Présentation des fonctions de fenêtre SQL (3ème partie)
Dans cette dernière partie de notre présentation des fonctions de fenêtre, nous allons explorer les fonctions restantes qui n'ont pas encore été abordées. Vous découvrirez également des conseils de performance et un guide pratique pour vous aider à décider quand il convient (ou non) d'utiliser efficacement les fonctions de fenêtre.
1. Fonctions de valeur de décalage et de position
Aperçu
Les valeurs de référence de ces fonctions sont calculées à partir d'autres lignes par rapport à la ligne actuelle, ou elles sont extraites des première, dernière ou n-ième valeurs dans une fenêtre.
- LAG(colonne, décalage, par défaut) — récupère la valeur de décalage de la ligne précédente.
- LEAD(colonne, décalage, par défaut) — recouvre la valeur de décalage des lignes suivantes.
- FIRST_VALUE(colonne) — renvoie la première valeur dans la fenêtre.
- LAST_VALUE(colonne) — renvoie la dernière valeur dans la fenêtre.
- NTH_VALUE(colonne, n) — renvoie la n-ième valeur dans la fenêtre.
Toutes ces fonctions sont essentielles pour comparer la ligne actuelle à d'autres lignes de la même séquence.
Exemple 1 — Évolution du taux de cholestérol des patients
Analysons l'évolution du taux de cholestérol de chaque patient au fil de plusieurs rendez-vous.
CREATE TABLE LabResults (
PatientID INTEGER,
VisitDate DATE,
Cholesterol INTEGER
)
INSERT INTO LabResults
SELECT 1,'2024-01-10',180 UNION ALL
SELECT 1,'2024-02-15',195 UNION ALL
SELECT 1,'2024-03-20',210 UNION ALL
SELECT 2,'2024-01-12',160 UNION ALL
SELECT 2,'2024-03-10',155 UNION ALL
SELECT 2,'2024-04-15',165
Il faut:
- Utiliser LAG() pour récupérer la valeur précédente du cholestérol de chaque patient.
- Calculer la variation du cholestérol entre les rendez-vous (Delta).
- Utiliser FIRST_VALUE() pour saisir taux initiaux de cholestérol de chaque patient.
- Calculer la variation en pourcentage par rapport à la valeur de référence au moyen de PercentChange.
- Trier le résultat final par PatientID et VisitDate.
SELECT
PatientID,
VisitDate,
Cholesterol,
LAG(Cholesterol) OVER (PARTITION BY PatientID ORDER BY VisitDate) AS PrevValue,
Cholesterol - LAG(Cholesterol) OVER (PARTITION BY PatientID ORDER BY VisitDate) AS Delta,
FIRST_VALUE(Cholesterol) OVER (PARTITION BY PatientID ORDER BY VisitDate) AS Baseline,
ROUND(
100.0 * Cholesterol /
FIRST_VALUE(Cholesterol) OVER (PARTITION BY PatientID ORDER BY VisitDate), 2
) AS PercentChange
FROM LabResults
ORDER BY PatientID, VisitDate
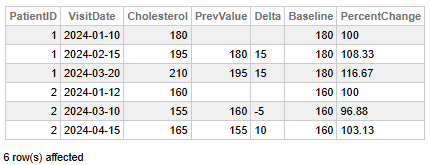 Fig 1 - Évolution du taux de cholestérol des patients
Fig 1 - Évolution du taux de cholestérol des patients
Ces données nous permettent de tirer les conclusions principales suivantes:
- Le patient 1 présente une tendance à la hausse constante : son taux de cholestérol est passé de 180 à 210 au cours des trois visites, au moyen d’une augmentation de 15 unités à chaque visite et d’une variation cumulative de +16,67 % par rapport à la valeur initiale.
- Le patient 2 présente une tendance fluctuante : baisse initiale de 160 à 155 (-5 unités, -3,13 %), suivie d'un rebond à 165 (+10 unités, +6,25 %), ce qui se traduit par une augmentation nette de +3,13 % par rapport à la valeur initiale.
- Le cholestérol du patient 1 a augmenté de manière constante, ce qui suggère un changement progressif justifiant une surveillance ou une intervention.
- Le cholestérol du patient 2 a varié mais est resté proche de la valeur initiale, indiquant des niveaux moins constants mais relativement stables.
👉 Pourquoi est-ce utile: La détection des tendances ou des changements brusques dans les résultats des tests de laboratoire des patients est idéale pour surveiller les maladies chroniques ou l'efficacité des traitements.
Exemple 2 — Analyse des tendances des stocks avec aperçu et références historiques
Analysons l'évolution de l'historique des stocks de chaque produit en comparant le stock actuel au stock prévu pour la journée suivante (à l'aide de LEAD) afin de calculer la consommation quotidienne et de définir un seuil de réapprovisionnement historique basé sur le stock de trois jours auparavant (à l'aide de NTH_VALUE).
CREATE TABLE InventoryLog (
LogDate DATE,
ProductID VARCHAR(10),
InventoryCount INT
)
INSERT INTO InventoryLog (LogDate, ProductID, InventoryCount)
SELECT '2025-11-01', 'A101', 500 UNION ALL
SELECT '2025-11-02', 'A101', 480 UNION ALL
SELECT '2025-11-03', 'A101', 450 UNION ALL
SELECT '2025-11-04', 'A101', 400 UNION ALL
SELECT '2025-11-05', 'A101', 350 UNION ALL
SELECT '2025-11-06', 'A101', 300 UNION ALL
SELECT '2025-11-07', 'A101', 250 UNION ALL
SELECT '2025-11-08', 'A101', 200 UNION ALL
SELECT '2025-11-01', 'B202', 120 UNION ALL
SELECT '2025-11-02', 'B202', 115 UNION ALL
SELECT '2025-11-03', 'B202', 110 UNION ALL
SELECT '2025-11-04', 'B202', 100
Il faut:
- Récupérez le nombre de stocks de la date de journalisation chronologique suivante à l'aide de
LEAD(InventoryCount, 1). - Calculez la consommation quotidienne en soustrayant le nombre d'unités en stock
LEADdu nombre d'unités en stock actuelInventoryCount. - Utilisez
NTH_VALUE(InventoryCount, 3)à l'aide de la fenêtre définie entre le début et la ligne actuelle (ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) pour récupérer le nombre d'unités en stock à partir du troisième jour enregistré.
SELECT
LogDate,
ProductID,
InventoryCount AS Current_Stock,
LEAD(InventoryCount, 1) OVER (
PARTITION BY ProductID
ORDER BY LogDate
) AS Next_Day_Stock,
InventoryCount - LEAD(InventoryCount, 1) OVER (
PARTITION BY ProductID
ORDER BY LogDate
) AS Daily_Usage,
NTH_VALUE(InventoryCount, 3) OVER (
PARTITION BY ProductID
ORDER BY LogDate
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS Stock_Three_Days_Ago_Threshold
FROM
InventoryLog
ORDER BY
ProductID, LogDate;
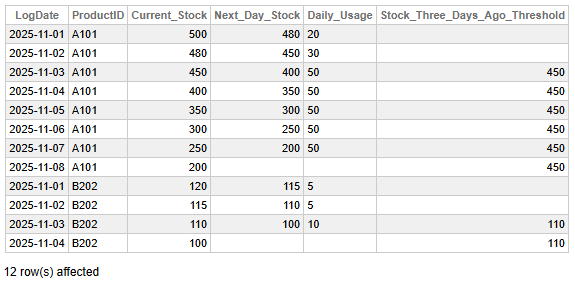 Fig 2 - Analyse des tendances des stocks avec aperçu et références historiques
Fig 2 - Analyse des tendances des stocks avec aperçu et références historiques
Ces données nous permettent de tirer les conclusions principales suivantes:
- L'utilisation quotidienne du produit A101 a d'abord augmenté de 20 unités à 30 unités, puis s'est stabilisée à 50 unités par jour entre le 3 et le 7 novembre.
- Pour les points de données où la fenêtre a au moins trois lignes (à partir du 03/11/2025), le seuil de réapprovisionnement est fixé au niveau des stocks de trois jours auparavant.
- Au 05/11/2025, le stock actuel de 350 unités pour le produit A101 est nettement inférieur au niveau historique de référence de 450 unités, ce qui indique un besoin potentiel de réapprovisionnement dans un avenir proche.
👉 Pourquoi est-ce utile: The LEAD() function provides future context by showing the subsequent value in a time series, which is essential for calculating rates of change (e.g., daily usage). The NTH_VALUE() function allows analysts to establish dynamic, indexed benchmarks within a rolling window (e.g., comparing the current value against the value from the start of the week or a specific historical point) for proactive decision-making.
2. Fonctions de fenêtre mobile et cumulative
Overview
Ces fonctions utilisent des clauses d'intervalle explicites (ROWS BETWEEN ...) pour calculer des métriques sur un sous-ensemble glissant ou cumulatif de lignes.
Agrégats typiques:
- SUM() ou AVG() pour les totaux ou les moyennes mobiles.
- Toute fonction d'agrégation peut opérer à l'aide d'intervalles limités ou illimités.
Syntaxe typique:
SUM(value) OVER (
PARTITION BY ...
ORDER BY ...
ROWS BETWEEN n PRECEDING AND CURRENT ROW
)
Exemple 1 — Soldes des comptes mobiles
Analysons comment évolue l'historique des transactions de chaque compte à l'aide de métriques mobiles et cumulatives.
CREATE TABLE Transactions (
AccountID INTEGER,
TxDate DATE,
Amount INTEGER
)
INSERT INTO Transactions
SELECT 1001,'2024-01-01',100 UNION ALL
SELECT 1001,'2024-01-05',250 UNION ALL
SELECT 1001,'2024-01-07',150 UNION ALL
SELECT 1001,'2024-01-10',300 UNION ALL
SELECT 1002,'2024-01-02',500 UNION ALL
SELECT 1002,'2024-01-06',400 UNION ALL
SELECT 1002,'2024-01-09',600
Nous devons accomplir les prochaines étapes:
- Utiliser SUM() dans la fenêtre ROWS BETWEEN 2 PRECEDING AND CURRENT ROW à l'aide de laquelle on calcule une somme mobile sur 3 transactions (MovingSum).
- Calculer une moyenne mobile (RunningAvg) à l'aide de AVG() avec ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW à partir du début de l'historique de chaque compte.
- Partitionner par AccountID et trier par TxDate pour suivre les soldes par ordre chronologique.
- Afficher toutes les transactions avec les métriques calculées ci-dessus.
SELECT
AccountID,
TxDate,
Amount,
SUM(Amount) OVER (
PARTITION BY AccountID
ORDER BY TxDate
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS MovingSum,
AVG(Amount) OVER (
PARTITION BY AccountID
ORDER BY TxDate
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS RunningAvg
FROM Transactions
ORDER BY AccountID, TxDate
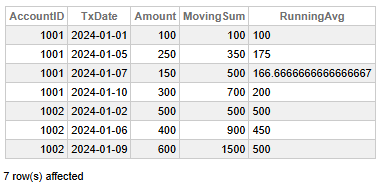 Fig 3 - Soldes des comptes mobiles
Fig 3 - Soldes des comptes mobiles
Ces données nous permettent de tirer les conclusions principales suivantes:
- Le compte 1001 affiche une augmentation régulière des montants des transactions au fil du temps, avec un MovingSum total de 700 et un RunningAvg final de 200, ce qui indique une activité croissante et une tendance à la hausse constante.
- Le compte 1002 a des valeurs de transaction généralement plus élevées, atteignant un MovingSum de 1500 et maintenant un RunningAvg stable de 500, ce qui suggère des transactions plus importantes mais plus équilibrées.
- Le compte 1002 contribue davantage au volume total malgré un nombre de transactions moins important, ce qui souligne sa valeur plus élevée par transaction.
👉 Pourquoi est-ce utile: Cette méthode réduit les fluctuations et permet de visualiser clairement les tendances des transactions, ce qui est idéal pour le suivi financier et les prévisions.
Exemple 2 — Moyenne mobile des cas de COVID
Suivons l'évolution du nombre quotidien de cas de COVID dans les différentes régions à l'aide d'une moyenne mobile afin de réduire les fluctuations à court terme.
CREATE TABLE CovidStats (
Region VARCHAR(50),
ReportDate DATE,
Cases INTEGER
)
INSERT INTO CovidStats
SELECT 'North','2024-01-01',12 UNION ALL
SELECT 'North','2024-01-02',15 UNION ALL
SELECT 'North','2024-01-03',20 UNION ALL
SELECT 'North','2024-01-04',18 UNION ALL
SELECT 'North','2024-01-05',25 UNION ALL
SELECT 'South','2024-01-01',10 UNION ALL
SELECT 'South','2024-01-02',11 UNION ALL
SELECT 'South','2024-01-03',13 UNION ALL
SELECT 'South','2024-01-04',15
Nous devons accomplir les prochaines étapes:
- Pour calculer la moyenne mobile sur 3 jours des cas de COVID, il faut utiliser AVG() dans une fenêtre ROWS BETWEEN 2 PRECEDING AND CURRENT ROW.
- Il faut ensuite partitionner par Region (région) et trier par DateRapport pour calculer les tendances indépendamment pour chaque région.
- Il faut enfin afficher tous les nombres de cas quotidiens avec leurs moyennes mobiles correspondantes.
SELECT
Region,
ReportDate,
Cases,
AVG(Cases) OVER (
PARTITION BY Region
ORDER BY ReportDate
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS Moving3DayAvg
FROM CovidStats
ORDER BY Region, ReportDate
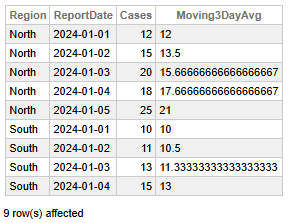 Fig 4 - Moyenne mobile des cas de COVID
Fig 4 - Moyenne mobile des cas de COVID
Ces données nous permettent de tirer les conclusions principales suivantes:
- La région Nord affiche une nette tendance à la hausse du nombre de cas quotidiens, qui est passé de 12 à 25 en cinq jours, la moyenne mobile sur trois jours augmentant régulièrement de 12 à 21.
- La région Sud affiche une augmentation modérée, le nombre de cas passant de 10 à 15 et la moyenne mobile sur trois jours passant de 10 à 13.
- Les valeurs moyennes mobiles sur trois jours plus élevées dans le Nord (avec un pic à 21) indiquent une croissance plus rapide et plus intense des cas par rapport au Sud.
- La progression des cas est plus marquée dans le Nord, ce qui suggère la nécessité d'une surveillance ou d'une intervention plus étroite, contrairement au Sud.
👉 Pourquoi est-ce utile: Cette méthode fournit une tendance claire des augmentations ou des baisses au fil du temps, ce qui la rend idéale pour la surveillance et les prévisions en matière de santé publique.
3. Conseils pour améliorer les performances et l'optimisation
- Spécifiez le cadre de la fenêtre : pour les fonctions d'agrégation (par exemple, SUM()), utilisez le plus petit cadre possible (par exemple, ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) à l'aide de ce cadre pour réduire la charge de calcul par ligne.
- Limitez les données dès le début : appliquez les clauses WHERE dans une CTE ou une sous-requête avant l'exécution de la fonction de fenêtre. Cela réduit le nombre de lignes à traiter par la fonction.
- Maintenez les statistiques : exécutez régulièrement TUNE TABLE pour maintenir les statistiques à jour, afin de garantir que l'optimiseur de requêtes sélectionne le plan d'exécution optimal (par exemple, en utilisant vos index).
- Analysez le plan : utilisez toujours EXPLAIN afin de confirmer que l'optimiseur utilise un index pour la phase de tri plutôt que d'effectuer un tri complet.
- Choisissez des fonctions plus simples : optez pour ROW_NUMBER() plutôt que RANK() ou DENSE_RANK() lorsque les liens n'ont pas d'importance, car cette fonction est généralement plus rapide.
- Utilisez les index existants : vérifiez si un index existant satisfait déjà aux exigences PARTITION BY et ORDER BY avant de créer un nouveau.
- Envisagez de créer un index "POC lorsque les index existants sont insuffisants dans le cas où il y a besoin d'un index. Un index POC est un index qui couvre explicitement les colonnes dans l'ordre suivant : Partitionnement (PARTITION BY), Ordre (ORDER BY) et Couverture des colonnes (toutes les autres colonnes référencées dans la fonction de fenêtre ou la liste de sélection). Il élimine le tri coûteux des tables (1, 2).
4. Quand utiliser les fonctions de fenêtre — et quand ne pas les utiliser
| ✅ Quand utiliser les fonctions de fenêtre | ❌ Quand NE PAS utiliser les fonctions de fenêtre |
|---|---|
| Calcul des totaux cumulés ou des distributions cumulées. (par exemple, somme cumulée des ventes au fil du temps). | Opérations simples au niveau des lignes. Si vous avez simplement besoin de calculer une valeur basée sur les colonnes de la ligne actuelle (par exemple, column_A * column_B), une arithmétique standard suffit. |
| Classement des lignes dans un groupe. (par exemple, trouver les 5 meilleurs élèves de chaque classe à l'aide des fonctions RANK(), DENSE_RANK() ou ROW_NUMBER()). | Filtrage/agrégation de l'ensemble complet des données en une seule ligne par groupe. Appliquez la norme GROUP BY pour résumer les données (par exemple, le total des ventes par an). |
| Calcul des moyennes mobiles ou autres calculs de fenêtre mobile. Definition d'un cadre spécifique (par exemple, la moyenne des ventes des 3 derniers jours). | Vous devez réduire le nombre de lignes renvoyées. Les fonctions de fenêtre calculent des valeurs, mais ne filtrent pas implicitement les lignes. Lorsque vous devez limiter les résultats, utilisez WHERE ou une sous-requête/CTE avec la fonction de fenêtre. |
| Comparaison d'une ligne à une ligne précédente ou suivante. (par exemple, calcul de la variation quotidienne du cours de l'action avec LAG() ou LEAD()). | Le calcul peut être effectué plus facilement et plus clairement avec une instruction JOIN ou une simple instruction CASE, qui est plus efficace pour les recherches particulières et simples. |
| Calcul des percentiles/quartiles ou d'autres mesures de distribution. (Par exemple, recherche du salaire médian au moyen de NTILE() ou PERCENT_RANK()). | Travail avec des ensembles de données volumineux et non indexés où les performances sont essentielles, et où une requête GROUP BY plus simple permettrait d'atteindre l'objectif plus rapidement (bien que cela soit de plus en plus rare avec les optimiseurs de bases de données modernes). |
5. Conclusions
Alors que nous terminons cette présentation en trois parties consacrée aux fonctions de fenêtre, prenons un moment pour passer en revue notre parcours:
- Dans la Partie 1, nous avons établi les bases en expliquant le fonctionnement et la syntaxe des fonctions de fenêtre (comment elles fonctionnent et en quoi elles diffèrent des agrégations standards).
- Les Parties 2 et 3 ont mis l'accent sur les fonctions de fenêtre les plus couramment utilisées, illustrées par des exemples analytiques pratiques qui montrent leur valeur dans le monde réel.
- La Partie 3 a également présenté des conseils de performance et un guide de prise de décision pour vous aider à déterminer quand il faut (ou ne faut pas) utiliser les fonctions de fenêtre.
Les fonctions Windows permettent une amélioration significative de la puissance analytique du langage SQL, vous permettant d'exprimer une logique complexe de manière élégante, simple et facile à maintenir. Elles remplacent également souvent des codes procéduraux complexes et/ou des agrégations en plusieurs étapes.
Tout au long de cette série, nous avons regroupé les fonctions en catégories logiques afin de vous aider à mieux comprendre leurs rôles et à simplifier leur mémorisation. Nous espérons que cette structure s'avérera pratique pour découvrir le langage et pour une consultation ultérieure.
Les conseils de performance présentés dans la Partie 3 peuvent vous aider à éviter les pièges courants et à garantir le bon déroulement de vos requêtes.
Le guide d'utilisation fournit un cadre pratique pour déterminer quand les fonctions de fenêtre sont l'outil approprié et quand des alternatives plus simples peuvent être plus adaptées.
Nous espérons que cette série vous a aidé à comprendre la puissance et la polyvalence des fonctions de fenêtre. Si vous avez trouvé cela utile, si vous avez des questions, des commentaires ou des idées à partager, n'hésitez pas à nous en faire part. Vos réflexions peuvent enrichir le parcours de découverte et d'apprentissage, pour tout le monde.
Cet article a été rédigé avec l’aide d’outils d’intelligence artificielle afin de clarifier les concepts et d’en améliorer la lisibilité.