSet=##class(Sample.Person).ByNameFunc("A")
While ResultSet.%Next() { Write ResultSet.Name,! }
En outre, une classe de démonstration sur [GitHub](https://github.com/eduard93/Utils/blob/master/Utils/GeneratedMethods.cls.xml) illustre ces méthodes.
Article
Kevin Koloska · Nov 30, 2022
Suite de tests d’E/S PerfTools
#Analytics #Caché #HealthShare #InterSystems IRIS #Open Exchange #TrakCare
But
Cette paire d’outils (RanRead et RanWrite) est utilisée pour générer des événements de lecture et d’écriture aléatoires dans une base de données (ou une paire de bases de données) afin de tester les opérations d’entrée/sortie par seconde (IOPS). Ils peuvent être utilisés conjointement ou séparément pour tester la capacité matérielle des E/S, valider les IOPS cibles et garantir des temps de réponse disque acceptables. Les résultats recueillis à partir des tests d’E/S varient d’une configuration à l’autre en fonction du sous-système d’E/S. Avant d’exécuter ces tests, assurez-vous que la surveillance correspondante du système d’exploitation et du niveau de stockage est configurée pour capturer les mesures de performances des E/S en vue d’une analyse ultérieure. La méthode suggérée consiste à exécuter l’outil Performance du système fourni avec IRIS. Veuillez noter qu’il s’agit d’une mise à jour d’une version précédente, qui peut être trouvée ici.
Installation
Téléchargez les outils PerfTools.RanRead.xml et PerfTools.RanWrite.xml depuis GitHub ici.
Importez des outils dans l’espace de noms USER.
UTILISATEUR> faire $system. OBJ. Load(« /tmp/PerfTools.RanRead.xml »,"ckf »)
UTILISATEUR> faire $system. OBJ. Load(« /tmp/PerfTools.RanWrite.xml »,"ckf »)
Exécutez la méthode Help pour afficher tous les points d’entrée. Toutes les commandes sont exécutées dans USER.
USER> do ##class(PerfTools.RanRead). Aide()
• do ##class(PerfTools.RanRead). Setup(Répertoire,DatabaseName,SizeGB,LogLevel)
Crée une base de données et un espace de noms portant le même nom. Le niveau logarithmique doit être compris entre 0 et 3, où 0 correspond à « aucun » et 3 à « verbeux ».
• do ##class(PerfTools.RanRead). Exécuter(Répertoire,Processus,Dénombrement,Mode)
Exécutez le test d’E/S en lecture aléatoire. Le mode est 1 (par défaut) pour le temps en secondes, 2 pour les itérations, en référence au paramètre Count précédent
• do ##class(PerfTools.RanRead). Stop()
Termine toutes les tâches en arrière-plan.
• do ##class(PerfTools.RanRead). Reset()
Supprime les statistiques des exécutions précédentes. Ceci est important pour l’exécution entre les tests, sinon les statistiques des exécutions précédentes sont moyennées dans la version actuelle.
• do ##class(PerfTools.RanRead). Purger(Répertoire)
Supprime l’espace de noms et la base de données du même nom.
• do ##class(PerfTools.RanRead). Export(Répertoire)
Exporte un résumé de tous les tests de lecture aléatoire dans un fichier texte délimité par des virgules.
USER> do ##class(PerfTools.RanWrite). Aide()
• do ##class(PerfTools.RanWrite). Setup(Répertoire,NomBase de données)
Crée une base de données et un espace de noms portant le même nom.
• do ##class(PerfTools.RanWrite). Run(Répertoire,NumProcs,RunTime,HangTime,HangVariationPct,Longueur du nom global,Profondeur globale du nœud,Longueur globale du sous-nœud)
Exécutez le test d’E/S en écriture aléatoire. Tous les paramètres autres que le répertoire ont des valeurs par défaut.
• do ##class(PerfTools.RanWrite). Stop()
Termine toutes les tâches en arrière-plan.
• do ##class(PerfTools.RanWrite). Reset()
Supprime les statistiques des exécutions précédentes.
• do ##class(PerfTools.RanWrite). Purger(Répertoire)
Supprime l’espace de noms et la base de données du même nom.
• do ##class(PerfTools.RanWrite). Export(Directory)
Exporte un résumé de tout l’historique des tests d’écriture aléatoire dans un fichier texte délimité par des virgules.
Coup monté
Créez une base de données vide (pré-développée) appelée RAN au moins deux fois la taille de la mémoire de l’hôte physique à tester. Assurez-vous que la taille du cache du contrôleur de stockage de la base de données vide est au moins quatre fois supérieure à celle du contrôleur de stockage. La base de données doit être plus grande que la mémoire pour garantir que les lectures ne sont pas mises en cache dans le cache du système de fichiers. Vous pouvez créer manuellement ou utiliser la méthode suivante pour créer automatiquement un espace de noms et une base de données.
USER> do ##class(PerfTools.RanRead). Configuration(« /ISC/tests/TMP »,"RAN »,200,1)
Répertoire créé /ISC/tests/TMP/
Création d’une base de données de 200 Go dans /ISC/tests/TMP/
Base de données créée dans /ISC/tests/TMP/
Remarque : On peut utiliser la même base de données pour RanRead et RanWrite, ou utiliser des bases séparées si l’intention de tester plusieurs disques à la fois ou à des fins spécifiques. Le code RanRead permet de spécifier la taille de la base de données, mais pas le code RanWrite, il est donc probablement préférable d’utiliser la commande RanRead Setup pour créer des bases de données prédimensionnées souhaitées, même si l’on utilisera la base de données avec RanWrite.
Méthodologie
Commencez avec un petit nombre de processus et des temps d’exécution de 30 à 60 secondes. Ensuite, augmentez le nombre de processus, par exemple commencez à 10 tâches et augmentez de 10, 20, 40, etc. Continuez à exécuter les tests individuels jusqu’à ce que le temps de réponse soit constamment supérieur à 10 ms ou que les IOPS calculées n’augmentent plus de manière linéaire.
L’outil utilise la commande ObjectScript VIEW qui lit les blocs de base de données en mémoire , donc si vous n’obtenez pas les résultats attendus, tous les blocs de base de données sont peut-être déjà en mémoire.
À titre indicatif, les temps de réponse suivants pour les lectures aléatoires de base de données de 8 Ko et 64 Ko (non mises en cache) sont généralement acceptables pour les baies entièrement flash :
• Moyenne do ##class(PerfTools.RanWrite). Exécuter(« /ISC/tests/TMP »,1,60,.001)
Processus RanWrite 11742 créant 1 processus de travail en arrière-plan.
Préparé RanWriteJob 12100 pour parent 11742
Démarrer 1 processus pour le numéro de tâche RanWrite 11742 maintenant!
Pour terminer l’exécution : faites ##class(PerfTools.RanWrite). Stop()
En attente de finir..................
Travaux d’écriture aléatoire en arrière-plan terminés pour le parent 11742 Les processus 1 de la tâche RanWrite 11742
(60 secondes) avaient un temps de réponse moyen = 0,912 ms
IOPS calculé pour la tâche RanWrite 11742 = 1096
Les autres paramètres de RanWrite peuvent généralement être laissés à leurs valeurs par défaut en dehors de circonstances inhabituelles. Ces paramètres sont les suivants : - HangVariationPct : variance sur le paramètre hangtime, utilisée pour imiter l’incertitude ; c’est un pourcentage du paramètre précédent
- Longueur globale du nom : RanWrite choisit aléatoirement un nom global, et c’est la longueur de ce nom.
Par exemple, s’il est défini sur 6, le Global peut ressembler à Xr6opg-
Profondeur du nœud global et Longueur du sous-nœud global : le Global supérieur n’est pas celui qui est rempli. Ce qui est réellement rempli, ce sont des sous-nœuds, donc définir ces valeurs sur 2 et 4 donnerait une commande comme « set ^Xr6opg(« drb7 »,"xt8v ») = [value] ». Le but de ces deux paramètres et de la longueur du nom global est de s’assurer que le même global n’est pas défini encore et encore, ce qui entraînerait un minimum d’événements d’E/S
Pour exécuter RanRead et RanWrite ensemble, au lieu de « do », utilisez la commande « job » pour les deux afin de les exécuter en arrière-plan.
Résultats
Pour obtenir les résultats simples pour chaque exécution enregistrés dans USER dans la table SQL PerfTools.RanRead et PerfTools.RanWrite, utilisez la commande Export pour chaque outil comme suit.
Pour exporter le jeu de résultats dans un fichier texte délimité par des virgules (csv), exécutez la commande suivante :
USER> do ##class(PerfTools.RanRead). Exporter(« /ISC/tests/TMP/ « )
Exportation du résumé de toutes les statistiques de lecture aléatoire vers /usr/iris/db/zranread/PerfToolsRanRead_20221023-1408.txt
Terminé.
Analyse
Il est recommandé d’utiliser l’outil SystemPerformance intégré pour acquérir une véritable compréhension du système analysé. Les commandes de SystemPerformance doivent être exécutées dans l’espace de noms %SYS. Pour passer à cela, utilisez la commande ZN:
UTILISATEUR> ZN « %SYS »
Pour trouver des détails sur les goulots d’étranglement dans un système, ou si l’on a besoin de plus de détails sur la façon dont il fonctionne à ses IOPS cibles, il faut créer un profil SystemPerformance avec une acquisition de données à cadence élevée :
%SYS> set rc=$$addprofile^SystemPerformance(« 5minhighdef »,"Un échantillonnage d’exécution de 5 minutes toutes les secondes »,1 300)
Ensuite, exécutez ce profil (à partir de %SYS) et revenez immédiatement à USER et démarrez RanRead et/ou RanWrite en utilisant « job » plutôt que « do »:
%SYS>set runid=$$run^SystemPerformance(« 5minhighdef »)
%SYS> ZN « UTILISATEUR »
USER> job ##class(PerfTools.RanRead). Exécuter(« /ISC/tests/TMP »,5,60)
USER> job ##class(PerfTools.RanWrite). Exécuter(« /ISC/tests/TMP »,1,60,.001)
On peut alors attendre la fin du travail SystemPerformance et analyser le fichier html résultant à l’aide d’outils tels que yaspe.
Nettoyer
Une fois l’exécution terminée des tests, supprimez l’historique en exécutant :
%SYS> do ##class(PerfTools. RanRead). Reset()
Vérifiez l’application associée sur InterSystems Open Exchange
Article
Sylvain Guilbaud · Mai 27
Je sais que ceux qui découvrent VS Code, Git, Docker, FHIR et d'autres outils peuvent parfois avoir des difficultés à configurer l'environnement. J'ai donc décidé de rédiger un article qui explique étape par étape l'ensemble du processus de configuration afin de faciliter les premiers pas.
Je vous serais très reconnaissant de bien vouloir laisser un commentaire à la fin de cet article pour me faire savoir si les instructions étaient claires, s'il manquait quelque chose ou si vous avez d'autres suggestions qui pourraient être utiles.
La configuration comprend:
✅ VS Code – Éditeur de code✅ Git – Système de contrôle de version✅ Docker – Lancement d'une instance de la communauté IRIS for Health✅ Extension VS Code REST Client – Pour l'exécution de requêtes API FHIR✅ Python – Pour l'écriture de scripts basés sur FHIR✅ Jupyter Notebooks – Pour les tâches liées à l'IA et au FHIR
Avant de commencer: Vérifiez que vous disposiez des privilèges d'administrateur sur votre système.
Outre la lecture du guide, vous pouvez également suivre les étapes décrites dans les vidéos:
Pour Windows
Pour macOS
Vous trouverez un sondage à la fin de l'article, merci de partager vos progrès. Vos commentaires sont très appréciés.
Alors, c'est parti!
1. Installation de Visual Studio Code (VS Code)
VS Code sera l'éditeur principal pour le développement.
Windows et amp; macOS
Accédez à la page de téléchargement de VS Code: https://code.visualstudio.com/
Téléchargez le programme d'installation pour votre système d'exploitation:
Windows: .exe file
macOS: .dmg file
Exécutez le programme d'installation et suivez les instructions.
(Windows uniquement) : pendant l'installation, cochez la case Add to PATH" (Ajouter au PATH).
Vérifiez l'installation:
ouvrez un terminal (Command Prompt, , PowerShell ou Terminal macOS)
Exécutez:
code --version
Vous devriez voir le numéro de version.
2. Installation de Git
Git est nécessaire pour le contrôle de version, le clonage et la gestion des référentiels de code.
Windows
Téléchargez la dernière version à partir de: https://git-scm.com/downloads
Exécutez le programme d'installation:
Choisissez "Use Git from the Windows Command Prompt" (Utiliser Git à partir de l'invite de commande Windows).
Conservez les paramètres par défaut et terminez l'installation.
Vérifiez l'installation:
git --version
macOS
Ouvrez le terminal et exécutez:
git --version
Si Git n'est pas installé, macOS vous demandera d'installer les outils de ligne de commande Suivez les instructions.
3. Installation de Docker
Docker est indispensable pour exécuter InterSystems IRIS for Health Community.
Windows
1. Téléchargez Docker Desktop à partir de: https://www.docker.com/products/docker-desktop2. Exécutez le programme d'installation et suivez les instructions.3. Redémarrez votre ordinateur après l'installation.4. Activez WSL 2 Backend (si cela vous est demandé).5. Verifiez l'installation
À remarquer: L'installation de Docker nécessite des privilèges d'administrateur sur votre machine et au moins un redémarrage.
macOS
1. Téléchargez Docker Desktop pour Mac à partir de: https://www.docker.com/products/docker-desktop2. Installez-le en glissant Docker.app dans le dossier Applications.3. Ouvrez Docker à partir du menu Applications.
Pour vous assurer que le moteur Docker Desktop fonctionne sous Windows ou macOS, procédez comme suit:
Démarrez Docker Desktop
Windows: Ouvrez Docker Desktop à partir du menu Start. L'icône Docker en forme de baleine devrait apparaître dans votre barre d'état système.
Mac: Lancez Docker Desktop à partir du dossier Applications. Une fois l'application lancée, l'icône Docker en forme de baleine apparaîtra dans la barre de menu.
Attendez l'initialisation
Une fois que vous avez lancé Docker Desktop, le moteur peut prendre un certain temps à démarrer. Recherchez un message d'état indiquant que Docker est "running" (en cours d'exécution) ou "started" (démarré).
Vérifiez via le terminal/Command Prompt:
Ouvrez le terminal (ou Command Prompt/PowerShell pour Windows) et exécutez:
docker --version
ou
docker info
Dépannage
Si le moteur ne fonctionne pas, essayez de redémarrer Docker Desktop ou vérifiez s'il y a des messages d'erreur dans l'interface utilisateur de Docker Desktop. Assurez-vous également que votre système répond aux exigences de Docker Desktop. Vous pouvez voir des messages d'erreur confus faisant référence à des pipes si vous essayez de créer une image Docker sans que Docker Desktop soit en cours d'exécution.
4. Création de l'image IRIS for Health et son exécution à l'aide de Docker
Avant de pouvoir démarrer un conteneur Docker exécutant IRIS for Health Community (qui comprend notre serveur FHIR), nous devons le créer.
Clonez le référentiel FHIR dans un répertoire approprié de votre système de fichiers. Ouvrez un terminal dans VS Code et clonez ce référentiel à l'aide de la commande suivante:
git clone https://github.com/pjamiesointersystems/Dockerfhir.git
Accédez à ce répertoire et ouvrez le dossier dans VS Code. Suivez les instructions du fichier readme pour créer et exécuter le conteneur. Une étape essentielle consiste à vous assurer que le référentiel de base est disponible dans votre magasin Docker. Vous pouvez le faire à l'aide de la commande dans le terminal VS Code:
docker pull containers.intersystems.com/intersystems/irishealth-community:latest-em
Vous devriez recevoir une confirmation après quelques minutes.
Accédez au répertoire dans VS Code où se trouve le fichier docker-compose.yaml, puis exécutez la commande suivante:
docker-compose build
Cela lancera le processus de compilation, qui peut prendre jusqu'à 10 minutes, au cours desquelles un référentiel FHIR complet sera créé et chargé avec un échantillon de patients.
Une fois le processus de compilation terminé, lancez le conteneur à l'aide de la commande suivante:
docker-compose up -d
suivi par
docker ps
Vous devriez voir un conteneur nommé **iris-fhir** en cours d'exécution. Si le conteneur ne démarre pas, vérifiez les journaux:
docker logs iris-fhir
5. Installation de l'extension VS Code REST Client
Cette extension vous permet d'envoyer des requêtes API FHIR depuis VS Code.
Ouvrez VS Code.
Accédez aux extensions (Ctrl + Shift + X or Cmd + Shift + X on macOS).
Recherchez "REST Client". Il existe plusieurs clients REST, veuillez installer celui-ci:
Clickez le bouton "Install".
6. Installation de Python
Python est indispensable pour les tâches de programmation liées à FHIR.
Windows
1. Télécharger Python à partir de: https://www.python.org/downloads/2. Exécutez le programme d'installation et cochez la case "Add to PATH" (Ajouter au chemin). Vous aurez besoin d'informations d'identification administratives pour apporter des modifications au chemin d'accès3. Terminez l'installation.4. Verifiez l'installation:
python --version
macOS
Ouvrez le Terminal et installez Python via Homebrew:
Brew install python
Si vous n'avez pas d'Homebrew, installez-le d'abord:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
Verifiez l'installation:
python3 --version
7. Installation des blocs-notes Jupyter
Les notebooks Jupyter sont utilisés pour l'IA et le FHIR, ainsi que pour les tâches FHIR SQL.
Windows & macOS
Ouvrez le terminal (Command Prompt, PowerShell, ou macOS Terminal).
Installez Jupyter à l'aide de pip:
pip install jupyter
jupyter --version
Exécutez le bloc-note Jupyter:
jupyter notebook
Jupyter s'ouvrira alors dans votre navigateur web.
8. Validation
Exécutez votre conteneur en accédant à votre fichier Docker Compose dans le shell. Exécutez la commande
docker compose up -d
docker ps
Accédez au Portail de gestion d'IRIS:
Ouvrez votre navigateur et accédez à: http://localhost:8080/csp/sys/UtilHome.csp
Informations d'identification par défaut:
Nom d'utilisateur: _SYSTEMMot de passe: ISCDEMO
Accédez à l'API FHIR
Ouvrez votre navigateur et accédez à: http://localhost:8080/csp/healthshare/demo/fhir/r4/metadata
Dernières vérifications
Exécutez les commandes suivantes pour vérifier toutes les installations:
code --version # VS Code
git --version # Git
docker --version # Docker
python --version # Python
jupyter --version # Jupyter
Si tout fonctionne, vous avez installé correctement tous les logiciels ci-dessus.
Dépannage
Problème
Solution
"Command not found" (Commande introuvable) pour n'importe quel outil
Vérifiez qu'il a bien été ajouté au PATH (chemin) (réinstallez-le si nécessaire).
Docker ne fonctionne pas sous Windows
Redémarrez Docker Desktop et vérifiez que WSL 2 backend est activé.
Le conteneur IRIS ne démarre pas
Exécutez docker logs iris-fhir pour vérifier les erreurs.
Impossible d'accéder à l'API FHIR
Vérifiez que le conteneur est en cours d'exécution (docker ps).
Merci de votre aide. J'attends vos commentaires avec impatience!
Article
Lorenzo Scalese · Juin 10
Introduction
Les performances des bases de données sont devenues essentielles à la réussite des environnements applicatifs modernes. Il est donc indispensable d'identifier et d'optimiser les requêtes SQL les plus exigeantes en ressources afin de garantir une expérience utilisateur fluide et la stabilité des applications.
Cet article présente une approche rapide pour analyser les statistiques d'exécution des requêtes SQL sur une instance InterSystems IRIS afin d'identifier les domaines à optimiser au sein d'une macro-application.
Au lieu de nous concentrer sur la surveillance en temps réel, nous allons mettre en place un système qui collecte et analyse les statistiques précalculées par IRIS une fois par heure. Cette approche, bien qu'elle ne permette pas de surveillance instantanée, offre un excellent compromis entre la richesse des données disponibles et la simplicité de mise en œuvre.
Nous utiliserons Grafana pour la visualisation et l'analyse des données, InfluxDB pour le stockage des séries chronologiques et Telegraf pour la collecte des métriques. Ces outils, reconnus pour leur puissance et leur flexibilité, nous permettront d'obtenir un aperçu clair et exploitable.
Plus précisément, nous détaillerons la configuration de Telegraf pour récupérer les statistiques. Nous configurerons également l'intégration avec InfluxDB pour le stockage et l'analyse des données, et créerons des tableaux de bord personnalisés dans Grafana. Cela nous aidera à identifier rapidement les requêtes nécessitant une attention particulière.
Pour faciliter l'orchestration et le déploiement de ces différents composants, nous utiliserons Docker.
Conditions préalables
Avant de commencer, assurez-vous d'avoir les éléments suivant:
Git: Git est nécessaire pour cloner le référentiel du projet contenant les fichiers de configuration et les scripts.
Docker ou Docker Desktop: Docker peut être utilisé pour conteneuriser les applications InfluxDB, Telegraf et Grafana, ce qui facilite leur déploiement et leur gestion.
Instance InterSystems IRIS:Au moins la version 2022.1, idéalement 2023.1 ou supérieure, avec le package sql-stats-api installé. Ce package est essentiel pour exposer les statistiques SQL IRIS et permettre à Telegraf de les collecter. [Lien vers OpenExchange]
Bien que nos fichiers docker-compose incluent une instance IRIS, celle-ci ne contiendra aucune donnée statistique SQL, car elle vient d'être créée et démarrée. Elle ne constituera donc pas un choix pratique pour tester le système. C'est pourquoi nous vous recommandons vivement de disposer d'une autre instance IRIS "active" (celle qui contient l'historique des requêtes SQL) afin de pouvoir visualiser des données réelles et tester l'outil d'analyse.
À propos des statistiques
IRIS collecte des statistiques d'exécution des requêtes SQL à une granularité horaire et quotidienne. Les statistiques horaires identifient les variations de performances tout au long de la journée, tandis que les statistiques quotidiennes fournissent une vue d'ensemble de l'activité de la base de données.
Vous trouverez ci-dessous les données que nous collectons pour chaque requête SQL:
Nombre d'exécutions: indique le nombre de fois où la requête a été exécutée.
Durée totale d'exécution: mesure la durée totale d'exécution de la requête.
Variance des temps d'exécution: utilisée pour identifier les variations de performances et les problèmes ponctuels.
Nombre total de lignes renvoyées (RowCount): disponible pour IRIS 2023.1 et versions ultérieures, cette métrique indique le nombre total de lignes renvoyées par la requête. Elle peut vous aider à identifier les requêtes exigeantes en ressources.
Nombre total de commandes exécutées: également disponible pour IRIS 2023.1 et versions ultérieures, cette métrique facilite une analyse plus détaillée de l'activité de la base de données et identifie les requêtes qui pourraient être optimisées en réduisant le nombre d'opérations.
Ces informations sont accessibles via les tables suivantes:
INFORMATION_SCHEMA.STATEMENT_DAILY_STATS
INFORMATION_SCHEMA.STATEMENT_HOURLY_STATS
Ces tables sont disponibles depuis IRIS 2022.1. Vous trouverez ci-dessous un exemple de requête SQL permettant de récupérer des statistiques:
SELECT ds.*
FROM INFORMATION_SCHEMA.STATEMENT_DAILY_STATS ds
INNER JOIN INFORMATION_SCHEMA.STATEMENTS st On ds.Statement = st.Hash
SELECT DATEADD('hh',"Hour",$PIECE(hs."Day",'||',2)) As DateTime, hs.*
FROM INFORMATION_SCHEMA.STATEMENT_HOURLY_STATS hs
INNER JOIN INFORMATION_SCHEMA.STATEMENTS st On $PIECE(hs."Day",'||',1) = st.Hash
Pour les versions plus anciennes que IRIS 2022.1, je recommande vivement l'article de David Loveluck, qui explique comment récupérer des statistiques similaires.
Architecture
Le projet repose sur l'interaction de quatre composants clés : IRIS, Grafana, InfluxDB et Telegraf. Le diagramme ci-dessous illustre l'architecture globale du système et le flux de données entre les différents composants:
InterSystems IRIS: il s'agit de l'instance que nous utiliserons pour récupérer les statistiques.
Package sql-stats-api: ce package ObjectScript expose les données statistiques IRIS via l'API REST. Il offre deux formats de sortie : JSON pour une utilisation générale et Line Protocol, un format optimisé pour l'ingestion rapide de données de séries chronologiques dans InfluxDB.
Telegraf: il s'agit d'un agent de collecte de métriques qui fournit le lien entre IRIS et InfluxDB. Dans ce projet, nous utiliserons deux instances de Telegraf:
un agent interroge périodiquement l'API REST IRIS pour récupérer les statistiques SQL en temps réel.
Un autre agent fonctionne en mode "scan de répertoire". Il surveille un répertoire contenant les fichiers stockés et les transmet à InfluxDB, ce qui permet d'intégrer les données inaccessibles via l'API REST.
InfluxDB: cette base de données de séries chronologiques stocke et gère les statistiques SQL collectées par Telegraf, car son architecture est optimisée pour ce type de données. InfluxDB offre également une intégration native avec Grafana, ce qui facilite la visualisation et l'analyse des données. Nous avons préféré InfluxDB à Prometheus, car ce dernier est davantage axé sur la surveillance en temps réel et n'est pas bien adapté au stockage de données agrégées, telles que les sommes ou les moyennes horaire ou journalière, qui sont essentielles pour notre analyse.
Grafana: il s'agit d'un outil de visualisation qui permet de créer des tableaux de bord personnalisés et interactifs pour analyser les performances SQL. Il récupère les données d'InfluxDB et offre une variété de graphiques et de widgets pour visualiser les statistiques de manière claire et exploitable.
Installation
Commencez par cloner le référentiel:
git clone https://github.com/lscalese/iris-sql-dashboard.git
cd irisiris-sql-dashboard
Configuration de l'environnement
Ce projet utilise Docker pour orchestrer Grafana, InfluxDB, Telegraf et IRIS. Pour des raisons de sécurité, les informations sensibles telles que les clés API et les mots de passe sont stockées dans un fichier .env.
Créez le fichier .env en utilisant l'exemple fourni ci-dessous:
cp .env.example .env
Éditez le fichier .env pour configurer les variables:
Configuration des variables
TZ: fuseau horaire. Il est recommandé de modifier cette variable en fonction de votre fuseau horaire afin de garantir l'exactitude de l'horodatage des données.
DOCKER_INFLUXDB_INIT_PASSWORD: mot de passe administrateur permettant d'accéder à InfluxDB.
IRIS_USER: il s'agit d'un utilisateur IRIS de l'instance Docker IRIS (_system par défaut).
IRIS_PASSWORD : Il s'agit du mot de passe de l'instance IRIS Docker (SYS par défaut).
Les clés API permettent les connexions suivantes:
GRAFANA_INFLUX_API_KEY : Grafana <-> InfluxDB.
TELEGRAF_INFLUX_API_KEY : Telegraf <-> InfluxDB.
Génération de clés API
Pour des raisons de sécurité, InfluxDB nécessite des clés API pour l'authentification et l'autorisation. Ces clés sont utilisées pour identifier et autoriser divers composants (Telegraf, Grafana) à accéder à Influx DB.
Le script init-influxdb.sh, inclus dans le référentiel, facilite la génération de ces clés. Il sera exécuté automatiquement lors du premier démarrage du conteneur infxludb2:
docker compose up -d influxdb2
Après quelques secondes, le fichier .env sera mis à jour avec vos clés API générées.
Remarque: cette étape ne doit être effectuée que lors du premier démarrage du conteneur.
Vérifiez si vous avez accès à l'interface d'administration InfluxDB via l'URL http://localhost:8086/
Connectez-vous avec le nom d'utilisateur "admin" et le mot de passe spécifiés dans la variable d'environnement "DOCKER_INFLUXDB_INIT_PASSWORD" dans le fichier ".env". Lorsque vous naviguez dans "Load Data >> Buckets”, vous devriez découvrir un bucket "IRIS_SQL_STATS" préconfiguré.
En parcourant "Load Data >> API Tokens", vous devriez trouver nos deux clés API : "Grafana_IRIS_SQL_STATS" et "Telegraf_IRIS_SQL_STATS":
L'environnement est prêt maintenant, et nous pouvons passer à l'étape suivante!
Démarrage
L'environnement étant configuré et les clés API générées, vous pouvez enfin lancer l'ensemble de conteneurs. Pour ce faire, exécutez la commande suivante dans le répertoire racine du projet:
docker compose up -d
Cette commande lancera en arrière-plan tous les services définis dans le fichier docker-compose.yml : InfluxDB, Telegraf, Grafana et l'instance IRIS.
Tableau de bord Grafana
Grafana est désormais disponible à l'adresse http://localhost:3000.
Connexion à Grafana
Ouvrez votre navigateur Web et rendez-vous à l'adresse http://localhost:3000. Le nom d'utilisateur et le mot de passe par défaut sont admin/admin. Cependant, vous serez invité à modifier le mot de passe lors de votre première connexion.
Vérification de la source de données InfluxDB
La source de données InfluxDB est préconfigurée dans Grafana. Il vous suffit de vérifier son bon fonctionnement.
Accédez à “Connections > Data sources (sources de données)”.
Vous devriez voir une source de données nommée “influxdb”.Cliquez dessus pour la modifier.
Cliquez ensuite sur “Save & Test”. Le message “Datasource is working. 1 bucket found” (La source de données fonctionne. 1 bucket trouvé) devrait maintenant s'afficher à l'écran.
Exploration des tableaux de bord
À ce stade, vous avez vérifié que la communication entre Grafana et InfluxDB est établie, ce qui signifie que vous pouvez explorer les tableaux de bord prédéfinis.
Passez à “Dashboards” (tableaux de bord).
Vous trouverez deux tableaux de bord prédéfinis:
InfluxDB - SQL Stats: ce tableau de bord affiche des statistiques générales sur l'exécution des requêtes SQL, par exemple le nombre d'exécutions, le temps total d'exécution et la variance du temps d'exécution.
InfluxDB - SQL Stats Details: ce tableau de bord fournit des informations plus détaillées sur chaque requête SQL, par exemple le nombre total de lignes renvoyées ou de commandes exécutées.
Pourquoi les tableaux de bord sont vides
Si vous ouvrez les tableaux de bord, vous verrez qu'ils sont vides. Cela s'explique par le fait que notre agent Telegraf est actuellement connecté à l'instance IRIS fournie dans le référentiel Docker, dont les tables ne contiennent aucune donnée statistique. Les statistiques SQL ne sont collectées que si l'instance IRIS est active et conserve un historique des requêtes SQL.
Dans la section suivante, nous allons voir comment injecter des données dans l'instance IRIS afin d'afficher les statistiques dans Grafana.
Telegraf
Le système de surveillance utilise deux agents Telegraf ayant des rôles spécifiques:
telegraf-iris.conf:cet agent collecte des données en temps réel à partir d'une instance IRIS active. Il interroge l'API REST IRIS pour récupérer des statistiques SQL afin de les envoyer à InfluxDB.
telegraf-directory-scan.conf: cet agent intègre les données historiques stockées dans des fichiers. Il surveille le répertoire ./telegraf/in/, lit les fichiers contenant des statistiques SQL et les envoie à InfluxDB.
Pour collecter des données en temps réel, il faut connecter Telegraf à une instance IRIS active sur laquelle le package sql-stats-api est installé. Ce package expose les statistiques SQL via une API REST, ce qui permet à Telegraf d'y accéder.
Configuration de telegraf-iris.conf
Pour connecter Telegraf à votre instance IRIS, vous devez modifier le fichier ./telegraf/config/telegraf-iris.conf. Vous trouverez ci-dessous un exemple de configuration:
[[inputs.http]]
## Une ou plusieurs URL à partir desquelles lire les métriques formatées
urls = [
"http://iris:52773/csp/sqlstats/api/daily",
"http://iris:52773/csp/sqlstats/api/hourly"
]
## Méthode HTTP
method = "GET"
## En-têtes HTTP facultatifs
headers = {"Accept" = "text/plain"}
## Informations d'identification pour l'authentification HTTP de base (facultatif)
username = "${IRIS_USER}"
password = "${IRIS_PASSWORD}"
data_format = "influx"
Assurez-vous que${IRIS_USER} et ${IRIS_PASSWORD} sont correctement définis dans votre dossier .env file.Remarque: Vous pouvez copier le fichier et modifier les paramètres pour connecter Telegraf à plusieurs instances IRIS.
Redémarrage de Telegraf:
Après avoir modifié le fichier de configuration, il est nécessaire de redémarrer le conteneur Telegraf pour que les modifications prennent effet:
docker compose up -d telegraf --force-recreate
Récupération des données historiques
Pour récupérer les statistiques SQL historiques, utilisez la méthode ObjectScript CreateInfluxFile sur votre instance IRIS:
; Adaptez le chemin à vos besoins
Set sc = ##class(dc.sqlstats.services.SQLStats).CreateInfluxFile("/home/irisowner/dev/influxdb-lines.txt",,1)
Ce script enregistre l'historique des statistiques SQL dans des fichiers texte dont la longueur maximale est de 10 000 lignes par fichier. Vous pouvez ensuite placer ces fichiers dans le répertoire ./telegraf/in/ afin de les traiter et de les injecter dans InfluxDB.
Vérification de l'injection des données
Vous pouvez vérifier que les données ont été correctement injectées dans InfluxDB à l'aide de l'interface Web. Accédez à "Data Explorer" (Explorateur de données) et vérifiez:
Visualisation des données dans Grafana
Une fois les données injectées, vous pouvez les afficher dans vos tableaux de bord Grafana fournis.
Nous sommes arrivés à la fin de notre article. J'espère qu'il vous a été utile et qu'il vous avez appris à configurer facilement un système de surveillance et d'analyse des statistiques SQL sur vos instances IRIS.
Comme vous l'avez peut-être constaté, cet article a mis l'accent sur les aspects pratiques de la configuration et de l'utilisation de divers outils. Nous n'avons pas étudié en détail le fonctionnement interne d'InfluxDB, du format Line Protocol ou du langage Flux Query, ni examiné la multitude de plugins disponibles pour Telegraf.
Ces sujets, aussi fascinants soient-ils, nécessiteraient un article beaucoup plus long. Je vous encourage vivement à consulter la documentation officielle d'InfluxDB Get started with InfluxDB (Débuter avec InfluxDB) et Telegraf Plugin Directory (Répertoire des plugins) pour approfondir vos connaissances et découvrir toutes les possibilités offertes par ces outils.
N'hésitez pas à partager vos expériences dans les commentaires.
Merci d'avoir lu cet article, et à bientôt!
Article
Iryna Mykhailova · Juin 17
Lorsque nous créons un référentiel FHIR dans IRIS, nous avons un point de terminaison pour accéder à l'information, créer de nouvelles ressources, etc. Mais il y a certaines ressources dans FHIR que nous n'aurons probablement pas dans notre référentiel, par exemple, la ressource Binary (cette ressource renvoie des documents, comme des PDF par exemple).
J'ai créé un exemple dans lequel, quand une ressource est demandée via "Binary", l'endpoint FHIR renvoie une réponse, comme si elle existait dans le référentiel.
Tout d'abord, nous avons besoin du Namespace (espace de noms) et du FHIR endpoint (point d'accès FHIR). Ensuite, nous devons configurer une production d'interopérabilité - Interoperability production - qui sera connectée à l'endpoint FHIR. Cette production devrait contenir les éléments suivants:
Business Operation:
HS.Util.Trace.Operations (Ceci est évidemment facultatif, mais peut s'avérer très utile)
HS.FHIRServer.Interop.Operation, avec la propriété TraceOperations configurée à *FULL*
Business Service:
HS.FHIRServer.Interop.Service, avec la propriété TraceOperations configurée à *FULL* et Target Config Name configurée à HS.FHIRServer.Interop.Operation name
La production se présente comme suit:
Après avoir créé cette production, nous devons la connecter avec l'endpoint FHIR. Il faut donc éditer l'endpoint FHIR et configurer le paramètre Service Config Name avec le nom du Business Service:
Maintenant, si nous commençons à envoyer des requêtes au référentiel FHIR, nous verrons toutes les traces dans l'Afficheur de messages:
Nous pouvons maintenant établir un Business Process pour contrôler ce qu'il convient de faire avec des chemins d'accès spécifiques.
Dans cet exemple, nous avons un Business Process qui reçoit toutes les demandes (maintenant le Business Service est connecté à ce Business Process, au lieu du Business Operation) et 2 nouvelles Business Operations qui effectuent d'autres actions dont nous parlerons plus tard:
Jetons un coup d'œil au Business Process appelé FHIRRouter:
En regardant, nous verrons que, si RequestPath contient "Binary/", alors nous ferons quelque chose avec cette requête: générer notre réponse Binary personnalisée. Sinon, nous enverrons la demande au référentiel FHIR directement.
Jetons un coup d'œil à la séquence appelée "Generate Binary":
Tout d'abord, nous créons une nouvelle instance de HS.FHIRServer.Interop.Response. Nous obtenons document ID à partir du chemin d'accès: Request Path. Comment? Chaque fois que quelqu'un veut une ressource binaire, elle doit être demandée avec l'identifiant du document dans le chemin de l'URL, quelque chose comme ceci: ..../fhir/r4/Binary/XXXXX. Ainsi, pour extraire l'identifiant du document du chemin d'accès, nous utilisons l'expression suivante:
$Replace(request.Request.RequestPath,"Binary/","")
(Ce n'est pas vraiment raffiné, mais cela fonctionne).
Si nous avons un identifiant de document, nous faisons appel à un Business Operation appelée Find pour rechercher le nom de fichier associé à cet identifiant de document:
En fait, cette recherche deBusiness Operation Find renvoie toujours le même nom de fichier:
L'exemple ci-dessus montre ce que nous pouvons faire.
Si nous avons un nom de fichier, alors, nous appelons un autre Business Operation appelé File pour obtenir le contenu de ce fichier, encodé en base64:
And finally, we can return 2 kind of responses:
Si nous n'avons pas de contenu de fichier (puisque nous n 'avons pas d 'identifiant de document ou que nous ne trouvons pas le nom de fichier ou le contenu associé), nous renvoyons une réponse 404, avec cette réponse personnalisée:
set json = {
"resourceType": "OperationOutcome",
"issue": [
{
"severity": "error",
"code": "not-found",
"diagnostics": "<HSFHIRErr>ResourceNotFound",
"details": {
"text": "No resource with type 'Binary'"
}
}
]
}
set json.issue.%Get(0).details.text = json.issue.%Get(0).details.text_" and id '"_context.docId_"'"
set qs = ##class(HS.SDA3.QuickStream).%New()
do qs.Write(json.%ToJSON())
set response.QuickStreamId = qs.%Id()
set response.ContentType = "application/fhir+json"
set response.CharSet = "UTF-8"
Si nous avons le contenu du fichier, nous renvoyons une réponse 200 avec cette réponse personnalisée:
set json = {
"resourceType": "Binary",
"id": "",
"contentType": "application/pdf",
"securityContext": {
"reference": "DocumentReference/"
},
"data": ""
}
set json.id = context.docId
set json.securityContext.reference = json.securityContext.reference_json.id
set json.data = context.content.Read(context.content.Size)
set qs = ##class(HS.SDA3.QuickStream).%New()
do qs.Write(json.%ToJSON())
set response.QuickStreamId = qs.%Id()
set response.ContentType = "application/fhir+json"
set response.CharSet = "UTF-8"
La clé ici est de créer un HS.SDA3.QuickStream, qui contient l'objet JSON. Et d'ajouter ce QuickStream à la réponse.
Et maintenant, si nous testons notre point d'accès, si nous demandons un document de type Binary, nous verrons la réponse:
Et si nous requérons un document de type Binary qui n'existe pas (vous pouvez le tester sans spécifier l'identifiant du document), nous obtiendrons la réponse 404:
En résumé, en connectant notre endpoint FHIR avec l'interopérabilité, nous pouvons faire tout ce que nous voulons, avec toutes les capacités d'InterSystems IRIS.
Article
Lorenzo Scalese · Mai 12, 2023
Selon le dictionnaire de Cambridge, tokéniser des données signifie "remplacer un élément de données privé par un jeton (= un élément de données différent qui représente le premier), afin d'empêcher que des renseignements privés soient vus par quelqu'un qui n'est pas autorisé à le faire" (https://dictionary.cambridge.org/pt/dicionario/ingles/tokenize). Aujourd'hui, plusieurs entreprises, en particulier dans les secteurs de la finance et de la santé, tokenisent leurs données, ce qui constitue une stratégie importante pour répondre aux exigences en matière de cybersécurité et de confidentialité des données ( RGPD, CCPA, HIPAA et LGPD). Mais pourquoi ne pas utiliser le chiffrement ? Le processus de tokenisation pour protéger les données sensibles est plus couramment utilisé que le chiffrement des données pour les raisons suivantes :
1. Amélioration des performances : le cryptage et le décryptage des données à la volée dans le cadre d'un traitement opérationnel intensif entraînent des performances médiocres et nécessitent une plus grande puissance du processeur.
2. Tests : il est possible de tokeniser une base de données de production et de la copier dans une base de données de test et de conserver les données de test adaptées à des tests unitaires et fonctionnels plus réels.
3. Meilleure sécurité : si un pirate informatique craque ou obtient la clé secrète, toutes les données cryptées seront disponibles, car le cryptage est un processus réversible. Le processus de tokenisation n'est pas réversible. Si vous devez récupérer les données d'origine à partir des données tokenisées, vous devez maintenir une base de données sécurisée et séparée pour relier les données d'origine et les données tokenisées.
## Architecture de tokenisation
L'architecture de tokenisation nécessite deux bases de données : l'App DB pour stocker les données tokenisées et d'autres données de l'entreprise et une base de données de jetons pour stocker les valeurs d'origine et tokenisées, de sorte que lorsque vous en avez besoin, votre application peut obtenir les valeurs d'origine à montrer à l'utilisateur. Il existe également une API REST Tonenizator qui permet de tokeniser les données sensibles, de les stocker dans la base de données de tokens et de renvoyer un ticket. L'application métier stocke le ticket, les données symbolisées et les autres données dans la base de données de l'application. Consultez le diagramme d'architecture :
## Application Tokenizator
Découvrez comment cela fonctionne dans l'application Tokenization : https://openexchange.intersystems.com/package/Tokenizator.
Cette application est une API REST qui permet de créer des jetons :
* Toute valeur est remplacée par les **étoiles**. Exemple : carte de crédit 4450 3456 1212 0050 par 4450 *\*\*\* \*\*** 0050.
* N'importe quelle **adresse IP réelle est remplacée par une fausse valeur**. Exemple : 192.168.0.1 par 168.1.1.1.
* Toute donnée **personne** est remplacée par une fausse personne. Exemple : Yuri Gomes avec l'adresse Brasilia, Brésil par Robert Plant avec l'adresse Londres, Royaume-Uni.
* Toute valeur **numéro** est remplacée par une fausse valeur numérique. Exemple : 300,00 par 320,00.
* Toute donnée de **carte de crédit** est remplacée par un faux numéro de carte de crédit. Exemple : 4450 3456 1212 0050 par 4250 2256 4512 5050.
* N'importe quelle valeur est remplacée par une valeur **hash**. Exemple : Architecte système par dfgdgasdrrrdd123.
* Toute valeur est remplacée par une expression **regex**. Exemple : EI-54105-tjfdk par AI-44102-ghdfg en utilisant la règle regex [A-Z]{2}-\d{5}-[a-z]{5}.
Si vous souhaitez une autre option, ouvrez une demande sur le projet github.
Pour tokeniser les valeurs et obtenir les valeurs d'origine par la suite, suivez les étapes suivantes :
1. Ouvrez votre Postman ou consommez cette API à partir de votre application.
2. Créez une demande de tokenisation en utilisant les méthodes STARS, PERSON, NUMBER, CREDITCARD, HASH, IPADDRESS et REGEX pour cet échantillon de données sensibles :
* Méthode : POST
* URL: http://localhost:8080/token/tokenize
* Corps (JSON):
[
{
"tokenType":"STARS",
"originalValueString":"545049405679",
"settings": {
"starsPosition":"1",
"starsQuantity":"4"
}
},
{
"tokenType":"IPADDRESS",
"originalValueString":"192.168.0.1",
"settings": {
"classType":"CLASS_B",
"ipSize":"4"
}
},
{
"tokenType":"PERSON",
"originalValueString":"Yuri Marx Pereira Gomes",
"settings": {
"localeLanguage":"en",
"localeCountry":"US",
"withAddress":"true",
"withEmail":"true"
}
},
{
"tokenType":"NUMBER",
"originalValueNumber":300.0,
"settings": {
"minRange":"100.0",
"maxRange":"400.0"
}
},
{
"tokenType":"CREDITCARD",
"originalValueString":"4892879268763190",
"settings": {
"type":"VISA"
}
},
{
"tokenType":"HASH",
"originalValueString":"Architecte système"
},
{
"tokenType":"REGEX",
"originalValueString":"EI-54105-tjfdk",
"settings": {
"regex":"[A-Z]{2}-\\d{5}-[a-z]{5}"
}
}
]
* Découvrez les résultats. Vous obtenez une valeur tokenizée (tokenizedValueString) à stocker dans votre base de données locale.
3. Copiez le ticket de la réponse (stockez-le dans votre base de données locale avec la valeur tokenisée).
4. Avec le ticket, vous pouvez maintenant obtenir la Valeur d'origine. Créez une demande pour obtenir la valeur d'origine en utilisant le ticket :
* Méthode: GET
* URL: http://localhost:8080/token/query-ticket/TICKET-VALUE-HERE
* Découvrez vos valeurs d'origine
Tous les tokens générés sont stockés dans SQL d'InterSystems IRIS Cloud pour vous permettre d'obtenir vos valeurs d'origine en toute performance et en toute confiance.
Profitez-en !
Article
Guillaume Rongier · Mai 2, 2022
La version 2021.2 de la plate-forme de données InterSystems IRIS Data Platform comprend de nombreuses nouvelles fonctionnalités intéressantes pour le développement rapide, flexible et sécurisé de vos applications critiques. Embedded Python est certainement la vedette (et pour une bonne raison !), mais en SQL, nous avons également fait un grand pas en avant vers un moteur plus adaptatif qui recueille des informations statistiques détaillées sur les données de votre tableau et les exploite pour fournir les meilleurs plans de requête. Dans cette brève série d'articles, nous allons examiner de plus près trois éléments qui sont nouveaux dans 2021.2 et qui travaillent ensemble vers cet objectif, en commençant par Run Time Plan Choice.
Il est difficile de trouver le bon ordre pour en parler (vous ne pouvez pas imaginer le nombre de fois où je les ai remaniés en rédigeant cet article), car ils s'emboîtent si bien les uns dans les autres. Vous pouvez donc les lire dans un ordre aléatoire .
Au sujet du traitement des requêtes IRIS
Lorsque vous soumettez une instruction au moteur IRIS SQL, celui-ci l'analyse dans une forme normalisée, en substituant tous les littéraux (paramètres de la requête), puis examine la structure de votre tableau, les indices et les statistiques sur les valeurs des champs afin de déterminer la stratégie d'exécution la plus efficace pour la requête normalisée. Cela permet au moteur de réutiliser le même plan et le même code généré lorsque vous souhaitez exécuter à nouveau la requête, éventuellement en utilisant des valeurs de paramètres de requête différentes. Par exemple, prenez la requête suivante :
SELECT * FROM Customer WHERE CountryCode = 'US' AND ChannelCode = 'DIRECT'
Cette requête sera normalisée sous une forme analogue à celle-ci :
SELECT * FROM Customer WHERE CountryCode = ? AND ChannelCode = ?
afin que les invocations ultérieures pour différentes combinaisons de pays et de canaux puissent immédiatement récupérer la même classe de requête mise en cache, ce qui permet d'éviter le travail de planification lourd en termes de calcul. Supposons que nous vendions des chaussures de course par l'intermédiaire d'une demi-douzaine de canaux et que nos produits soient vendus dans le monde entier ; en d'autres termes, les données sont réparties uniformément entre les valeurs possibles des champs CountryCode et ChannelCode. Si nous disposons d'un index régulier sur ces deux champs, le plan le plus efficace pour cette requête normalisée commencera par la condition la plus sélective (CountryCode), en utilisant l'indice correspondant pour accéder aux lignes correspondantes de la carte principale, puis vérifiera l'autre condition (ChannelCode) pour chaque ligne de la carte principale.
Valeurs aberrantes
Supposons que nous ne soyons pas un fabricant d'équipements sportifs, mais un vendeur spécialisé dans les moules pour chocolats belges (d'où est-ce que je sors ça ? ). Dans ce cas, supposons que la majorité de mes clients (disons 60 %) se trouvent en Belgique, ce qui signifie que "BE" devient une valeur "aberrante" pour le champ CountryCode, représentant un grand nombre de lignes de mon tableau. Soudain, l'indice sur le code pays a une autre utilité : _si_ le paramètre de requête pour CountryCode que nous obtenons au moment de l'exécution est 'BE', l'utilisation de cet index en premier signifierait que je devrais lire la majorité de ma carte principale, et qu'il serait préférable de commencer par l'index sur ChannelCode. Cependant, si la valeur du paramètre de requête pour CountryCode est une autre valeur, cela rendrait l'indice sur CountryCode beaucoup plus intéressant, car tous les autres pays se partagent les 40% de clients non belges restants.
C'est un exemple où vous voudriez choisir un plan différent au moment de l'exécution ; ou, en reformulant ces mots : **Run Time Plan Choice**. Le RTPC est un mécanisme qui ajoute un petit crochet dans la logique classique de substitution littérale et de recherche de requête en mémoire cache pour repérer les valeurs aberrantes telles que la valeur "BE" pour notre colonne CountryCode. Si vous souhaitez obtenir un aperçu plus détaillé du traitement des requêtes IRIS SQL, veuillez consulter [ce vidéo VS2020](https://learning.intersystems.com/course/view.php?id=1598).
Dans le passé, IRIS SQL supportait une version opt-in très rudimentaire de ce contrôle, mais la version 2021.2 introduit une toute nouvelle infrastructure RTPC, beaucoup plus légère et capable d'intervenir pour une plus grande variété de conditions de prédicat. Ayant établi que les frais généraux de cette vérification d'exécution sont effectivement minimes, nous avons décidé de l'activer par défaut, de sorte que vous n'avez rien à faire pour en bénéficier (à part [unfreeze vos plans de requête après la mise à niveau](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCRN_upgrade_intro#GCRN_upgrade_intro_frozen) comme d'habitude).
Nous avons souvent constaté à quel point les valeurs aberrantes sont fréquentes dans les ensembles de données du monde réel (et à quel point une distribution strictement uniforme est rare) et les tests sur un benchmark partenaire ont montré une amélioration spectaculaire des performances et des I/O, comme vous pouvez le voir dans le graphique ci-dessous. Nous avons également inclus les résultats du benchmark pour la version 2020.1, afin que vous puissiez apprécier nos efforts continus (et les résultats !) pour améliorer les performances au fil des versions.
Le temps de débit varie en fonction de la quantité de valeurs aberrantes dans votre ensemble de données et de la disponibilité des indices, mais nous sommes très enthousiastes quant au potentiel de ce changement et nous sommes très curieux de connaître vos expériences.
Article
Guillaume Rongier · Mai 3, 2022
Voici le deuxième article de notre série sur les améliorations apportées à la version 2021.2 de SQL, qui offre une expérience SQL adaptative et performante. Dans cet article, nous allons examiner les innovations en matière de collecte Table Statistics, qui sont bien sûr le principal élément d'entrée pour la capacité de Run Time Plan Choice que nous avons décrite dans l'article précédent.
Vous nous avez probablement entendu dire cela à plusieurs reprises : Tunez vos tables!
Pour ajuster vos tableaux à l'aide de la [commande SQL `TUNE TABLE`](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=RSQL_tunetable) ou [`$SYSTEM.SQL.Stats.Table` ObjectScript API](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.SQL.Stats.Table#GatherTableStats) vous devez recueillir des statistiques sur les données de votre tableau pour aider IRIS SQL à élaborer un bon plan de requête. Ces statistiques comprennent des informations importantes telles que le nombre approximatif de lignes dans le tableau, ce qui aide l'optimiseur à décider de choses telles que l'ordre des JOIN (commencer par le tableau le plus petit est généralement plus efficace). De nombreux appels au support InterSystems concernant les performances des requêtes peuvent être résolus en exécutant simplement `TUNE TABLE` et en faisant un nouvel essai, car l'exécution de la commande invalidera les plans de requêtes existants afin que la prochaine invocation prenne en compte les nouvelles statistiques. D'après ces appels au support, nous voyons deux raisons récurrentes pour lesquelles ces utilisateurs n'avaient pas encore collecté les statistiques de tableaux : ils n'en connaissaient pas l'existence, ou ils ne pouvaient pas se permettre les frais d'exécution sur le système de production. Dans la version 2021.2, nous avons résolu ces deux problèmes.
Échantillonnage au niveau des blocs
Commençons par le second : le coût de la collecte des statistiques. Il est vrai que la collecte de statistiques sur les tables peut entraîner une quantité considérable d'entrées/sorties (I/O) et donc une surcharge si vous analysez l'ensemble de la table. L'API prenait déjà en charge l'échantillonnage seulement d'un sous-ensemble de lignes, mais cette opération avait tout de même la réputation d'être coûteuse. Dans la version 2021.2, nous avons modifié la situation pour ne plus sélectionner des lignes aléatoires en bouclant sur la globale de la carte principale, mais pour atteindre immédiatement le stockage physique sous-jacent et laisser le noyau prendre un échantillon aléatoire des blocs de base de données bruts pour cette globale. À partir de ces blocs échantillonnés, nous déduisons les lignes de tableau SQL qu'ils stockent et poursuivons avec notre logique habituelle de construction de statistiques par champ.
On peut comparer cela au fait de se rendre à un grand festival de la bière et, au lieu de parcourir toutes les allées et de choisir quelques stands de brasseries pour mettre une bouteille chacun dans son panier, de demander aux organisateurs de vous donner un casier avec des bouteilles prises au hasard et de vous épargner la marche (dans cette analogie de dégustation de bière, la marche serait en fait une bonne idée  ). Pour se calmer, voici un simple graphique représentant l'ancienne approche basée sur les lignes (croix rouges) par rapport à l'approche basée sur les blocs (croix bleues). Les avantages sont énormes pour les tableaux de grande taille, qui se trouvent être ceux sur lesquels certains de nos clients hésitaient à utiliser `TUNE TABLE`...
Il y a un petit nombre de limitations à l'échantillonnage par bloc, le plus important étant qu'il ne peut pas être utilisé sur des tables qui se trouvent en dehors des mappages de stockage par défaut (par exemple, en projetant à partir d'une structure globale personnalisée en utilisant `%Storage.SQL`). Dans de tels cas, nous reviendrons toujours à l'échantillonnage par ligne, exactement comme cela fonctionnait dans le passé.
Configuration automatique
Maintenant que nous avons résolu le problème de la perception de la surcharge, considérons l'autre raison pour laquelle certains de nos clients n'utilisaient pas `TUNE TABLE` : c'est qu'ils ne le savaient pas. Nous pourrions essayer de documenter notre façon de nous en sortir (et nous reconnaissons qu'il y a toujours de la place pour de meilleures documents), mais nous avons décidé que cet échantillonnage par blocs super efficace fournit en fait une opportunité de faire quelque chose que nous avons longtemps voulu : automatiser le tout. À partir de 2021.2, lorsque vous préparez une requête sur une table pour lequel aucune statistique n'est disponible, nous utiliserons d'abord le mécanisme d'échantillonnage par blocs ci-dessus pour collecter ces statistiques et les utiliser pour la planification de la requête, en sauvegardant les statistiques dans les métadonnées de la table afin qu'elles puissent être utilisées par les requêtes suivantes.
Si cela peut sembler effrayant, le graphique ci-dessus montre que ce travail de collecte de statistiques ne prend que quelques secondes pour les tables de la taille d'un Go. Si vous utilisez un plan de requête inapproprié pour interroger une telle table (en raison de l'absence de statistiques appropriées), cela risque d'être beaucoup plus coûteux que de procéder à un échantillonnage rapide dès le départ. Bien sûr, nous ne le ferons que pour les tables où nous pouvons utiliser l'échantillonnage par blocs et (malheureusement) nous procéderons sans statistiques pour ces tables spécialles qui ne supportent que l'échantillonnage par lignes.
Comme pour toute nouvelle fonctionnalité, nous sommes impatients de connaître vos premières expériences et vos commentaires. Nous avons d'autres idées concernant l'automatisation dans ce domaine, comme la mise à jour des statistiques en fonction de l'utilisation des tableaux, mais nous aimerions nous assurer que ces idées sont fondées sur les expériences acquises en dehors du laboratoire.