Le serveur FHIR fait fonctionner le projet Vulcain au cours du HL7 FHIR Connectathon
![]()
Lancement du serveur FHIR d'InterSystems lors du HL7 FHIR Connectathon à Baltimore le week-end dernier, avec affichage de bundles, utilisation de toutes les RESTy avec les ressources et interrogation du Guide de mise en œuvre de Vulcan Vulcan Implementation Guide. Nous avons chevauché les projets Real World Data (RWD) et Schedule of Activity (SoA) pour Vulcan IG, qui font avancer la connexion des données de recherche clinique et de santé. Nous avons utilisé une approche assez décente pour répondre aux exigences,
MMoi-même, ainsi que les collègues d'InterSystems (Huy, Russell, Regilo), nous étions chargés de soutenir le serveur FHIR et l'appropriation des données pour l'événement. Si vous avez déjà été chargé de rédiger des Bundles FHIR pour un cas d'utilisation spécifique, je pense que vous pouvez apprécier à quel point la difficulté peut être insurmontable.
Nous avons provisionné deux serveurs InterSystems FHIR de la taille d'un radiocassette "ghetto blaster", 16 cœurs/128 Go, un pour chaque projet et nous nous sommes mis au travail pour chaque équipe. Les équipes sont arrivées préparées avec leurs Python Notebooks sur nos points de terminaison, avec l'intention d'écrire une histoire FHIR pour ACS avec un script de test procédural qui valide les appels retournés avec les résultats attendus.
La cible de cohorte pour RWD me semble assez simple dans l'exemple des requêtes pour le syndrome coronarien aigu :
N'est-ce pas ?
/Patient?birthdate=le2002-09-01&gender=male,female
/Encounter?reason-code:below=I20,I21,I22,I23,I24,I25&date=ge2020-09-01&date=le2021-09-31&status=finished&dischargeDisposition:not=exp
/MedicationAdministration?status=completed&effective-time=ge[Encounter-Start-Date]&
code=http://www.nlm.nih.gov/research/umls/rxnorm|1116632,http://www.nlm.nih.gov/research/umls/rxnorm|613391,http://www.nlm.nih.gov/research/umls/rxnorm|32968,http://www.nlm.nih.gov/research/umls/rxnorm|687667,http://www.nlm.nih.gov/research/umls/rxnorm|153658
Mais oui...
Échecs Bombe de sous-module Synthea Bien que plein d'espoir, notre premier essai a consisté à générer 2 millions de ressources et des milliers de bundles Synthea (en utilisant ce super InterSystems repo pour le faire) vers le point de terminaison des transactions et l'installation de téléchargement de la Gestion des données, y compris un tas de submodules centrés sur le cœur, et des commutateurs sophistiqués...
docker run --rm -v $PWD/output:/output -v $PWD/modules:/modules --name synthea-docker intersystemsdc/irisdemo-base-synthea:version-$VERSION --exporter.practitioner.fhir.export true --exporter.hospital.fhir.export true --exporter.fhir.use_us_core_ig true -p 500 -s 21 -d /modules
Cela n'a pas marché, ce qui n'est pas surprenant, mais j'espérais qu'on s'en rapprocherait au moins. Nous n'avons pas réussi.
Gains Le processus de génération des données Ainsi Geoff Low nous a mis au courant de son processus, nous l'avons repris et nous nous sommes mis au travail..... Voici comment le processus fonctionne.
-
Voici un bundle de départ, en particulier celui qui est pertinent pour la recherche et qui comporte au moins des patients et des rendez-vous. Utilisez le bundle SDTM ici sur sourceforge:
-
Maintenant, exécutez une étape de correction, pour fixer le bundle en place, assurez-vous qu'il se charge avec succès sur le serveur FHIR, téléchargez ou déposez le bundle POST.
-
Une fois que nous avons un point de départ précis, complétez les rendez-vous avec les codes de motif de rendez-vous anticipés ( I20,I21,I22,I23,I24,I25 ).
raisons = ["I21","I22","I23","I24","I25"]```
- Ajoutez les médicaments aux rendez-vous, en incluant tous les médicaments prévus pour le rendez-vous pour le Sondage du SCA.
medchoices = [
{
"code": "1116632",
"affichage": "ticagrelor"
},
{
"code": "613391",
"affichage": "prasurgrel"
},
{
"code": "32968",
"affichage": "clopidogrel"
}
]
medchoice = random.choice(medchoices)
medconcept = CodeableConcept(
coding=[
Coding(
code=medchoice["code"],
display=medchoice["affichage"],
system="http://www.nlm.nih.gov/research/umls/rxnorm",
)
]
)
AVIS IMPORTANT ! Assurez-vous que les médicaments correspondent aux dates/heures du rendez-vous
- Ensuite, assurez-vous que les rendez-vous sont effectivement des hospitalisations et qu'ils incluent tous les types applicables.
statuts = ["en cours", "achevé"]
dischargeCodes =
{
"code": "home",
"affichage": "Maison"
},
{
"code": "hosp",
"affichage": "Hospice"
},
{
"code": "exp",
"affichage": "Expiré"
},
{
"code": "long",
"affichage": "Soins à long terme"
},
{
"code": "alt-home",
"affichage": "Maison alternative"
},
]
Encore un gain Implémentation du paramètre de recherche IG Le Guide de mise en œuvre de Vulcan comprend un paramètre de recherche qui doit retourner les rendez-vous par disposition de sortie, nous avons abordé cela de deux façons :
a. Téléchargez l'ensemble de l'IG b. Téléchargez le paramètre de recherche "Search Parameter"
Le chargement du paramètre de recherche par lui-même était le chemin le plus court et nous en portions l'entière responsabilité depuis assez longtemps, voici donc comment se déroule ce processu.
On crée un dossier /tmp/mypackage, on ajoute le paramètre de recherche de l'IG, et son propre fichier de paquetage.
[irisdeploy@ip-192-168-0-37 tmp]$ tree /tmp/mypackage
/tmp/mypackage
├── package.json
└── parameter.json
Votre fichier de paquetage peut avoir une forme similaire à celle-ci :
{
"nom":"ron.sweeney.r4",
"version":"0.0.1",
"dépendances": {
"hl7.fhir.r4.core":"4.0.1"
}
}
Ensuite, on télécharge le tout dans IRIS comme suit :
TL4:IRIS:FHIRDB>do ##class(HS.FHIRMeta.Load.NpmLoader).importPackages($lb("/tmp/mypackage"))
Saving ron.sweeney.r4@0.0.1
Load Resources: ron.sweeney.r4@0.0.1
L'étape suivante consiste à associer le bundle au point de terminaison :
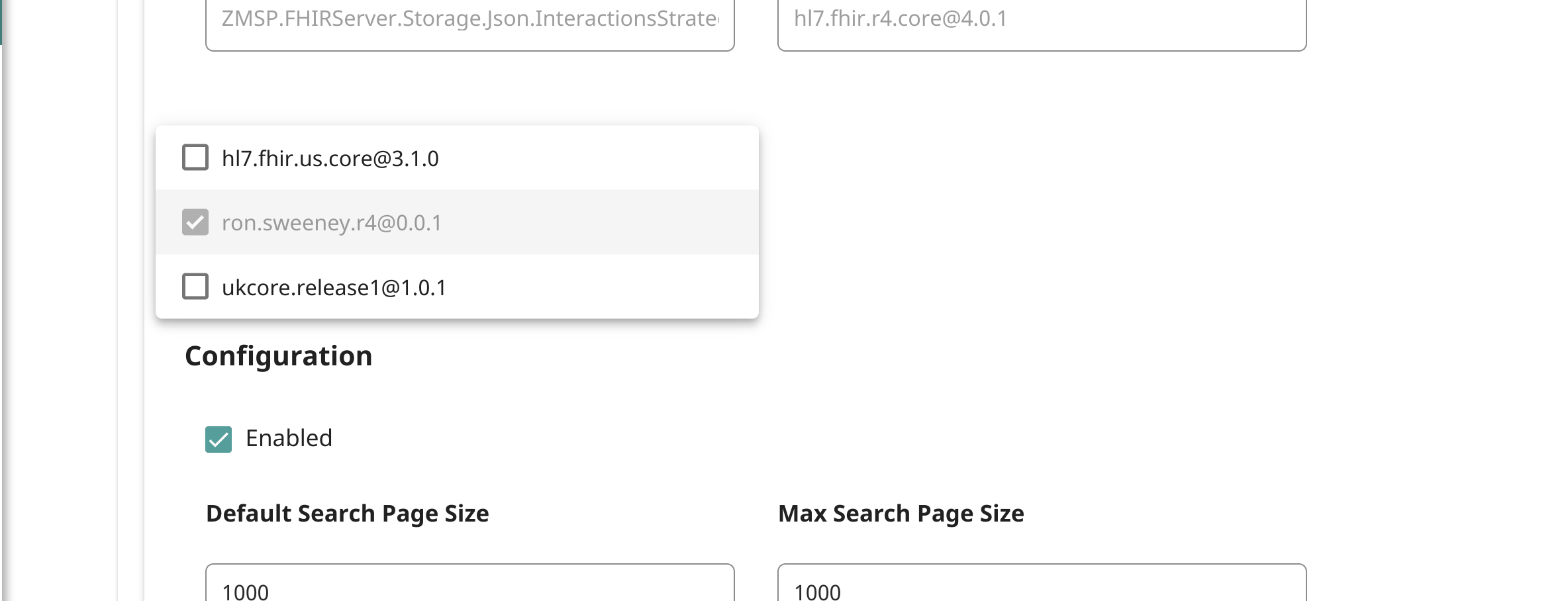
Ensuite, réindexez les rendez-vous dans le référentiel :
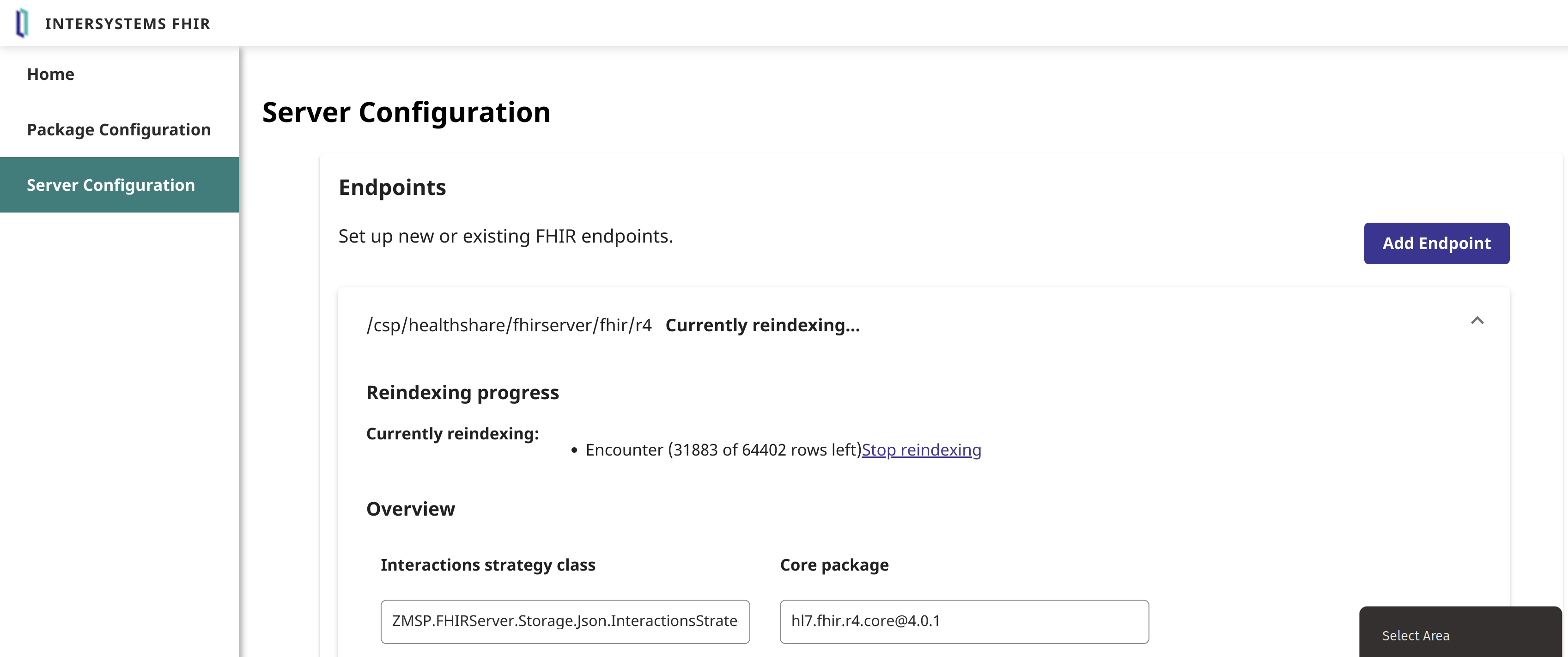
Le paramètre de recherche/bundle devrait maintenant être téléchargé à votre point de terminaison :
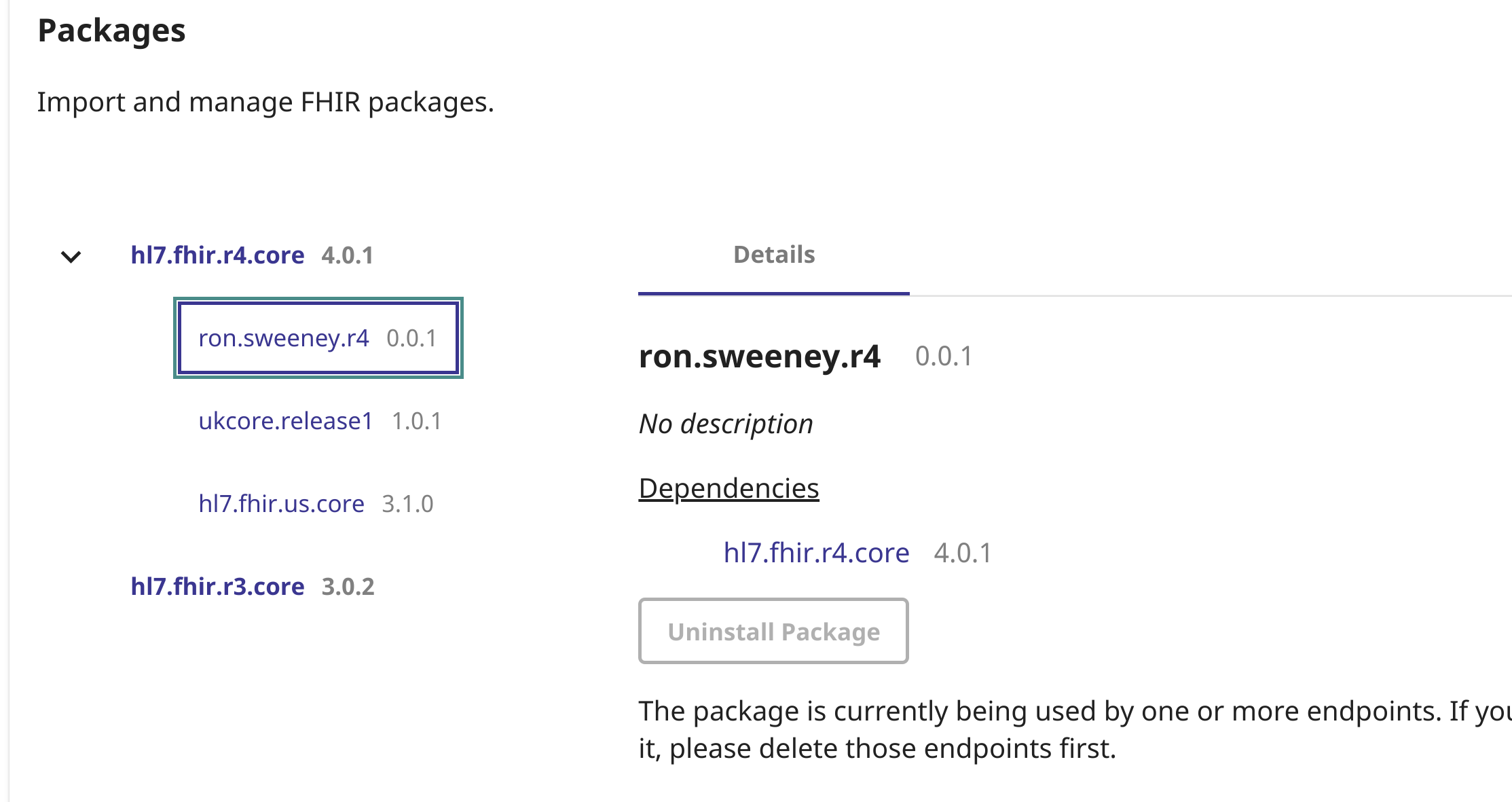
Une fois le paramètre de recherche téléchargé, nous avons pu l'utiliser comme suit !
curl https://fhir.ggyxlz8lbozu.workload-prod-fhiraas.isccloud.io/Encounter?dischargeDisposition=hosp
Quoi qu'il en soit, le processus a fonctionné, et l'approche de la création de bundles par le biais de Python s'est avérée bien meilleure que celle de Synthea, notamment pour les ensembles de données précis.
L'ensemble de données que nous avons obtenu dimanche se trouve ici.
Je voulais juste partager cette expérience et remercier les équipes des projets pour avoir rendu cette expérience, que je pensais être un cauchemar, amusante et éducative !