Intégration vectorielle et recherche vocale. Analyse et points d'innovation
Cet article présente une analyse du cycle de solution pour l'application Open Exchange TOOT ( application Open Exchange)
L'hypothèse
Un bouton sur une page Web permet de capturer la voix de l'utilisateur. L'intégration IRIS permet de manipuler les enregistrements afin d' extraire la signification sémantique que la recherche vectorielle d'IRIS peut ensuite proposer pour de nouveaux types de solutions d'IA.
.png)
La signification sémantique amusante choisie concernait la recherche vectorielle musicale, afin d'acquérir de nouvelles compétences et connaissances en cours de route.
À la recherche de motifs simples
La voix humaine qui parle, siffle ou fredonne a des contraintes qui se sont exprimées à travers de nombreux encodages de données historiques à faible bande passante et de supports d'enregistrement.
Quelle quantité minimale d'informations est nécessaire pour distinguer un son musical d'un autre en relation avec une entrée vocale musicale?
Considérez la séquence des lettres de l'alphabet musical:
A, B, C, E, A
Like in programming with ASCII values of the characters:
* B est supérieur d'une unité à A
* C est supérieur d'une unité à B
* E est supérieur de deux unités à C
* A est inférieur de quatre unités à E
Représenté sous forme de progression numérique entre deux nombres:
+1, +1, +2, -4
On a besoin d'une information de moins que le nombre initial de notes.
Si l'on teste logiquement après le premier café du matin, le fredonnement devient:
B, C, D, F, B
Notez que la séquence numérique correspond toujours à cette hauteur élevée.
Cela démontre qu'une progression numérique de la différence de hauteur semble plus flexible pour correspondre à l'entrée utilisateur que des notes réelles.
Durée des notes
Le sifflement a une résolution inférieure à celle représentée par les manuscrits musicaux traditionnels.
Une décision a été prise de ne résoudre que DEUX types de durée de note musicale:
- Une note longue qui dure 0,7 seconde ou plus
- Une note courte qui dure moins de 0,7 seconde.
Vides entre les notes
Les vides ont une résolution assez faible, nous n'utilisons donc qu'un seul point d'information.
Il a été décidé de définir un vide entre deux notes comme suit:
une pause de plus d'une demi-seconde entre deux notes distinctes.
Plage de changement des notes
Une décision a été prise afin de limiter la transition maximale enregistrable entre deux notes de 45 hauteurs différentes.
Tout changement de note saisi par l'utilisateur qui dépasse cette limite est tronqué à +45 ou -45, selon que la hauteur augmente ou diminue. Contrairement aux notes réelles, cela affecte en rien l'utilité d'une séquence de recherche de mélodie continue.
+1 0 +2 -4 +2 +1 -3
Possibilité d'entraînement pour obtenir une correspondance sémantique proche de la séquence de changements indiquée en rouge.
+1 1 +2 -4 +2 +1 -3
Saisie monocanal
Une voix ou un sifflement est un instrument simple qui ne produit qu'une seule note à la fois.
Cependant, cela doit correspondre à une musique composée généralement de:
* Plusieurs instruments qui jouent simultanément
* Des instruments qui jouent des accords (plusieurs notes à la fois)
En général, un sifflement tend à suivre UNE voix ou un instrument spécifique pour représenter une musique de référence.
Lors d'enregistrements physiques, les voix et les instruments individuels peuvent être pistes distinctes qui sont ensuite "mixés" ensemble.
De même, les utilitaires d'encodage/décodage et les formats de données peuvent également préserver et utiliser des "pistes" par voix/instrument.
Il en résulte que les entrées fredonnées/sifflées doivent être recherchées en fonction de l'impression laissée par chaque piste vocale et instrumentale.
Plusieurs modèles d'encodage "musicaux" / formats linguistiques ont été envisagés.
L'option la plus simple et la plus aboutie consistait à utiliser le traitement au format MIDI pour déterminer les encodages de référence pour la correspondance et la recherche de sifflements.
Récapitulatif du vocabulaire
Outre les séquences habituelles de symboles de début, de fin et de remplissage, les points d'information sont les suivants
- 45 notes longues dont la durée diminue selon une amplitude spécifique
- 45 notes courtes dont la durée diminue selon une amplitude spécifique
- Répétition de la même note d'une durée courte
- Répétition de la même note d'une durée longue
- 45 notes longues dont la durée augmente selon une amplitude spécifique
- 45 notes courtes dont la durée augmente selon une amplitude spécifique
- Un vide entre les notes
Données synthétiques
Les globales IRIS sont très rapides et efficaces pour identifier les combinaisons et leur fréquence dans un grand ensemble de données.
Le point de départ des données synthétiques était des séquences valides.
Celles-ci ont été modifiées de différentes manières et classées en fonction de leur écart:
- SplitLongNote - Une note longue est divisée en deux notes courtes, dont la seconde est une répétition
- JoinLongNote - Deux notes courtes, dont la seconde est une répétition, sont fusionnées en une seule note longue.
- VaryOneNote ( +2, +1, -1 or -2 )
- DropSpace - Suppression de l'espace entre les notes
- AddSpace - Ajout d'un espace entre les notes
Ensuite, ces scores sont superposés de manière efficace dans une globale pour chaque résultat.
Cela signifie que lorsqu'une autre zone de séquence de changement de note dans un flux de piste est plus proche d'une valeur mutée, le score le plus élevé est toujours sélectionné.
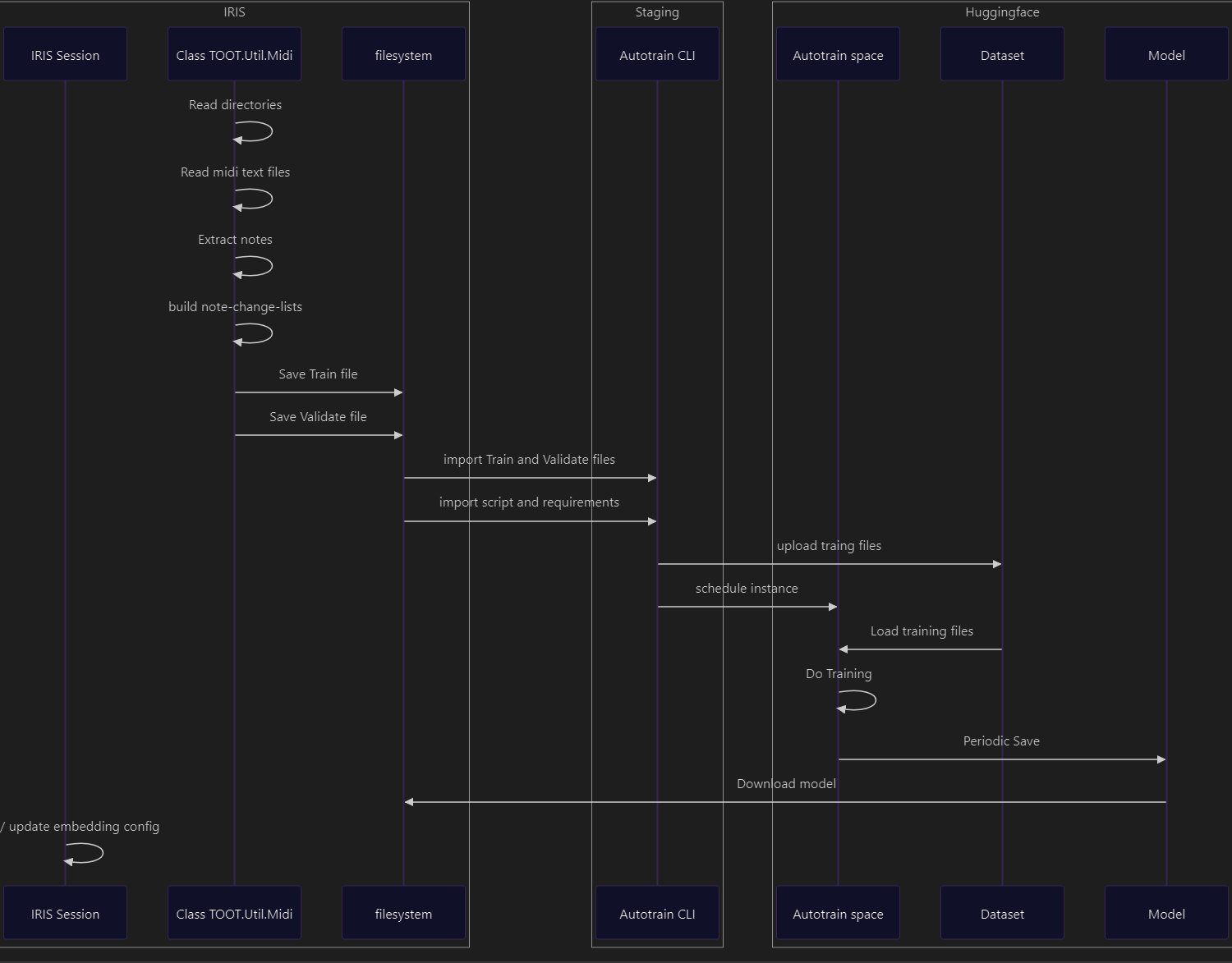
Flux de travail Dev
Flux de travail de recherche

Flux de travail DataLoad
Des intégrations vectorielles ont été générées pour plusieurs pistes d'instruments (22 935 enregistrements) et pour des échantillons mélodiques (6 762 enregistrements)

Flux de travail d'entraînement
Deux essais d'entraînement:
Sans supervision - 110 000 enregistrements maximum (7 heures de traitement)
Score de similarité sous supervision - 960 000 enregistrements maximum (1,3 jour de traitement)
Autres exigences à explorer
Meilleure mesure de la similarité
La version actuelle de l'implémentation trie les résultats en fonction des scores de manière trop stricte.
Il convient de réexaminer le seuil d'inclusion des séquences à faible et à forte occurrence dans l'ensemble de données.
Filtrage du bruit de fond
Au format MIDI, le volume des voix ou des instruments est important en termes d'utilisation réelle et de bruit de fond. Cela pourrait permettre de nettoyer/filtrer une source de données. On pourrait peut-être exclure les pistes qui ne seraient jamais référencées par une entrée humaine. Actuellement, la solution exclut les « percussions » par piste instrumentale, par titre et par analyse de certaines répétitions de progression.
Instruments MIDI synthétiques
L'approche actuelle pour faire correspondre la voix aux instruments consistait à essayer de contourner les incompatibilités entre les caractéristiques des instruments, afin de voir si cela donnait un résultat satisfaisant.
Une expérience intéressante serait d'ajouter certaines caractéristiques à partir des données fournies par l'utilisateur, tout en modifiant les données d'apprentissage synthétiques afin d'obtenir des caractéristiques plus humaines.
Le MIDI encode des informations supplémentaires avec des variations de hauteur afin d'obtenir une progression plus fluide entre les notes.
Ce serait une piste à explorer pour étendre et affiner la manière dont la conversion WAV vers MIDI est effectuée.
Conclusion
J'espère que vous avez trouvé cet article intéressant et que vous apprécierez l'application. Peut-être vous inspirera-t-elle de nouvelles idées.