IRIS et Presto pour des requêtes SQL performantes et évolutives
L'essor des projets Big Data, des analyses en libre-service en temps réel, des services de recherche en ligne et des réseaux sociaux, entre autres, a donné naissance à des scénarios de requête de données massives et très performantes. En réponse à ce défi, la technologie MPP (base de données de traitement hautement parallèle) a été créée et s'est rapidement imposée. Parmi les options MPP open-source, Presto (https://prestodb.io/) est la plus connue. Cette solution a vu le jour au sein de Facebook et a été utilisée pour l'analyse de données, avant d'être mise à disposition en libre accès. Cependant, depuis que Teradata a rejoint la communauté Presto, elle offre désormais un support.
Presto se connecte aux sources de données transactionnelles (Oracle, DB2, MySQL, PostgreSQL, MongoDB et autres bases de données SQL et NoSQL) et fournit un traitement de données SQL distribué et en mémoire, combiné à des optimisations automatiques des plans d'exécution. Son objectif est avant tout d'exécuter des requêtes rapides, que vous traitiez des gigaoctets ou des téraoctets de données, en mettant à l'échelle et en parallélisant les charges de travail.
Presto n'avait pas à l'origine de connecteur natif pour la base de données IRIS, mais heureusement, ce problème a été résolu avec un projet communautaire d'InterSystems "presto-iris"(https://openexchange.intersystems.com/package/presto-iris). C'est pourquoi nous pouvons maintenant exposer une couche MPP devant les référentiels IRIS d'InterSystems pour permettre des requêtes, des rapports et des tableaux de bord de haute performance à partir de données transactionnelles dans IRIS.
Dans cet article, nous suivrons un guide étape par étape pour configurer Presto, le connecter à IRIS et établir une couche MPP pour vos clients. Nous démontrerons également les principales fonctionnalités de Presto, ses commandes et outils principaux, toujours avec IRIS en tant que base de données source.
Caractéristiques de Presto
Les caractéristiques de Presto comprennent les fonctionnalités suivantes:
- Architecture simple mais extensible.
- Connecteurs enfichables (Presto prend en charge les connecteurs enfichables pour fournir des métadonnées et des données pour les requêtes).
- Exécutions en pipeline (cela évite les surcharges de latence d'E/S (I/O) inutiles).
- Fonctions définies par l'utilisateur (les analystes peuvent créer des fonctions personnalisées définies par l'utilisateur pour faciliter la migration).
- Traitement en colonne vectorisé.
Avantages de Presto
Vous trouverez ci-dessous une liste des avantages offerts par Apache Presto:
Opérations SQL spécialisées;
Installation et débogage faciles;
Abstraction de stockage simple;
Évolutivité rapide des données en pétaoctets avec une faible latence.
Architecture de Presto
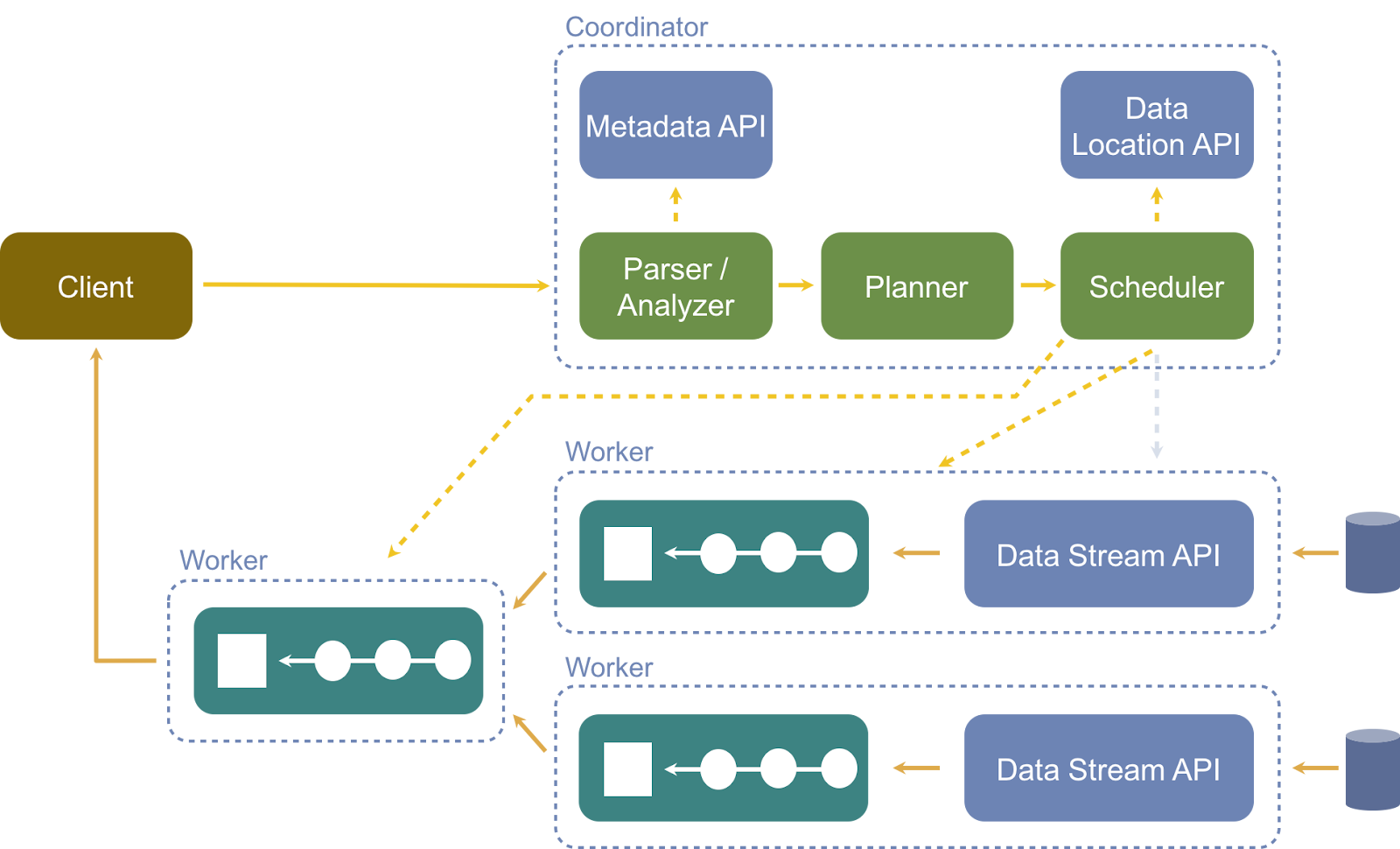
- Clients: Ils sont les utilisateurs de PrestoDB. Les clients utilisent le protocole JDBC/ODBC/REST pour communiquer avec les coordinateurs.
- Les coordinateurs: Ils sont responsables de la gestion des nœuds de travail associés, de l'analyse, du traitement des requêtes et de la génération des plans d'exécution. Ils sont également chargés de la livraison des données pour le traitement entre les opérateurs, ce qui crée des plans logiques composés d'étapes, où chaque étape est exécutée de manière distribuée à l'aide de tâches entre les opérateurs.
- Opérateurs: Il s'agit de nœuds de calcul pour l'exécution de tâches et le traitement de données, permettant le traitement et la consommation de données à grande échelle./li>
- Communication: Chaque travailleur Presto communique avec le coordinateur à l'aide d'un serveur de découverte pour se préparer au travail.
- Connecteurs: Chaque type de source de données possible possède un connecteur utilisé par Presto pour consommer les données. Le projet https://openexchange.intersystems.com/package/presto-iris permet l'utilisation d'InterSystems IRIS par Presto.
- Catalogue: Il contient des informations sur l'emplacement des données, y compris les schémas et la source de données. Lorsque les utilisateurs exécutent une instruction SQL dans Presto, ils l'exécutent contre un ou plusieurs catalogues
Cas d'utilisation de Presto
InterSystems IRIS et Presto offrent ensemble les possibilités d'utilisation suivantes:
- Requêtes ad hoc: Vous pouvez exécuter des requêtes ad hoc très performantes sur des téraoctets de données.
- Rapports et tableaux de bord: Il existe un moteur permettant de réaliser des requêtes de données très performantes pour les rapports, l'informatique décisionnelle en libre-service et les outils d'analyse, par exemple Apache Superset (découvrez l'exemple dans cet article).
- Mode lac de données (Open lakehouse): Presto has the connectors and catalogs to unify required data sources and deliver scalable queries and data using SQL between workers.
InterSystems IRIS est un partenaire idéal pour Presto. Comme il s'agit d'un référentiel de données à haute performance qui supporte le traitement distribué à l'aide de shards et associé aux opérateurs Presto, n'importe quel volume de données peut être interrogé en seulement quelques millisecondes.
Installation et lancement de PrestoDB
Il y a plusieurs options (Docker et Java JAR) pour l'installation de Presto. Vous pouvez trouver plus de détails à ce sujet sur https://prestodb.io/docs/current/installation/deployment.html. Dans cet article, nous utiliserons Docker. Pour faciliter la connaissance et permettre un démarrage rapide, nous avons mis à disposition un exemple d'application sur Open Exchange (il a été dérivé d'un autre logiciel https://openexchange.intersystems.com/package/presto-iris). Suivez les étapes suivantes pour vous en faire une idée:
- Accédez à https://openexchange.intersystems.com/package/iris-presto-sample pour télécharger l'échantillon utilisé dans ce tutoriel.
- Lancer l'environnement de démonstration avec docker-compose:
Note : Pour les besoins de la démo, il utilise Apache Superset avec superset-iris et les exemples qui l'accompagnent. Il faut donc un certain temps pour que la démonstration se télécharge.docker-compose up -d --build - L'interface utilisateur Presto sera disponible via ce lien: http://localhost:8080/ui/#.
- Attendez 15 à 20 minutes (il y a beaucoup d'échantillons de données à télécharger). Lorsque SuperSet aura fini de télécharger les échantillons après 10 à 15 minutes, il devrait être disponible sur le lien http://localhost:8088/databaseview/list (saisissez admin/admin comme nom d'utilisateur/mot de passe sur la page de connexion).
- Accédez maintenant à la rubrique Tableaux de bord:
- Si nous visitons http://localhost:8080/ui, nous pouvons remarquer que Presto a exécuté des requêtes et affiche des statistiques:
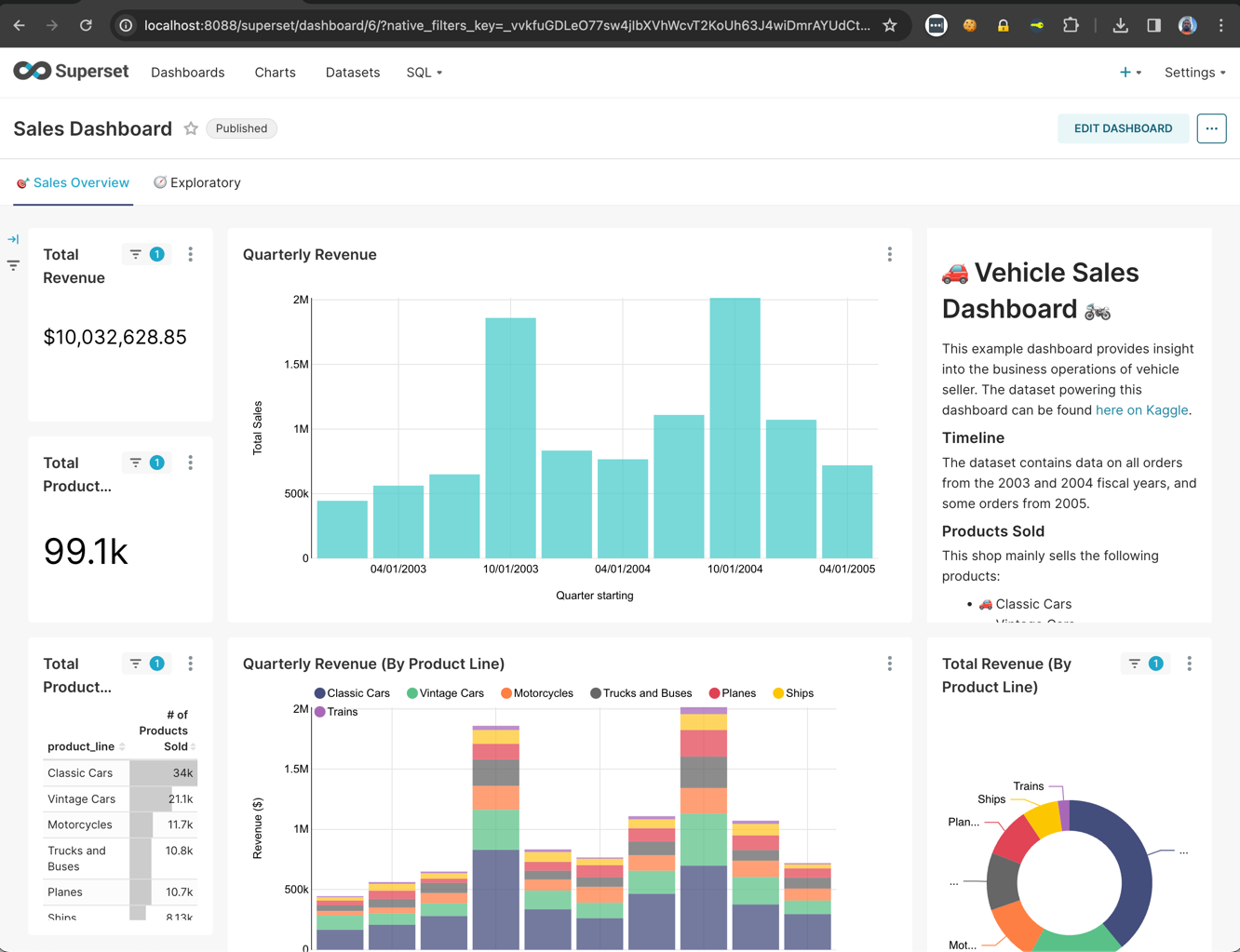
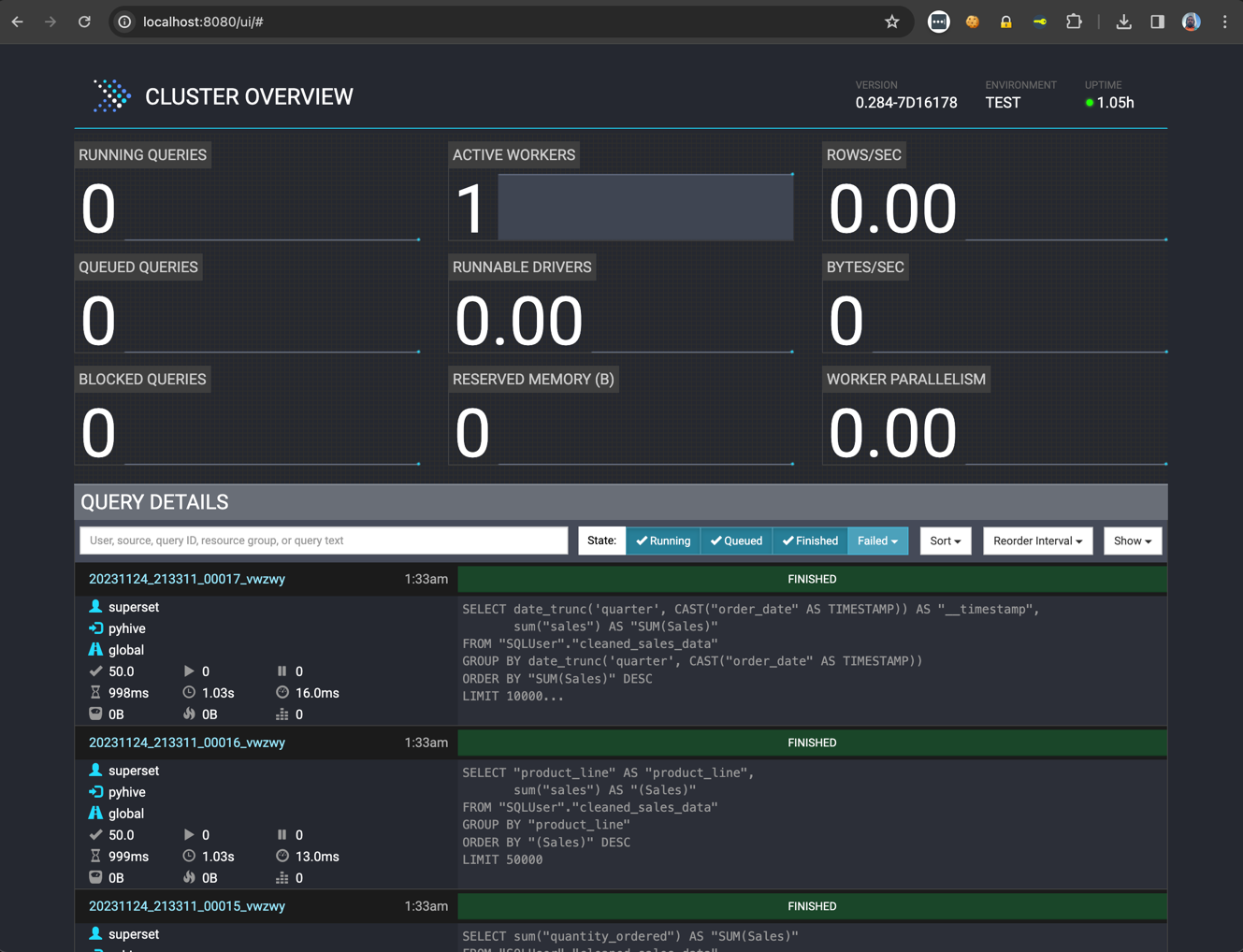
Ci-dessus, vous pouvez voir l'interface web de Presto pour surveiller et gérer les requêtes. On peut y accéder à partir du numéro de port spécifié dans les propriétés de configuration du coordinateur (pour cet article, le numéro de port est 8080).
Détails sur l'exemple de code
Fichier Dockerfile
Le fichier Dockerfile est utilisé pour créer une image Docker PrestoDB avec le plugin presto-iris et le fichier JDBC InterSystems IRIS inclus:
# Image officielle de PrestoDB sur Docker Hub
FROM prestodb/presto
# À partir de https://github.com/caretdev/presto-iris/releases
# Ajout du plugin presto-iris dans l'image Docker
ADD https://github.com/caretdev/presto-iris/releases/download/0.1/presto-iris-0.1-plugin.tar.gz /tmp/presto-iris/presto-iris-0.1-plugin.tar.gz
# À partir de https://github.com/intersystems-community/iris-driver-distribution
# Ajout du pilote IRIS JDBC dans l'image Docker
ADD https://raw.githubusercontent.com/intersystems-community/iris-driver-distribution/refs/heads/main/JDBC/JDK18/com/intersystems/intersystems-jdbc/3.8.4/intersystems-jdbc-3.8.4.jar /opt/presto-server/plugin/iris/intersystems-jdbc-3.8.4.jar
RUN --mount=type=bind,src=.,dst=/tmp/presto-iris
tar -zxvf /tmp/presto-iris/presto-iris-0.1-plugin.tar.gz -C /opt/presto-server/plugin/iris/ --strip-components=1
Fichier Docker-compose.yml
Ce fichier crée 3 instances de conteneurs : une instance pour InterSystems IRIS (service IRIS), une instance pour PrestoDB (service Presto) et une instance pour Superset (service Superset). Le Superset est un outil de visualisation analytique utilisé pour afficher des données dans des tableaux de bord.
# à partir du projet https://github.com/caretdev/presto-iris
services:
# création d'une instance de conteneur InterSystems IRIS
iris:
image: intersystemsdc/iris-community
ports:
- 1972
- 52773
environment:
IRIS_USERNAME: _SYSTEM
IRIS_PASSWORD: SYS
# création d'une instance de conteneur PrestoDB qui utilise la base de données IRIS
presto:
build: .
volumes:
# PrestoDB utilisera iris.properties pour obtenir des informations sur la connexion
- ./iris.properties:/opt/presto-server/etc/catalog/iris.properties
ports:
- 8080:8080
# création d'une instance de conteneur Superset (Outil d'analyse du tableau de bord)
superset:
image: apache/superset:3.0.2
platform: linux/amd64
environment:
SUPERSET_SECRET_KEY: supersecret
# création d'une connexion InterSystems IRIS pour le chargement des échantillons de données
SUPERSET_SQLALCHEMY_EXAMPLES_URI: iris://_SYSTEM:SYS@iris:1972/USER
volumes:
- ./superset_entrypoint.sh:/superset_entrypoint.sh
- ./superset_config.py:/app/pythonpath/superset_config.py
ports:
- 8088:8088
entrypoint: /superset_entrypoint.shFichier iris.properties
Ce fichier contient les informations nécessaires pour connecter PrestoDB à InterSystems IRIS DB et créer une couche MPP pour des requêtes performantes et évolutives à partir des tableaux de bord Superset.
# from the project https://github.com/caretdev/presto-iris
connector.name=iris
connection-url=jdbc:IRIS://iris:1972/USER
connection-user=_SYSTEM
connection-password=SYSFichier superset_entrypoint.sh
Ce script installe la bibliothèque superset-iris (pour le support d'IRIS par Superset), démarre l'instance Superset et charge des échantillons de données dans la base de données InterSystems IRIS. Au moment de l'exécution, les données consommées par Superset proviendront de PrestoDB, qui sera une couche MPP pour IRIS DB.
#!/bin/bash
# Installation de l'extension InterSystems IRIS Superset
pip install superset-iris
superset db upgrade
superset fab create-admin
--username admin
--firstname Superset
--lastname Admin
--email admin@superset.com
--password ${ADMIN_PASSWORD:-admin}
superset init
# Téléchargement d'échantillons dans IRIS
superset load-examples
# Modification de l'URI de la base de données d'échantillons en Presto
superset set-database-uri -d examples -u presto://presto:8080/iris
/usr/bin/run-server.sh
Au sujet de Superset
Il s'agit d'une plateforme moderne d'exploration et de visualisation des données qui peut remplacer ou renforcer les outils propriétaires de veille stratégique pour de nombreuses équipes.Superset s'intègre parfaitement à une grande variété de sources de données.
Superset offre les avantages suivants:
- Une interface sans code pour construire rapidement des graphiques
- Un éditeur SQL puissant basé sur le web pour des requêtes avancées
- Une couche sémantique légère pour définir rapidement des dimensions et des métriques personnalisées
- Un support prêt à l'emploi pour presque toutes les bases de données SQL ou moteurs de données
- Un large éventail de visualisations magnifiques pour présenter vos données, allant de simples diagrammes à barres à des visualisations géospatiales
- Une couche de mise en cache légère et configurable pour alléger la charge de la base de données
- Des options d'authentification et des rôles de sécurité très extensibles
- Une API pour la personnalisation programmatique
- Une architecture cloud-native conçue à partir de zéro pour s'adapter à l'échelle
Sources et supports d'apprentissage supplémentaires
- Tutoriel complet sur PrestoDB: https://www.tutorialspoint.com/apache_presto/apache_presto_quick_guide.htm
- Documentation sur PrestoDB: https://prestodb.io/docs/current/overview.html
- Plugin Presto-iris: https://openexchange.intersystems.com/package/presto-iris
- Échantillon Iris-presto: https://openexchange.intersystems.com/package/iris-presto-sample
- Au sujet de Superset: https://github.com/apache/superset
- Superset et InterSystems IRIS: https://openexchange.intersystems.com/package/superset-iris