Chargez un ensemble de données de recette avec des tables étrangères et analysez-le à l'aide de LLM avec Embedded Python (Langchain + OpenAI)
Nous avons un délicieux dataset avec des recettes écrites par plusieurs utilisateurs de Reddit, mais la plupart des informations sont du texte libre comme le titre ou la description d'un article. Voyons comment nous pouvons très facilement charger l'ensemble de données, extraire certaines fonctionnalités et l'analyser à l'aide des fonctionnalités du grand modèle de langage OpenAI contenu dans Embedded Python et le framework Langchain.
Chargement de l'ensemble de données
Tout d’abord, nous devons charger l’ensemble de données ou pouvons-nous simplement nous y connecter ?
Il existe différentes manières d'y parvenir : par exemple CSV Record Mapper vous pouvez utiliser dans une production d'interopérabilité ou même de belles applications OpenExchange comme csvgen.
Nous utiliserons Foreign Tables. Une fonctionnalité très utile pour projeter des données physiquement stockées ailleurs vers IRIS SQL. Nous pouvons l'utiliser pour avoir une toute première vue des fichiers de l'ensemble de données.
Nous créons un Foreign Server:
CREATE FOREIGN SERVER dataset FOREIGN DATA WRAPPER CSV HOST '/app/data/'
Et puis une table étrangère qui se connecte au fichier CSV:
CREATE FOREIGN TABLE dataset.Recipes (
CREATEDDATE DATE,
NUMCOMMENTS INTEGER,
TITLE VARCHAR,
USERNAME VARCHAR,
COMMENT VARCHAR,
NUMCHAR INTEGER
) SERVER dataset FILE 'Recipes.csv' USING
{
"from": {
"file": {
"skip": 1
}
}
}
Et voilà, nous pouvons immédiatement exécuter des requêtes SQL sur dataset.Recipes:
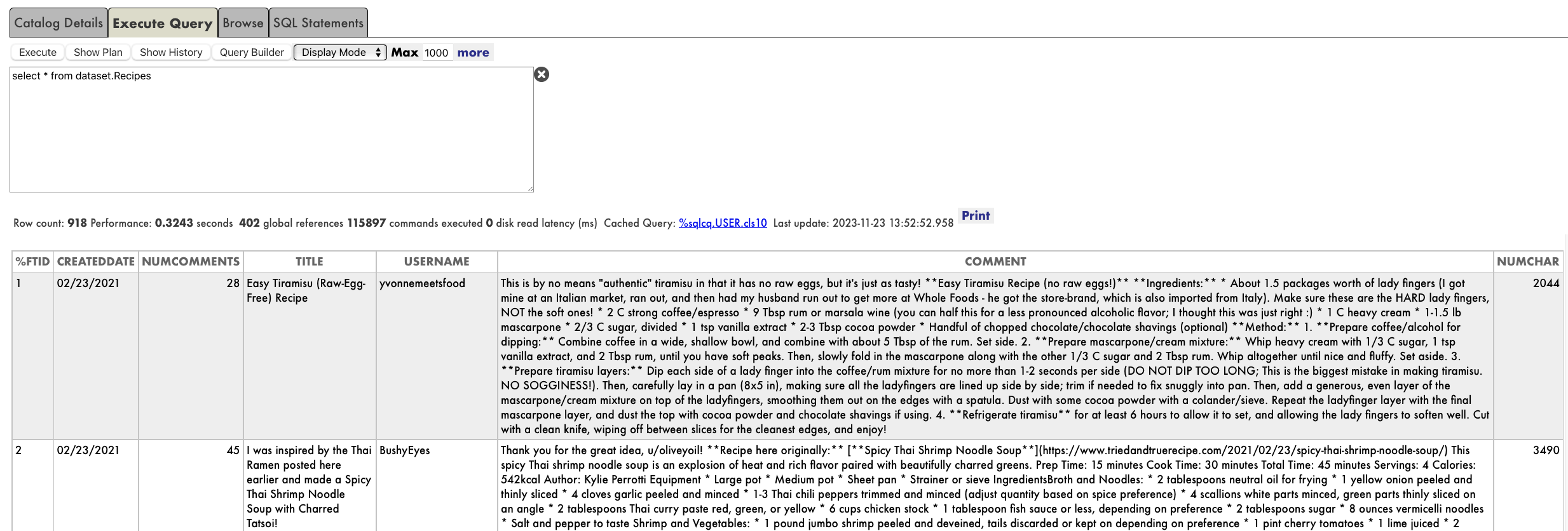
## De quelles données avons-nous besoin ? L’ensemble de données est intéressant et nous avons faim. Cependant, si nous voulons décider d'une recette à cuisiner, nous aurons besoin de plus d'informations que nous pourrons utiliser pour analyser.
Nous allons travailler avec deux classes persistantes (tables):
- yummy.data.Recipe: une classe contenant le titre et la description de la recette et quelques autres propriétés que nous souhaitons extraire et analyser (par exemple Score, Difficulty, Ingredients, CuisineType, PreparationTime)
- yummy.data.RecipeHistory: une classe simple pour enregistrer que faisons-nous avec la recette
Nous pouvons maintenant charger nos tables yummy.data* avec le contenu de l'ensemble de données:
do ##class(yummy.Utils).LoadDataset()
Cela a l'air bien, mais nous devons encore découvrir comment générer des données pour les champs Score, Difficulty, Ingredients, PreparationTime et CuisineType. ## Analyser les recettes Nous souhaitons traiter le titre et la description de chaque recette et :
- Extraire des informations telles que Difficulté, Ingrédients, Type de Cuisine, etc.
- Construire notre propre score en fonction de nos critères afin que nous puissions décider de ce que nous voulons cuisiner.
Nous allons utiliser ce qui suit :
- yummy.analysis.Analysis - une structure d'analyse générique que nous pouvons réutiliser au cas où nous souhaiterions construire plus d'analyse.
- yummy.analysis.SimpleOpenAI - une analyse qui utilise le modèle Embedded Python + Langchain Framework + OpenAI LLM.
LLM (large language models) sont vraiment un excellent outil pour traiter le langage naturel.
LangChainest prêt à fonctionner en Python, nous pouvons donc l'utiliser directement dans InterSystems IRIS en utilisant Embedded Python.
La classe complète SimpleOpenAI ressemble à ceci:
/// Analyse OpenAI simple pour les recettes
Class yummy.analysis.SimpleOpenAI Extends Analysis
{
Property CuisineType As %String;
Property PreparationTime As %Integer;
Property Difficulty As %String;
Property Ingredients As %String;
/// Run
/// Vous pouvez essayer ceci depuis un terminal :
/// set a = ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(8))
/// do a.Run()
/// zwrite a
Method Run()
{
try {
do ..RunPythonAnalysis()
set reasons = ""
// mes types de cuisine préférés
if "spanish,french,portuguese,italian,korean,japanese"[..CuisineType {
set ..Score = ..Score + 2
set reasons = reasons_$lb("It seems to be a "_..CuisineType_" recipe!")
}
// je ne veux pas passer toute la journée à cuisiner :)
if (+..PreparationTime < 120) {
set ..Score = ..Score + 1
set reasons = reasons_$lb("You don't need too much time to prepare it")
}
// bonus pour les ingrédients préférés !
set favIngredients = $listbuild("kimchi", "truffle", "squid")
for i=1:1:$listlength(favIngredients) {
set favIngred = $listget(favIngredients, i)
if ..Ingredients[favIngred {
set ..Score = ..Score + 1
set reasons = reasons_$lb("Favourite ingredient found: "_favIngred)
}
}
set ..Reason = $listtostring(reasons, ". ")
} catch ex {
throw ex
}
}
/// Mettre à jour la recette avec les résultats de l'analyse
Method UpdateRecipe()
{
try {
// appeler d'abord l'implémentation de la classe parent
do ##super()
// ajouter des résultats d'analyse spécifiques à OpenAI
set ..Recipe.Ingredients = ..Ingredients
set ..Recipe.PreparationTime = ..PreparationTime
set ..Recipe.Difficulty = ..Difficulty
set ..Recipe.CuisineType = ..CuisineType
} catch ex {
throw ex
}
}
/// Exécuter une analyse à l'aide de Embedded Python + Langchain
/// do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(8)).RunPythonAnalysis(1)
Method RunPythonAnalysis(debug As %Boolean = 0) [ Language = python ]
{
# load OpenAI APIKEY from env
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv('/app/.env')
# account for deprecation of LLM model
import datetime
current_date = datetime.datetime.now().date()
# date after which the model should be set to "gpt-3.5-turbo"
target_date = datetime.date(2024, 6, 12)
# set the model depending on the current date
if current_date > target_date:
llm_model = "gpt-3.5-turbo"
else:
llm_model = "gpt-3.5-turbo-0301"
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
# init llm model
llm = ChatOpenAI(temperature=0.0, model=llm_model)
# prepare the responses we need
cuisine_type_schema = ResponseSchema(
name="cuisine_type",
description="What is the cuisine type for the recipe? \
Answer in 1 word max in lowercase"
)
preparation_time_schema = ResponseSchema(
name="preparation_time",
description="How much time in minutes do I need to prepare the recipe?\
Anwer with an integer number, or null if unknown",
type="integer",
)
difficulty_schema = ResponseSchema(
name="difficulty",
description="How difficult is this recipe?\
Answer with one of these values: easy, normal, hard, very-hard"
)
ingredients_schema = ResponseSchema(
name="ingredients",
description="Give me a comma separated list of ingredients in lowercase or empty if unknown"
)
response_schemas = [cuisine_type_schema, preparation_time_schema, difficulty_schema, ingredients_schema]
# get format instructions from responses
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
analysis_template = """\
Interprete and evaluate a recipe which title is: {title}
and the description is: {description}
{format_instructions}
"""
prompt = ChatPromptTemplate.from_template(template=analysis_template)
messages = prompt.format_messages(title=self.Recipe.Title, description=self.Recipe.Description, format_instructions=format_instructions)
response = llm(messages)
if debug:
print("======ACTUAL PROMPT")
print(messages[0].content)
print("======RESPONSE")
print(response.content)
# populate analysis with results
output_dict = output_parser.parse(response.content)
self.CuisineType = output_dict['cuisine_type']
self.Difficulty = output_dict['difficulty']
self.Ingredients = output_dict['ingredients']
if type(output_dict['preparation_time']) == int:
self.PreparationTime = output_dict['preparation_time']
return 1
}
}
La méthode RunPythonAnalysis c'est ici qu'entre en jeu OpenAI :). Vous pouvez le lancer directement depuis votre terminal pour une recette donnée :
do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12)).RunPythonAnalysis(1)
Nous obtiendrons un résultat comme celui-ci :
USER>do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12)).RunPythonAnalysis(1)
======ACTUAL PROMPT
Interprete and evaluate a recipe which title is: Folded Sushi - Alaska Roll
and the description is: Craving for some sushi but don't have a sushi roller? Try this easy version instead. It's super easy yet equally delicious!
[Video Recipe](https://www.youtube.com/watch?v=1LJPS1lOHSM)
# Ingredients
Serving Size: \~5 sandwiches
* 1 cup of sushi rice
* 3/4 cups + 2 1/2 tbsp of water
* A small piece of konbu (kelp)
* 2 tbsp of rice vinegar
* 1 tbsp of sugar
* 1 tsp of salt
* 2 avocado
* 6 imitation crab sticks
* 2 tbsp of Japanese mayo
* 1/2 lb of salmon
# Recette
* Place 1 cup of sushi rice into a mixing bowl and wash the rice at least 2 times or until the water becomes clear. Then transfer the rice into the rice cooker and add a small piece of kelp along with 3/4 cups plus 2 1/2 tbsp of water. Cook according to your rice cookers instruction.
* Combine 2 tbsp rice vinegar, 1 tbsp sugar, and 1 tsp salt in a medium bowl. Mix until everything is well combined.
* After the rice is cooked, remove the kelp and immediately scoop all the rice into the medium bowl with the vinegar and mix it well using the rice spatula. Make sure to use the cut motion to mix the rice to avoid mashing them. After thats done, cover it with a kitchen towel and let it cool down to room temperature.
* Cut the top of 1 avocado, then slice into the center of the avocado and rotate it along your knife. Then take each half of the avocado and twist. Afterward, take the side with the pit and carefully chop into the pit and twist to remove it. Then, using your hand, remove the peel. Repeat these steps with the other avocado. Dont forget to clean up your work station to give yourself more space. Then, place each half of the avocado facing down and thinly slice them. Once theyre sliced, slowly spread them out. Once thats done, set it aside.
* Remove the wrapper from each crab stick. Then, using your hand, peel the crab sticks vertically to get strings of crab sticks. Once all the crab sticks are peeled, rotate them sideways and chop them into small pieces, then place them in a bowl along with 2 tbsp of Japanese mayo and mix until everything is well mixed.
* Place a sharp knife at an angle and thinly slice against the grain. The thickness of the cut depends on your preference. Just make sure that all the pieces are similar in thickness.
* Grab a piece of seaweed wrap. Using a kitchen scissor, start cutting at the halfway point of seaweed wrap and cut until youre a little bit past the center of the piece. Rotate the piece vertically and start building. Dip your hand in some water to help with the sushi rice. Take a handful of sushi rice and spread it around the upper left hand quadrant of the seaweed wrap. Then carefully place a couple slices of salmon on the top right quadrant. Then place a couple slices of avocado on the bottom right quadrant. And finish it off with a couple of tsp of crab salad on the bottom left quadrant. Then, fold the top right quadrant into the bottom right quadrant, then continue by folding it into the bottom left quadrant. Well finish off the folding by folding the top left quadrant onto the rest of the sandwich. Afterward, place a piece of plastic wrap on top, cut it half, add a couple pieces of ginger and wasabi, and there you have it.
Le résultat doit être un extrait de code de démarque formaté selon le schéma suivant, incluant les caractères "```json" and "```" :
json
{
"cuisine_type": string // Quel est le type de cuisine de la recette ? Réponse en 1 mot maximum en minuscule
"preparation_time": integer // De combien de temps en minutes ai-je besoin pour préparer la recette ? Répondez avec un nombre entier, ou nul si inconnu
"difficulty": string // À quel point cette recette est-elle difficile ? Répondez avec l'une de ces valeurs : facile, normal, difficile, très difficile
"ingredients": string // Donnez-moi une liste d'ingrédients séparés par des virgules en minuscules ou vide si inconnu
}
======RESPONSE
json
{
"cuisine_type": "japanese",
"preparation_time": 30,
"difficulty": "easy",
"ingredients": "sushi rice, water, konbu, rice vinegar, sugar, salt, avocado, imitation crab sticks, japanese mayo, salmon"
}
Ça à l'air bon. Il semble que notre invite OpenAI soit capable de renvoyer des informations utiles. Exécutons toute la classe d'analyse depuis le terminal :
set a = ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12))
do a.Run()
zwrite a
USER>zwrite a
a=37@yummy.analysis.SimpleOpenAI ; <OREF>
+----------------- general information ---------------
| oref value: 37
| class name: yummy.analysis.SimpleOpenAI
| reference count: 2
+----------------- attribute values ------------------
| CuisineType = "japanese"
| Difficulty = "easy"
| Ingredients = "sushi rice, water, konbu, rice vinegar, sugar, salt, avocado, imitation crab sticks, japanese mayo, salmon"
| PreparationTime = 30
| Reason = "It seems to be a japanese recipe!. You don't need too much time to prepare it"
| Score = 3
+----------------- swizzled references ---------------
| i%Recipe = ""
| r%Recipe = "30@yummy.data.Recipe"
+-----------------------------------------------------
## Analyser toutes les recettes ! Naturellement, vous souhaitez exécuter l’analyse sur toutes les recettes que nous avons chargées.
Vous pouvez analyser une gamme d’identifiants de recettes de cette façon :
USER>do ##class(yummy.Utils).AnalyzeRange(1,10)
> Recipe 1 (1.755185s)
> Recipe 2 (2.559526s)
> Recipe 3 (1.556895s)
> Recipe 4 (1.720246s)
> Recipe 5 (1.689123s)
> Recipe 6 (2.404745s)
> Recipe 7 (1.538208s)
> Recipe 8 (1.33001s)
> Recipe 9 (1.49972s)
> Recipe 10 (1.425612s)
Après cela, regardez à nouveau votre tableau de recettes et vérifiez les résultats.
select * from yummy_data.Recipe
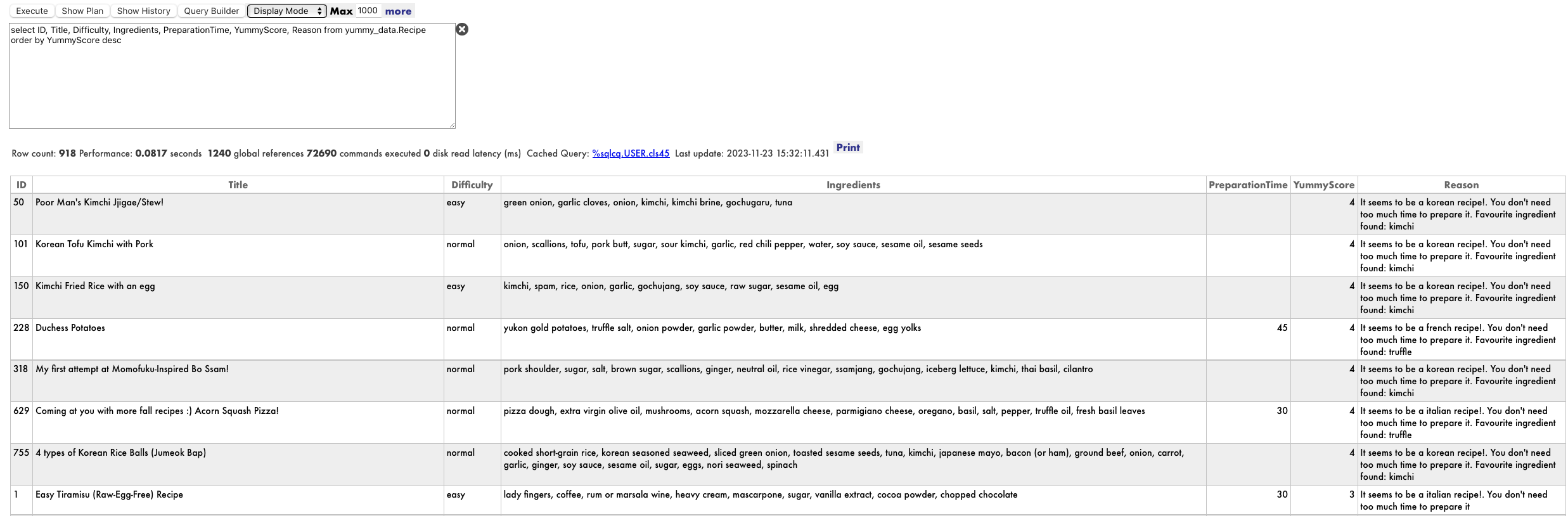
Je pense que je pourrais essayer la pizza à la courge poivrée ou le kimchi coréen au tofu et au porc :). De toute façon, je devrai vérifier à la maison :)
Notes finales
Vous pouvez trouver l'exemple complet sur https://github.com/isc-afuentes/recipe-inspector
Avec cet exemple simple, nous avons appris à utiliser les techniques LLM pour ajouter des fonctionnalités ou analyser certaines parties de vos données dans InterSystems IRIS.
Avec ce point de départ, vous pourriez penser à :
- Utiliser InterSystems BI pour explorer et parcourir vos données à l'aide de cubes et de tableaux de bord.
- Créer une application Web et fournir une interface utilisateur (par exemple Angular) pour cela, vous pouvez exploiter des packages tels que RESTForms2 pour générer automatiquement des API REST pour vos classes persistantes.
- Et pourquoi garder en base l'information indiquant les recettes que vous aimez et celles que vous n'aimez pas, puis d'essayer de déterminer si une nouvelle recette vous plaira ? Vous pourriez essayer une approche IntegratedML, ou même une approche LLM fournissant des exemples de données et construisant un cas d'utilisation RAG (Retrieval Augmented Generation).
Quelles autres choses pourriez-vous essayer ? Laissez-moi savoir ce que vous pensez!