Databricks Station - Cloud SQL d'InterSystems

Démarrage rapide des données SQL d'InterSystems Cloud dans Databricks
La mise en œuvre de Databricks en SQL d'InterSystems Cloud se compose de quatre parties.
- Obtention du certificat et du pilote JDBC Driver pour InterSystems IRIS
- Ajout d'un script d'initialisation et d'une bibliothèque externe à votre Cluster de calcul Databricks
- Obtention de données
- Placement des données
Téléchargement du certificat X.509/du pilote JDBC de Cloud SQL
Naviguez vers la page d'aperçu de votre déploiement, si vous n'avez pas activé de connexions externes, faites-le et téléchargez votre certificat et le pilote jdbc depuis la page d'aperçu.
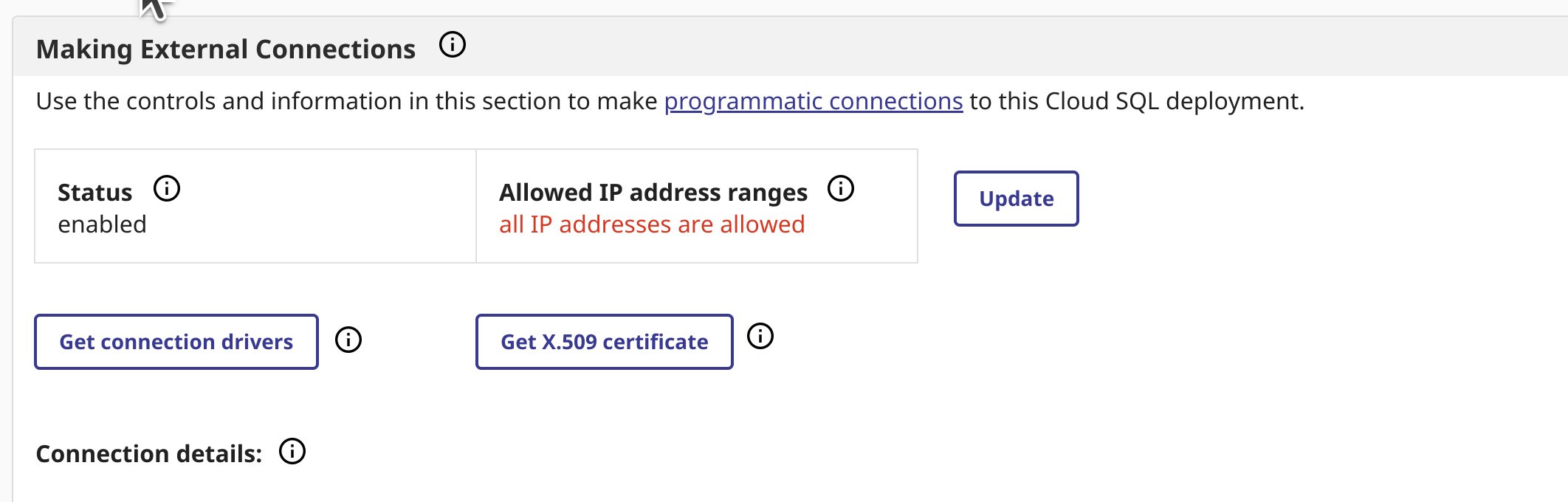
J'ai utilisé intersystems-jdbc-3.8.4.jar et intersystems-jdbc-3.7.1.jar avec succès dans Databricks à partir de la distribution de pilotes Driver Distribution.
Script d'initialisation pour votre cluster Databricks
La façon la plus simple d'importer un ou plusieurs certificats CA personnalisés dans votre cluster Databricks est de créer un script d'initialisation qui ajoute la chaîne complète de certificats CA aux magasins de certificats par défaut SSL et Java de Linux, et définit la propriété REQUESTS_CA_BUNDLE. Collez le contenu du certificat X.509 que vous avez téléchargé dans le bloc supérieur du script suivant:
import_cloudsql_certficiate.sh
#!/bin/bash
cat << 'EOF' > /usr/local/share/ca-certificates/cloudsql.crt
-----BEGIN CERTIFICATE-----
<PASTE>
-----END CERTIFICATE-----
EOF
update-ca-certificates
PEM_FILE="/etc/ssl/certs/cloudsql.pem"
PASSWORD="changeit"
JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
KEYSTORE="$JAVA_HOME/lib/security/cacerts"
CERTS=$(grep 'END CERTIFICATE' $PEM_FILE| wc -l)
# Pour traiter plusieurs certificats avec keytool, vous devez extraire
# chacun d'eux du fichier PEM et l'importer dans le KeyStore Java.
for N in $(seq 0 $(($CERTS - 1))); do
ALIAS="$(basename $PEM_FILE)-$N"
echo "Adding to keystore with alias:$ALIAS"
cat $PEM_FILE |
awk "n==$N { print }; /END CERTIFICATE/ { n++ }" |
keytool -noprompt -import -trustcacerts
-alias $ALIAS -keystore $KEYSTORE -storepass $PASSWORD
done
echo "export REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crt" >> /databricks/spark/conf/spark-env.sh
echo "export SSL_CERT_FILE=/etc/ssl/certs/ca-certificates.crt" >> /databricks/spark/conf/spark-env.sh
Maintenant vous avez le script initial, téléchargez-le dans le catalogue Unity sur un Volume.
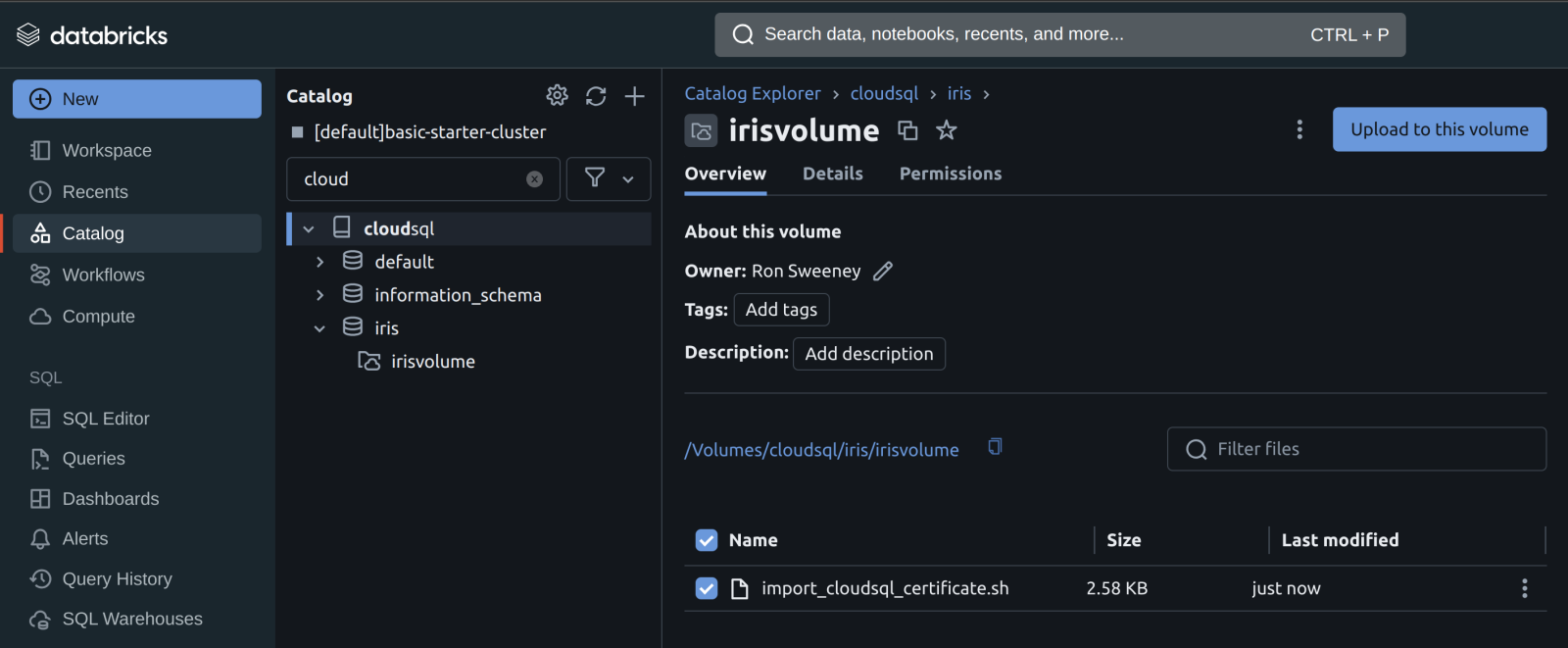
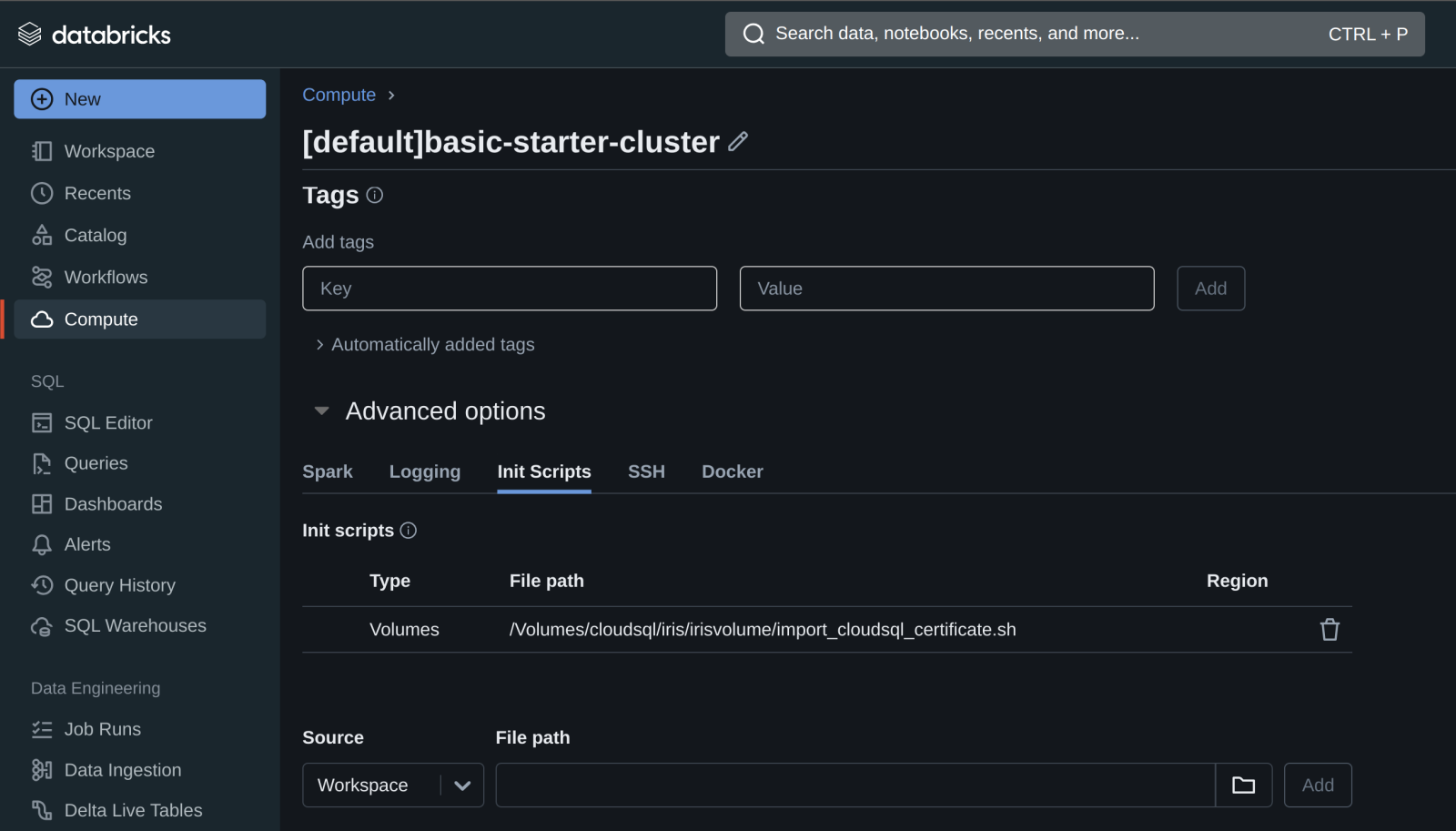
Une fois que le script est sur un volume, vous pouvez ajouter le script initial au cluster à partir du volume dans les propriétés avancées de votre cluster.
Ensuite, ajoutez le pilote/la bibliothèque intersystems jdbc au cluster...
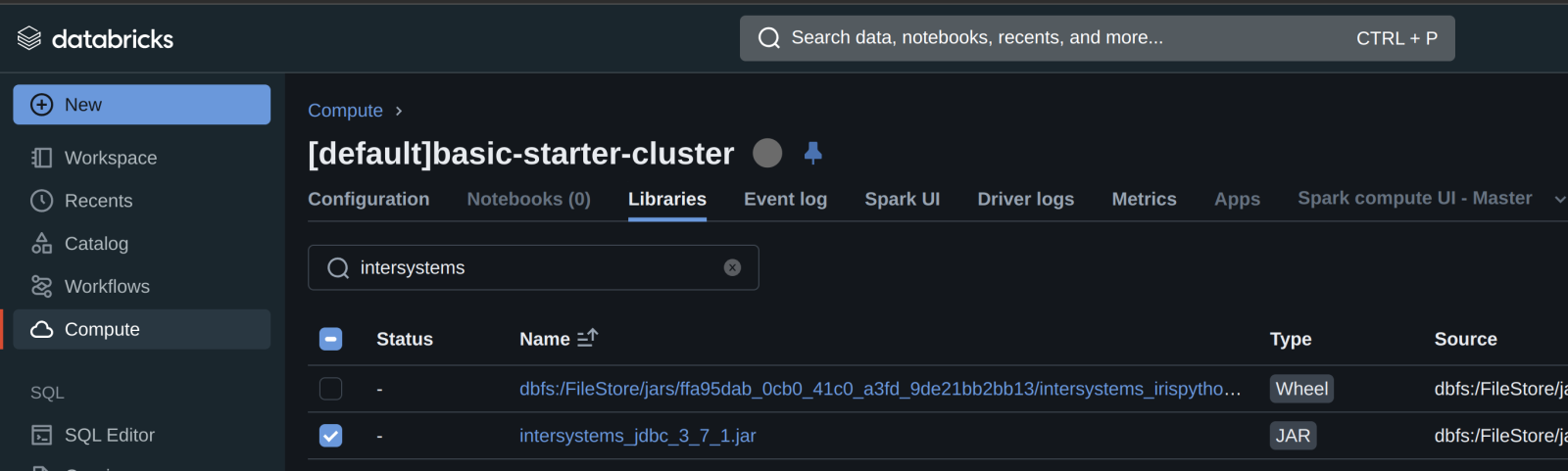
...et démarrez ou redémarrez votre calcul.
Station Databricks - Entrée vers le Cloud SQL d'InterSystems IRIS

Créez un Notebook Python dans votre espace de travail, attachez-le à votre cluster et testez le glissement de données vers Databricks. Sous le capot, Databricks va utiliser pySpark, si cela n'est pas immédiatement évident.
La construction du Dataframe Spark suivant est tout ce qu'il vous faut, vous pouvez récupérer vos informations de connexion à partir de la page d'aperçu comme auparavant.
df = (spark.read
.format("jdbc")
.option("url", "jdbc:IRIS://k8s-05868f04-a4909631-ac5e3e28ef-6d9f5cd5b3f7f100.elb.us-east-1.amazonaws.com:443/USER")
.option("driver", "com.intersystems.jdbc.IRISDriver")
.option("dbtable", "(SELECT name,category,review_point FROM SQLUser.scotch_reviews) AS temp_table;")
.option("user", "SQLAdmin")
.option("password", "REDACTED")
.option("driver", "com.intersystems.jdbc.IRISDriver")
.option("connection security level","10")
.option("sslConnection","true")
.load())
df.show()
Illustration de la production d'un dataframe à partir de données dans Cloud SQL... boom!
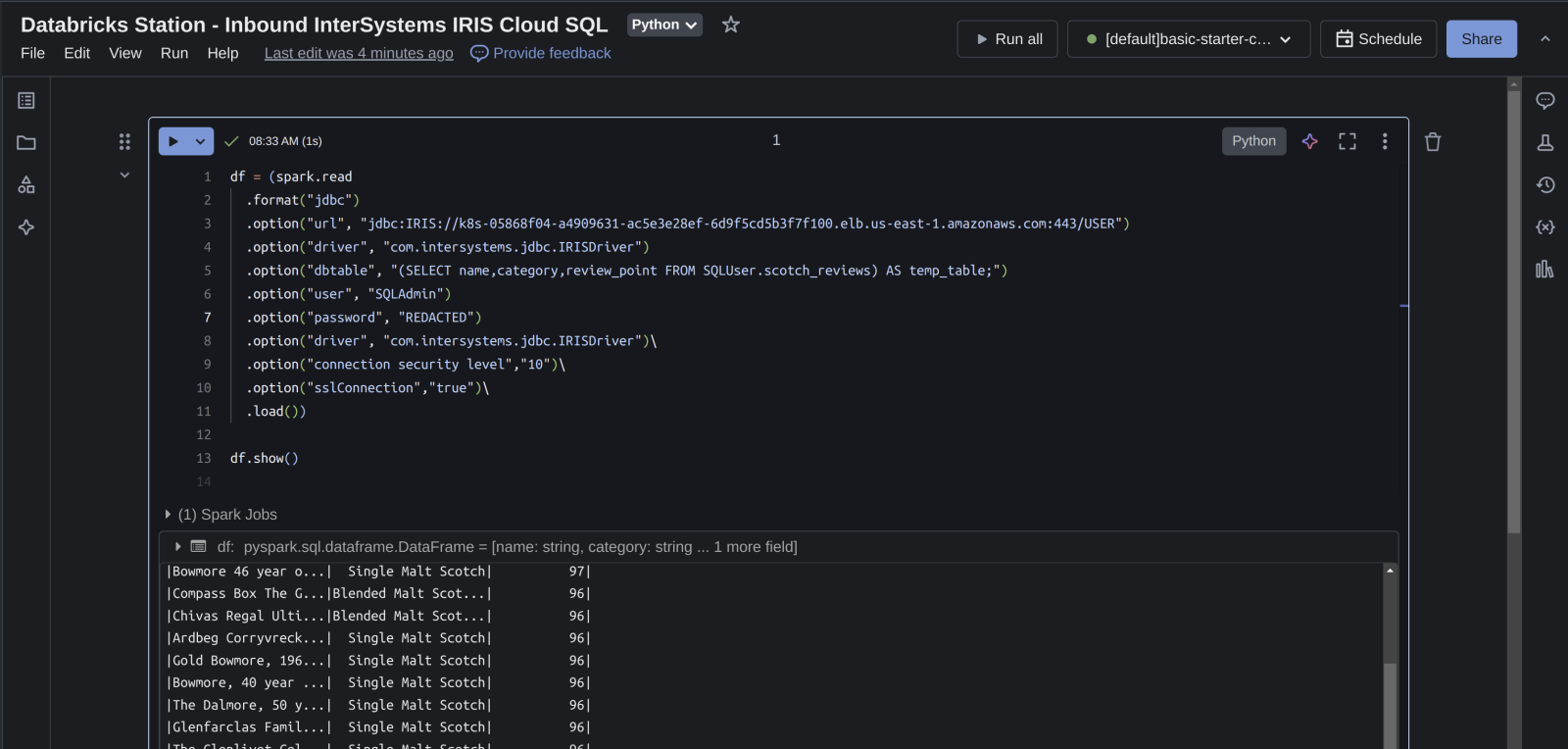
Station Databricks - Sortie du Cloud SQL d'InterSystems IRIS

Prenons maintenant ce que nous avons lu dans IRIS et écrivons-le avec Databricks. Si vous vous souvenez bien, nous n'avons lu que 3 champs dans notre cadre de données, nous allons donc les réécrire immédiatement et spécifier un mode "écraser".
df = (spark.read
.format("jdbc")
.option("url", "jdbc:IRIS://k8s-05868f04-a4909631-ac5e3e28ef-6d9f5cd5b3f7f100.elb.us-east-1.amazonaws.com:443/USER")
.option("driver", "com.intersystems.jdbc.IRISDriver")
.option("dbtable", "(SELECT TOP 3 name,category,review_point FROM SQLUser.scotch_reviews) AS temp_table;")
.option("user", "SQLAdmin")
.option("password", "REDACTED")
.option("driver", "com.intersystems.jdbc.IRISDriver")
.option("connection security level","10")
.option("sslConnection","true")
.load())
df.show()
mode = "overwrite"
properties = {
"user": "SQLAdmin",
"password": "REDACTED",
"driver": "com.intersystems.jdbc.IRISDriver",
"sslConnection": "true",
"connection security level": "10",
}
df.write.jdbc(url="jdbc:IRIS://k8s-05868f04-a4909631-ac5e3e28ef-6d9f5cd5b3f7f100.elb.us-east-1.amazonaws.com:443/USER", table="databricks_scotch_reviews", mode=mode, properties=properties)
Exécution du Notebook
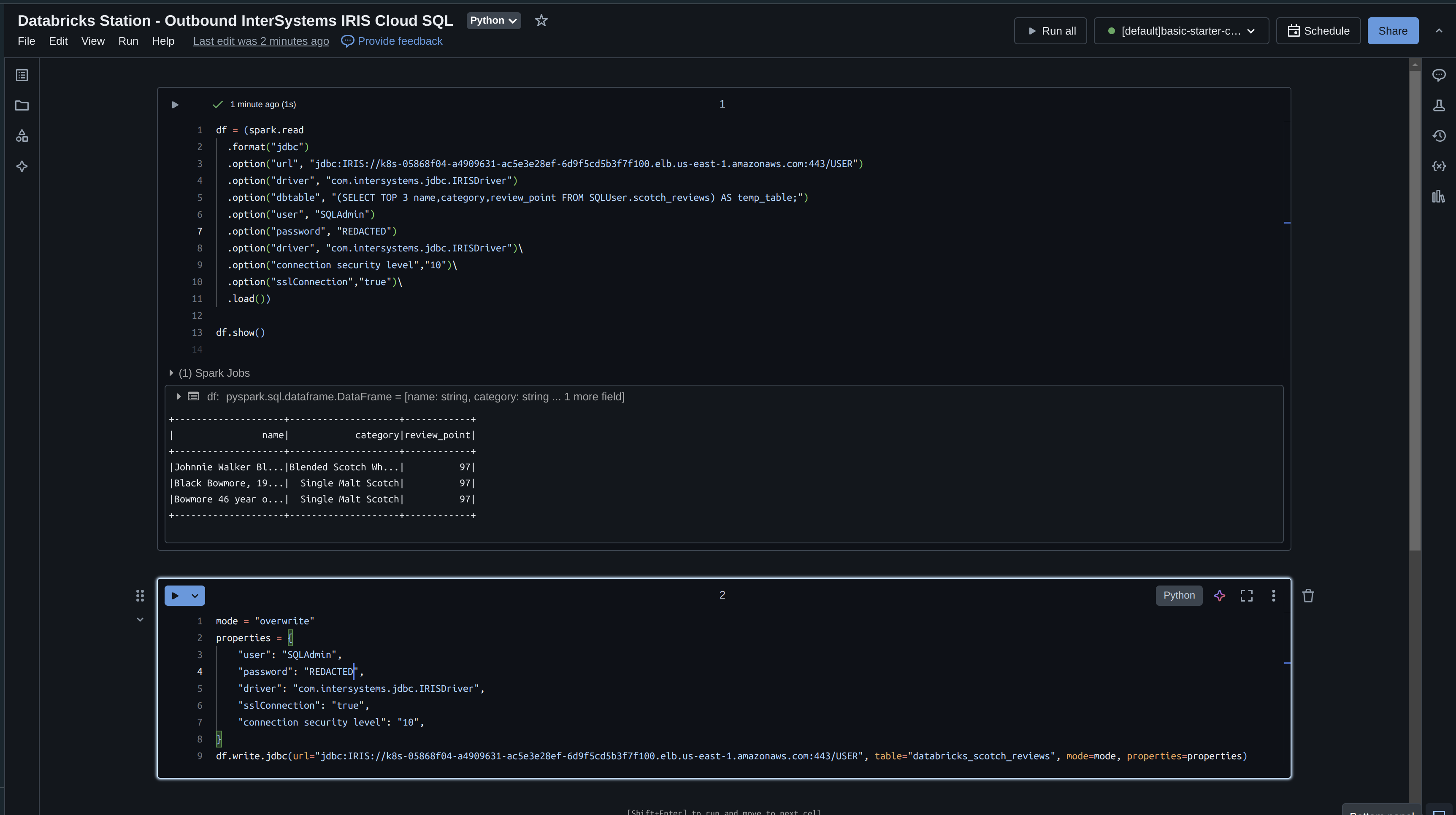
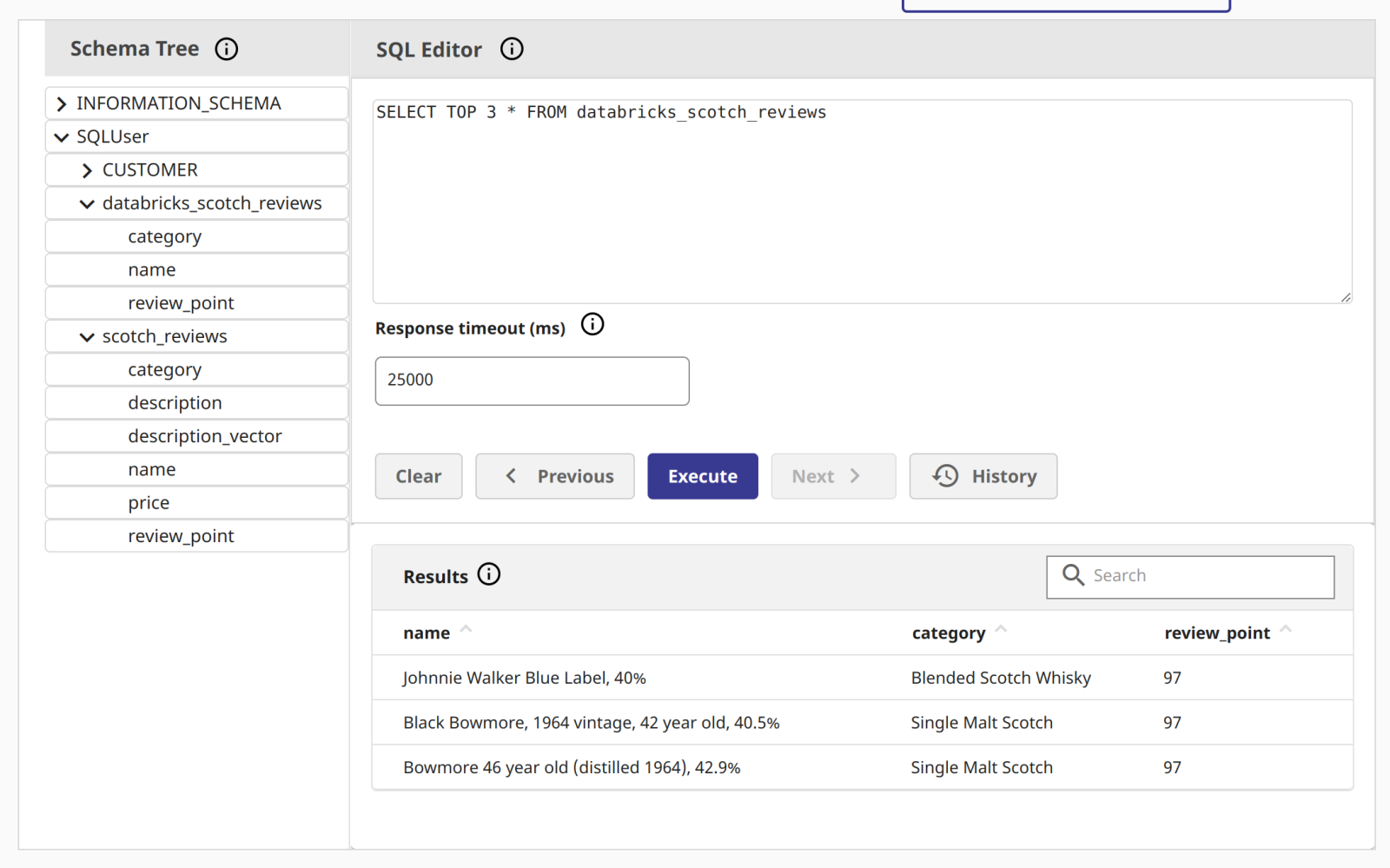
Illustration des données dans le Cloud SQL d'InterSystems!
Les points à prendre en considération
- Par défaut, PySpark écrit les données en utilisant plusieurs tâches concurrentes, ce qui peut entraîner des écritures partielles si l'une des tâches échoue.
- Pour garantir que l'opération d'écriture est atomique et cohérente, vous pouvez configurer PySpark de manière à ce que les données soient écrites à l'aide d'une seule tâche (c'est-à-dire en définissant le nombre de partitions à 1) ou utiliser une fonctionnalité spécifique à IRIS, telle que les transactions.
- En outre, vous pouvez utiliser l'API DataFrame de PySpark pour effectuer des opérations de filtrage et d'agrégation avant de lire les données de la base de données, ce qui peut réduire la quantité de données à transférer sur le réseau.