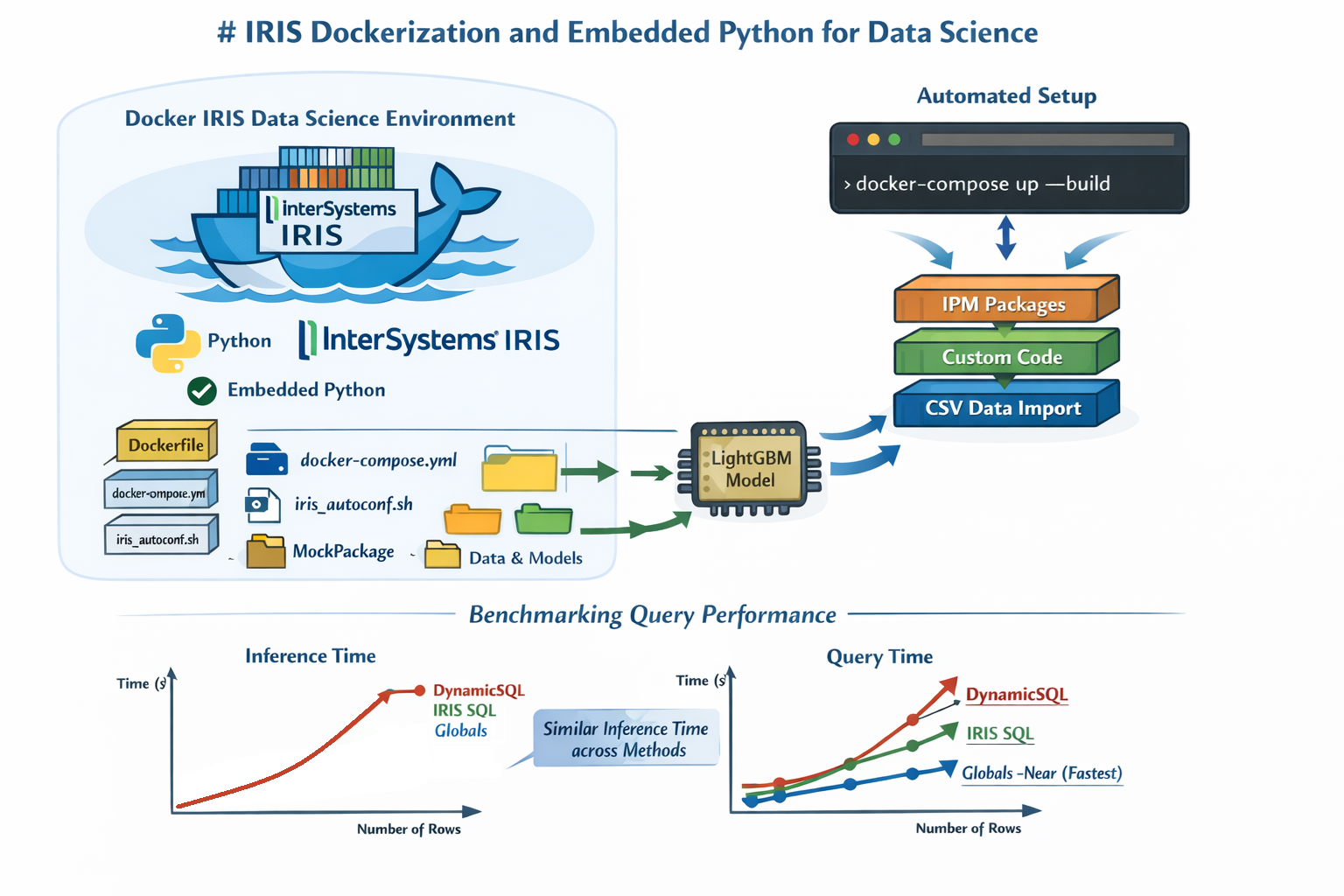
Dockerisation d'IRIS et Embedded Python pour la science des données — Configuration en une seule commande pour des flux de travail reproductibles en apprentissage automatique
Une seule commande suffit pour l'ensemble d'une instance IRIS dans le cadre de projets Data Science, ce qui permet de comparer la vitesse des différentes méthodes de requête (SQL dynamique, requête Pandas et Globales).
Avant de rejoindre InterSystems, j'ai travaillé au sein d'une équipe de développeurs web en tant que data scientist. La majeure partie de mon travail quotidien consistait à former et à intégrer des modèles d’apprentissage automatique dans des applications backend basées sur Python via des microservices, principalement développées au moyen du framework Django et à l’aide de Postgres SQL pour l’extraction des données. Au cours du développement, des tests et du déploiement, j’ai compris toute l’importance de la reproductibilité des résultats, tant pour les inférences du modèle que pour les performances au sein de l’application, quel que soit le matériel utilisé pour exécuter le code.
Ce processus s'est naturellement accompagné de l'adoption de bonnes pratiques de codage, telles que la modularisation pour réduire la répétitivité du code et les éléments standardisés, ce qui a facilité la maintenance et accéléré le développement. C'est pourquoi Docker, en particulier, est devenu un outil indispensable dans notre flux de travail, non seulement pour sa scalabilité et sa facilité de déploiement, mais aussi pour réduire les erreurs humaines et garantir une uniformité du code, quelle que soit la machine sous-jacente.
Dès mon arrivée chez InterSystems, j'ai été immédiatement impressionné par la robustesse d'InterSystems IRIS en tant que plateforme de données. Sa résilience face aux erreurs humaines lorsque l'on suit les directives pour créer des services en production, la nature multimodèle du stockage des informations et, en particulier, l'accès ultra-rapide aux données via les globales m'ont ouvert les yeux sur une nouvelle façon d'envisager les performances et les modèles d'accès aux données, surtout par rapport à une approche traditionnelle exclusivement relationnelle.
J'ai également eu la chance de rejoindre cette entreprise (en septembre 2025) à un moment où un riche écosystème d'outils était déjà en place, me permettant ainsi de réduire considérablement la courbe d'apprentissage. Je me suis rapidement habitué à utiliser quotidiennement les outils suivants : VS Code ObjectScript Extension Pack, Python intégré, les images officielles IRIS Docker et l'InterSystems Package Manager (IPM) pour importer facilement des paquets ObjectScript (https://github.com/intersystems/ipm).
Au bout d’environ trois mois, je me sentais suffisamment à l’aise avec cette pile technologique pour commencer à standardiser mon propre environnement de développement. Dans cet article, j’aimerais vous expliquer comment j’ai mis en place une instance IRIS entièrement conteneurisée pour des projets Data Science à l’aide de Docker — prête à être utilisée, avec Embedded Python intégré au moyen de pip de Python et de IPM.
Je vais également profiter de cette configuration pour vous donner un aperçu de la rapidité incroyable offerte par l'utilisation des globales dans les requêtes sur les tables, à travers un scénario pratique où le modèle de gradient boosting très répandu LightGBM est utilisé pour l'entraînement et l'inférence sur un ensemble de données simulé. Cela nous permettra de mesurer la vitesse d'inférence tout en comparant les différentes approches de requête disponibles dans IRIS.
Voici quelques aspects importants abordés dans cet article:
-
Les paquets Python personnalisés sont liés pendant le processus de compilation Docker, ce qui permet de les importer naturellement (par exemple,
from mypythonpackage import myclassorfunc) au sein de n'importe quelle méthode Python intégrée définie dans des classes ObjectScript, sans avoir à répéter le même code standard. -
Les commandes du terminal IRIS sont exécutées automatiquement dès le démarrage du conteneur ; dans ce scénario, elles sont utilisées pour :
- Importation de packages ObjectScript personnalisés dans IRIS.
- Installation d'IPM et, à travers celui-ci, de l'utilitaire
csvgenpyde Shavrov (https://community.intersystems.com/post/csvgenpy-import-any-csv-intersystems-iris-using-embedded-python), qui permet de créer et de remplir de nouvelles tables à l'aide d'un seul fichier CSV. - Pour vérifier la présence d'une table IRIS et, si ce n'est pas le cas, la remplir en utilisant
csvgenpyavec un fichier CSV monté dans le conteneur à travers les volumes Docker.
Et tout cela en exécutant simplement :
docker-compose up --build
Enfin, le référentiel joint à cet article utilise cette configuration pour créer un environnement IRIS complet, avec tous les outils et toutes les données nécessaires pour comparer différentes méthodes d'interrogation d'une même table IRIS et convertir les résultats au format Pandas DataFrame (basé sur NumPy), qui correspond généralement à ce qui est transmis aux modèles d'apprentissage automatique basés sur Python.
Cette comparaison porte sur :
- Les requêtes SQL dynamiques
- Les requêtes pandas s'adressant directement à la table
- L'accès direct via des globales
Pour chaque approche, le temps d'exécution est mesuré afin de comparer quantitativement les performances des différentes méthodes d'interrogation. Cette analyse montre que l'accès direct au niveau global fournit, de loin, la récupération de données avec la latence la plus faible pour les charges de travail d'inférence pour apprentissage automatique.
Parallèlement, la cohérence entre les différentes méthodes de requête est vérifiée en s'assurant que les Pandas DataFrames obtenues sont identiques, ce qui garantit la production de DataFrames identiques (et donc de prédictions d'apprentissage automatique identiques), quelle que soit la méthode de requête utilisée.
Structure du projet
.
├── docker-compose.yml # Configuration de l'orchestration Docker
├── dockerfile # Construction multi-étapes avec IRIS + Python
├── iris_autoconf.sh # Script de configuration automatique pour les commandes du terminal IRIS
├── requirements.txt # Bibliothèques Python
├── MockPackage/ # Package personnalisé
│ ├── MockDataManager.cls # Utilitaires de gestion des données
│ ├── MockModelManager.cls # Entraînement de modèles d'apprentissage automatique
│ └── MockInference.cls # Critères de référence pour la récupération de données et l'inférence
├── python_utils/ # Packages Python personnalisés
│ ├── __init__.py
│ ├── utils.py # Prétraitement et inférence en apprentissage automatique
| └── querymethods.py # Méthodes pour interroger les tables IRIS
└── dur/ # L'espace de stockage pour les données persistantes sur la machine hôte et le conteneur
├── data/ # Fichiers CSV
└── models/ # Modèles LightGBM entraînés
Dockerisation d'IRIS
Cette section décrit les principaux éléments nécessaires à la mise en conteneur (dockerisation) d'une instance IRIS compatible avec Python. L'objectif n'est pas seulement d'exécuter IRIS au sein d'un conteneur, mais de le faire en le rendant immédiatement opérationnel pour les workflows de Data Science : Python intégré, dépendances Python installées, packages ObjectScript disponibles via IPM et données chargées automatiquement au démarrage du conteneur.
La configuration s'appuie sur trois éléments principaux :
docker-compose.ymlpour définir la manière dont le conteneur IRIS est construit et exécuté- un fichier
Dockerfileen plusieurs étapes pour préparer Embedded Python et ses dépendances - un script
iris_autoconf.shpour automatiser la configuration côté IRIS au démarrage
docker-compose.yml
version: '3.8'
services:
iris:
build: # Conception de l'image
context: . # Chemin d'accès au répertoire contenant le fichier Dockerfile
dockerfile: Dockerfile # Nom du Dockerfile
container_name: iris-experimentation # Nom du conteneur
ports:
- "1972:1972" # Port du SuperServer
- "52773:52773" # Portail de gestion/Passerelle Web
volumes:
- ./dur/.:/dur:rw # Mappage du répertoire hôte au répertoire du conteneur avec des droits de lecture/écriture
restart: always # Redémarrage obligatoire du conteneur en cas d'arrêt (sauf s'il a été arrêté explicitement)
healthcheck:
test: ["CMD", "iris", "session", "iris", "-U", "%SYS", "##class(SYS.Database).GetMountedSize()"] # Commande health-check
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
command: --after "/usr/irissys/iris_autoconf.sh" # Exécution du script autoconf après le démarrage
Docker Compose définit la manière dont le conteneur IRIS est configuré, les ports accessibles, la gestion du stockage et les commandes exécutées au démarrage. Je tiens notamment à souligner les points suivants :
-
volumes: ./dur/.:/dur:rwAinsi, le répertoire
/durest créé à l'intérieur du conteneur et est mappé vers./dur(par rapport à l'emplacement du fichierdocker-compose.yml) sur la machine hôte, avec des droits de lecture/écriture.Dans la pratique, cela signifie que les deux éléments, la machine hôte et le conteneur, partagent le même chemin d'accès. Il est ainsi très facile de charger des fichiers dans IRIS et de les consulter ou de les modifier depuis la machine hôte sans avoir à effectuer de copiage supplémentaire.
Dans ce projet, c'est de cette manière que les dossiers
/dataet/modelssont directement accessibles à l'intérieur du conteneur sous/dur. -
command: --after "/usr/irissys/iris_autoconf.sh"Cette commande permet d'exécuter un script Bash dès que le conteneur est opérationnel. Ce script contient toutes les commandes nécessaires pour l'ouverture d'une session de terminal IRIS et effectuer toute configuration requise du côté d'IRIS
REMARQUE: Les commandes de ce script sont exécutées à chaque démarrage du conteneur. Cela signifie que si le conteneur s'arrête pour une raison quelconque et redémarre (par exemple, suite à la commande
restart: always), toutes les commandes de ce script seront réexécutées. Si ce comportement n'est pas pris en compte lors de la rédaction du script, cela peut entraîner des effets indésirables, tels que la réinstallation de packages ou la réinitialisation de tables.
dockerfile
# Étape 1 : Phase de préparation pour l'installation des dépendances
FROM python:3.12-slim AS builder
# Configuration du répertoire de travail
WORKDIR /app
# Copie du fichier de dépendances dans l'image
COPY requirements.txt requirements.txt
# Installation des dépendances Python dans un emplacement temporaire
RUN pip install --no-cache-dir --target /install -r requirements.txt
# Étape 2 : Image finale avec InterSystems IRIS et les bibliothèques Python installées
FROM containers.intersystems.com/intersystems/iris-community:latest-em
# Passage à l'utilisateur root pour installer les packages système nécessaires
USER root
# Installation de la bibliothèque de développement Python 3.12 adaptée à Ubuntu Noble
RUN apt-get update && apt-get install -y libpython3.12-dev wget && \
rm -rf /var/lib/apt/lists/*
# Configuration des variables d'environnement pour Embedded Python
ENV PythonRuntimeLibrary=/usr/lib/x86_64-linux-gnu/libpython3.12.so
ENV PythonRuntimeLibraryVersion=3.12
# Mise à jour de LD_LIBRARY_PATH
ENV LD_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu:${LD_LIBRARY_PATH}
# Copie des packages Python installés depuis l'étape de compilation
COPY --from=builder /install /usr/irissys/mgr/python
# Votre package Python
COPY python_utils /usr/irissys/mgr/python/python_utils
ENV PYTHONPATH=/usr/irissys/mgr/python:${PYTHONPATH}
# Copie des classes ObjectScript dans l'image
COPY MockPackage /usr/irissys/mgr/MockPackage
# Copie et définition des autorisations pour le script autoconf tout en restant root
COPY iris_autoconf.sh /usr/irissys/iris_autoconf.sh
RUN chmod +x /usr/irissys/iris_autoconf.sh
# Retour à l'utilisateur par défaut `irisowner`
USER irisowner
Il s'agit d'un fichier Dockerfile en deux étapes.
L'étape initiale est une étape de compilation allégée qui sert à installer toutes les dépendances Python répertoriées dans le fichier requirements.txt dans un répertoire temporaire. Cela permet de préserver la propreté de l'image finale et d'éviter d'installer les outils de compilation directement dans l'image IRIS.
La deuxième étape s'appuie sur l'image officielle InterSystems IRIS. À ce stade, la bibliothèque d'exécution Python requise pour Embedded Python est installée, et IRIS est configuré de manière à ce qu'Embedded Python puisse reconnaître les deux éléments : la bibliothèque d'exécution et tous les packages Python installés, y compris ceux personnalisés.
Il convient de souligner la configuration suivante :
-
Configuration d'exécution d'Embedded Python
ENV PythonRuntimeLibrary=/usr/lib/x86_64-linux-gnu/libpython3.12.so ENV PythonRuntimeLibraryVersion=3.12
Ces variables d'environnement permettent d'effectuer des opérations qui, autrement, devraient être configurées manuellement via le portail de gestion (Management Portal) en accédant à :
System Administration → Configuration → Additional Settings → Advanced Memory
et de mettre à jour les paramètres d'exécution d'Embedded Python. Le fait de les définir dans le fichier Dockerfile rend la configuration explicite, reproductible et versionnée.
De plus, les classes contenues dans le package « MockPackage » sont copiées dans le conteneur via :
COPY MockPackage /usr/irissys/mgr/MockPackage
pour être ensuite importées automatiquement dans IRIS lorsque le fichier Bash ci-dessous est exécuté après le démarrage et la mise en service du conteneur.
iris_autoconf.sh
#!/bin/bash
set -e
iris session IRIS <<'EOF'
/* Installez le client IPM/ZPM si vous en avez encore besoin au préalable
(votre snippet d'origine a déjà effectué cette opération) */
s version="latest" s r=##class(%Net.HttpRequest).%New(),r.Server="pm.community.intersystems.com",r.SSLConfiguration="ISC.FeatureTracker.SSL.Config" d r.Get("/packages/zpm/"_version_"/installer"),$system.OBJ.LoadStream(r.HttpResponse.Data,"c")
/* Configuration du registre */
zpm
repo -r -n registry -url https://pm.community.intersystems.com/ -user "" -pass ""
install csvgenpy
quit
/* Importation et compilation du MockPackage */
/* Les indicateurs « ck » permettent de compiler et de conserver le code source */
Do $system.OBJ.Import("/usr/irissys/mgr/MockPackage", "ck")
/* Importation automatique de données CSV dans une table à l'aide de csvgenpy */
SET exists = ##class(%SYSTEM.SQL.Schema).TableExists("MockPackage.NoShowsAppointments")
IF 'exists { do ##class(shvarov.csvgenpy.csv).Generate("/dur/data/healthcare_noshows_appointments.csv","NoShowsAppointments","MockPackage") }
halt
EOF
Il s'agit d'un script Bash qui s'exécute à l'intérieur du conteneur immédiatement après son démarrage. Il ouvre une session de terminal IRIS à l'aide de la commande iris session IRIS et exécute des commandes spécifiques à IRIS afin d'effectuer automatiquement des étapes de configuration supplémentaires.
Ces étapes comprennent l'importation de paquets personnalisés dont les classes ont été copiées dans les espaces de stockage du conteneur, l'installation d'IPM (disponible sous le nom de zpm dans le terminal IRIS), l'installation de progiciels IPM tels que csvgenpy, et l'utilisation à l'aide de csvgenpy pour charger un fichier CSV monté dans le conteneur à l'emplacement /dur/data/healthcare_noshows_appointments.csv afin de créer et de remplir une table correspondante dans IRIS.
REMARQUE: Ce script est exécuté à chaque démarrage du conteneur. Sans cette précaution, cela peut entraîner des effets indésirables, tels que le rechargement ou la réinitialisation des données. Il est donc important de s'assurer que le script peut être exécuté à plusieurs reprises en toute sécurité, par exemple en vérifiant si la table cible existe déjà avant de la créer ou de la remplir. Cela est particulièrement important ici, car la stratégie de redémarrage de Docker Compose est définie sur restart: always, ce qui signifie que le conteneur redémarrera automatiquement et réexécutera ces commandes à chaque arrêt.
Packages pour l'analyse comparative
Cette section présente les paquets ObjectScript utilisés dans IRIS pour comparer différentes stratégies d'accès aux données dans le cadre d'une charge de travail d'inférence en apprentissage automatique. Elle ne se concentre pas ici sur la qualité du modèle, mais sur la mesure et la comparaison du temps nécessaire pour extraire des données d'IRIS, les convertir en un Pandas DataFrame et exécuter l'inférence à l'aide d'un modèle LightGBM entraîné.
Dans ce processus, chaque classe joue un rôle spécifique, depuis la préparation des données jusqu'à l'entraînement du modèle, puis à l'inférence et à la comparaison des performances.
MockDataManager.cls
Cette classe contient des méthodes qui permettent de prendre un fichier CSV donné et de dupliquer ses lignes afin d'atteindre la taille souhaitée pour l'ensemble de données (AdjustDataSize), ainsi que de mettre à jour une table IRIS donnée à l'aide du fichier CSV spécifié (UpdateTableFromCSV). L'objectif principal de ces utilitaires est de permettre de tester, de manière contrôlée, les temps d'exécution des requêtes et d'inférence pour des tables de différentes tailles.
Remarque: Tout au long de cette analyse, nous nous concentrons exclusivement sur le temps d'inférence d'un modèle LightGBM. À cette étape, nous ne nous intéressons pas aux indicateurs de performance du modèle tels que le score F1, la précision, le rappel, l'exactitude ou autres.
MockModelManager.cls
Dans cette classe, la seule méthode pertinente est TrainNoShowsModel. Cette méthode utilise le pipeline de traitement des données défini dans python_utils.utils pour préparer les données brutes transmises sous forme de Pandas DataFrame, ajuster un modèle LightGBM et enregistrer le modèle entraîné sur le disque.
Le modèle est enregistré à un emplacement prédéfini, lequel correspond, dans cette configuration, au stockage persistant monté via des volumes Docker dans docker-compose.yml. Cela permet de réutiliser le modèle entraîné lors des redémarrages de conteneurs et des exécutions d'inférence sans avoir à le réentraîner.
MockInference.cls
Le noyau de la comparaison des performances réside dans cette classe. Le processus commence par le chargement des poids du modèle LightGBM entraîné à partir du chemin d'accès spécifié dans le paramètre MODELPATH. Bien que ce chemin soit actuellement codé en dur, il sert de point de référence statique commun à tous les tests d'inférence.
RunInferenceWDynamicSQL représente la première approche. Cette méthode s'appuie sur une méthode ObjectScript appelée DynamicSQL, qui exécute une instruction SQL dynamique pour filtrer les enregistrements en fonction de leur âge. Les résultats sont regroupés dans un %DynamicArray de %DynamicObjects. Cette méthode est ensuite appelée par la fonction Python dynamic_sql_query dans python_utils/querymethods.py, où les objets IRIS sont convertis en une structure pouvant être facilement transformée en un Pandas DataFrame.
L'ensemble du flux de travail, y compris la mesure du temps d'exécution via un décorateur Python défini dans python_utils/utils.py, est orchestré au sein de RunInferenceWDynamicSQL. Le DataFrame obtenu est ensuite transmis au pipeline d'inférence afin de générer des prédictions et de mesurer la latence de l'inférence tout au long du processus.
RunInferenceWIRISSQL suit une approche plus simple. Il utilise la méthode iris_sql_query de python_utils/querymethods.py pour exécuter la requête SQL directement depuis Python. L'itérateur IRIS SQL obtenu est converti directement en un Pandas DataFrame, après quoi la même logique d'inférence et d'horodatage appliquée dans la méthode précédente est mise en œuvre.
RunInferenceWGLobals constitue l'approche la plus directe, car elle interroge les structures de données sous-jacentes (globales) sous-tendant le tableau. Cette approche utilise la méthode iris_global_query pour récupérer directement les données depuis ^vCVc.Dvei.1. Cette variable globale particulière a été identifiée comme étant le DataLocation dans la définition de stockage de la table MockPackage.NoShowsAppointments.
The global name is a result of the hashed storage automatically generated when the table was built from the CSV fileLe nom de la globale provient du stockage haché généré automatiquement lors de la création de la table à partir du fichier CSV.
Enfin, l'intégrité des trois approches est vérifiée à l'aide de la méthode ConsistencyCheck. Cet utilitaire vérifie que les Pandas DataFrames générés par chaque stratégie de requête soient identiques, afin de garantir que les types de données, les valeurs et la précision numérique restent parfaitement cohérents, quelle que soit la méthode d'accès utilisée.
Comme cette vérification ne génère aucune erreur, elle confirme que le SQL dynamique, l'accès direct au SQL depuis Python et l'accès rapide au niveau global renvoient le même ensemble de données.
Comparaison des performances
Afin d'évaluer les performances, nous avons mesuré les temps de requête et d'inférence pour des tables de taille croissante et présentons le temps moyen sur 10 exécutions pour chaque configuration dans la table ci-dessous. Le temps de requête correspond à la récupération des données depuis la base de données, tandis que le temps d'inférence correspond à l'exécution du modèle LightGBM sur l'ensemble de données obtenu.
| Lignes | DynamicSQL – Requête | DynamicSQL – Infér | IRISSQL – Requête | IRISSQL – Infér | Globales – Requête | Globales – Infér |
|---|---|---|---|---|---|---|
| 100 | 0.003219271 | 0.042354488 | 0.001749706 | 0.043090796 | 0.001184559 | 0.043616056 |
| 1,000 | 0.031865168 | 0.052698898 | 0.019246697 | 0.056159472 | 0.005061340 | 0.045210719 |
| 10,000 | 0.237553477 | 0.082497978 | 0.099582171 | 0.068728352 | 0.036206818 | 0.061128354 |
| 100,000 | 5.279174852 | 0.189197206 | 1.122253346 | 0.177564192 | 0.535172153 | 0.175085044 |
| 500,000 | 68.741133046 | 0.639807224 | 7.015313649 | 0.610818386 | 2.743980526 | 0.587647438 |
| 1,000,000 | 196.871173100 | 1.145034313 | 22.138613220 | 1.136569023 | 5.987578392 | 1.106307745 |
| 2,000,000 | 711.319680452 | 3.021180152 | 60.142974615 | 2.879153728 | 11.92040014 | 2.728573560 |
Nous avons appliqué un algorithme de régression exponentielle afin de caractériser l'évolution des temps de requête et d'inférence par rapport à la taille des tables:

Durée de l'inférence
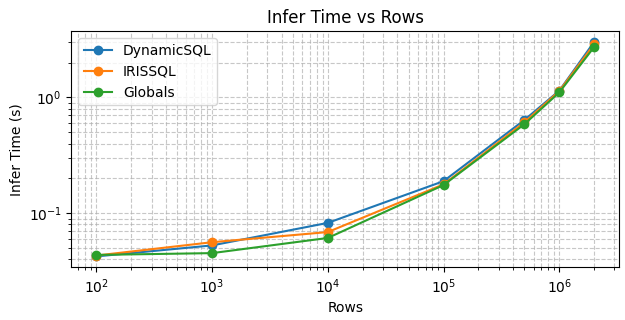

La durée d'inférence est pratiquement identique pour les trois méthodes de requête, ce qui n'est pas surprenant, car le DataFrame d'entrée obtenu s'est avéré identique dans tous les cas.
D'après les mesures, le modèle est capable d'effectuer une inférence sur environ 1 million de lignes en environ 1 seconde, ce qui met en évidence le débit élevé de LightGBM.
L'exposant ajusté (k ≈ 1,3) indique une évolution légèrement superlinéaire de la durée totale d'inférence par rapport au nombre de lignes. Ce comportement est couramment observé dans le traitement par lots à grande échelle et est probablement attribuable à des effets au niveau du système, tels que la pression sur le cache ou la saturation de la bande passante mémoire, plutôt qu'à la complexité algorithmique du modèle lui-même.
Le facteur d'échelle « a » est de l'ordre de quelques dizaines de nanosecondes, ce qui reflète l'efficacité du calcul par ligne. Si l'exposant superlinéaire implique que le coût marginal par ligne supplémentaire augmente avec la taille de la table, cet effet ne devient perceptible qu'à grande échelle (des millions de lignes), comme l'illustre la pente croissante du graphe log-log.
Le coût marginal d'inférence peut être estimé à partir de la dérivée du modèle ajusté :
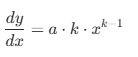
L'évaluation de cette expression montre que le temps d'inférence marginal par ligne passe d'environ 1,9e-7 seconde pour 1 000 lignes à 1,5e-6 seconde pour 1 million de lignes, restant ainsi résolument dans l'ordre microseconde dans le régime de données observé.
Enfin, le décalage constant (c ~ 0.08) ajusté en secondes représente probablement une surcharge d'inférence fixe, telle que l'invocation du modèle et l'initialisation à l'exécution, et doit être interprété comme un coût constant indépendant de la taille de la tabl.
Durée de la requête
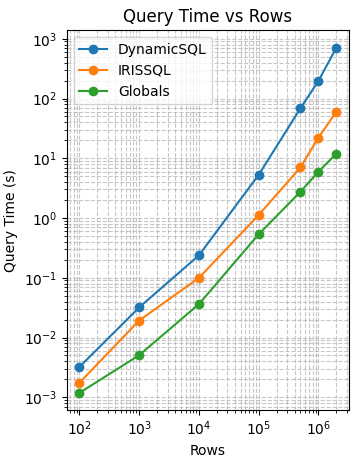

La durée des requêtes présente un comportement d'évolutivité très différent selon les trois méthodes d'accès. Contrairement à la durée des inférences, qui est largement indépendante du mécanisme de requête, les performances des requêtes dépendent principalement de la stratégie d'accès aux données et de son interaction avec les couches de stockage et d'exécution.
L'approche basée sur les globales présente une évolutivité quasi linéaire (k ≈ 1,03), ce qui indique que le coût de récupération de chaque ligne supplémentaire reste approximativement constant sur toute la plage mesurée. Ce comportement est conforme aux modèles d'accès séquentiels et à une surcharge minimale de planification des requêtes, rendant les globales l'option la plus évolutive pour les grands ensembles de résultats.
L'approche IRISSQL présente une évolutivité modérément superlinéaire (k ≈ 1,48). Bien qu'elle reste efficace pour des tables de taille modérée, l'augmentation du coût marginal suggère une surcharge croissante liée à l'exécution SQL, à la planification des requêtes ou à la matérialisation des résultats intermédiaires au fur et à mesure que le nombre de lignes augmente.
L'approche DynamicSQL présente la scalabilité superlinéaire la plus prononcée (k ~ 1,82), ce qui entraîne une augmentation rapide de la durée des requêtes à plus grande échelle. Ce comportement explique la pente raide observée sur le graphique et indique que DynamicSQL engendre une surcharge supplémentaire significative lorsque la taille des résultats augmente, ce qui en fait la méthode la moins évolutive pour les requêtes par lots de grande taille.
Bien que les facteurs d'échelle ajustés « a » soient numériquement faibles, ils doivent être interprétés au moyen de l'exposant « k ». En pratique, l'exposant domine le comportement asymptotique, ce qui explique pourquoi DynamicSQL, malgré un « a » faible, devient nettement plus lent lorsque la taille des tables est importante.
Le terme constant ajusté « c » représente la surcharge fixe de la requête. Pour IRISSQL, « c » tend vers zéro, ce qui indique un faible coût de démarrage. Cette surcharge est encore plus faible pour l’approche basée sur les Globals, où la valeur ajustée est légèrement négative, ce qui suggère en fait un coût fixe nul. Ce comportement est attendu, car la récupération des données via une clé globale s’effectue directement, sans surcharge supplémentaire liée à la planification ou à l’exécution de la requête.
En revanche, le décalage constant relativement important observé pour DynamicSQL indique une surcharge fixe substantielle, probablement liée à la préparation de la requête ou à la configuration de l'exécution. Ce coût fixe pénalise les performances quelle que soit la taille des tables et devient particulièrement préjudiciable pour les deux échelles.
De manière générale, ces résultats soulignent que la durée des requêtes, contrairement à celle des inférences, est très sensible à la méthode d'accès aux données : la méthode Globals offre une évolutivité quasi linéaire, la méthode IRISSQL fournit un juste milieu équilibré, tandis que la méthode DynamicSQL présente une faible évolutivité pour les grands ensembles de résultats.
Veuillez vous reporter au référentiel suivant pour plus de details :
https://github.com/JorgeIvanJH/IRIS_dockerization.git
Video de démonstration:
Si vous avez des questions ou si vous remarquez des erreurs, n'hésitez pas à nous contacter.
Merci!