Streaming de Données avec InterSystems IRIS Interoperability
Les architectures de données modernes utilisent des solutions de capture, transformation, déplacement et chargement de données en temps réel pour construire des lacs de données, des entrepôts analytiques et des référentiels de big data. Cela permet l'analyse de données provenant de diverses sources sans impacter les opérations qui les utilisent. Pour y parvenir, il est essentiel d'établir un flux de données continu, évolutif, élastique et robuste. La méthode la plus répandue pour cela passe par la technique CDC (Change Data Capture). Le CDC surveille la production de petits ensembles de données, capture automatiquement ces données et les transmet à un ou plusieurs destinataires, y compris les référentiels de données analytiques. L'avantage majeur est l'élimination du délai J+1 dans l'analyse, car les données sont détectées à la source dès qu'elles sont produites, puis répliquées vers la destination.
Cet article démontrera les deux sources de données les plus courantes pour les scénarios CDC, à la fois comme source et comme destination. Pour la source de données (origine), nous explorerons le CDC dans les bases de données SQL et les fichiers CSV. Pour la destination des données, nous utiliserons une base de données en colonnes (un scénario typique de base de données analytique haute performance) et un topic Kafka (une approche standard pour le streaming de données vers le cloud et/ou vers plusieurs consommateurs de données en temps réel).
Aperçu
Cet article fournit un exemple pour le scénario d'interopérabilité suivant:

- Le SQLCDCAdapter utilisera le SQLInboundAdapter pour écouter les nouveaux enregistrements dans la base de données SQL et les extraire au moyen d'une connexion JDBC et du langage SQL.
- Le SQLCDCAdapter encapsulera les données capturées dans un message et les enverra au CDCProcess (un processus métier utilisant la notation BPL).
- Le processus CDC reçoit les données SQL sous forme de message et utilise l'opération SQL pour persister les données dans InterSystems IRIS et l'opération Kafka pour transmettre les données capturées à un sujet Kafka.
- L'opération SQL persistera les données du message dans une classe persistante InterSystems IRIS modélisée comme un stockage en colonnes. Le stockage en colonnes est une option qui offre des performances de requête supérieures pour les données analytiques.
- La Kafka Operation transformera le message en JSON et l'enverra à un topic Kafka, où un lac de données cloud ou tout autre abonné pourra le consommer.
- Ces flux de données s'exécutent en temps réel, établissant un flux de données continu
- Le Service BAM calcule les métriques métier à partir de la table en colonnes en temps réel.
- Un tableau de bord BI affichera instantanément les métriques métier résultantes à l'utilisateur.
Installation du modèle
Le modèle iris-cdc-sample (https://openexchange.intersystems.com/package/iris-cdc-sample) est une application modèle qui met en œuvre le scénario décrit ci-dessus. Pour l'installer, procédez comme suit:
1. Clonez ou effectuez un git pull du repo dans un répertoire local:
$ git clone https://github.com/yurimarx/iris-cdc-sample.git2. Ouvrez le terminal dans ce répertoire et exécutez la commande ci-dessous:
$ docker-compose build3. Exécutez le conteneur IRIS au moyen de votre projet:
$ docker-compose up -d
Composants du modèle
Ce modèle utilise les conteneurs suivants:
- iris : plateforme InterSystems IRIS, comprenant les éléments suivants:
- Base de données en colonnes IRIS (pour stocker les données capturées).
- Interopérabilité IRIS avec un environnement de production pour exécuter le processus CDC (capture des données modifiées). La production capture les données d'une base de données externe (PostgreSQL), les conserve dans IRIS et les transmet en outre à un sujet Kafka.
- IRIS BAM (Business Activity Monitoring - Surveillance de l'activité métier) pour calculer les indicateurs de vente en temps réel par produit et les afficher dans un tableau de bord.
- salesdb: une base de données PostgreSQL contenant les données de vente à capturer en temps réel.
- zookeeper: Un service utilisé pour gérer le broker Kafka.
- kafka: Le broker Kafka avec le topic des ventes, utilisé pour recevoir et distribuer les données de vente sous forme d'événements en temps réel.
- kafka-ui: Une interface Web Kafka pour l'administration et l'exploitation des topics et événements.
services:
iris:
build:
context: .
dockerfile: Dockerfile
restart: always
command: --check-caps false --ISCAgent false
ports:
- 1972
- 52795:52773
- 53773
volumes:
- ./:/home/irisowner/dev/
networks:
- cdc-network
salesdb:
image: postgres:14-alpine
container_name: sales_db
restart: always
environment:
POSTGRES_USER: sales_user
POSTGRES_PASSWORD: welcome1
POSTGRES_DB: sales_db
volumes:
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
- postgres_data:/var/lib/postgresql/data/
ports:
- "5433:5432"
networks:
- cdc-network
zookeeper:
image: confluentinc/cp-zookeeper:7.5.0
container_name: zookeeper
hostname: zookeeper
networks:
- cdc-network
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: confluentinc/cp-kafka:7.5.0
container_name: kafka
hostname: kafka
networks:
- cdc-network
ports:
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://kafka:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
kafka-ui:
image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
hostname: kafka-ui
networks:
- cdc-network
ports:
- "8080:8080"
depends_on:
- kafka
environment:
KAFKA_CLUSTERS_0_NAME: local_kafka_cluster
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:29092
volumes:
postgres_data:
driver: local
networks:
cdc-network:
driver: bridge
Création de la table en colonnes
Les tables en colonnes sont utilisées pour stocker des données non normalisées telles que celles-ci:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Étant donné que les valeurs Product Name (Nom du produit) et Store Name (Nom du magasin) sont fréquemment répétées, le stockage des données dans un format en colonnes (plutôt qu'en lignes) permet d'économiser de l'espace de stockage et d'obtenir des performances de récupération des données supérieures. Historiquement, ce type de traitement nécessitait la création de cubes BI. Cependant, le stockage en colonnes résout ce problème, éliminant ainsi le besoin de répliquer les données opérationnelles dans des cubes.
Suivez maintenant ces étapes pour créer le tableau en colonnes Sales pour notre exemple:
1. Créez une nouvelle classe ObjectScript Sales dans le paket dc.cdc.
2. Écrivez le code source suivant:
Class dc.cdc.Sales Extends %Persistent [ DdlAllowed, Final ]
{
Parameter STORAGEDEFAULT = "columnar";
Parameter USEEXTENTSET = 1;
Property ProductName As %String;
Property StoreName As %String;
Property SalesValue As %Double;
}
3. Le paramètre STORAGEDEFAULT = « columnar » garantit que la table dc_cdc.Sales utilise un stockage en colonnes plutôt que le format traditionnel en lignes.
Création de l'opération métier pour enregistrer les données capturées
Après avoir capturé les données de vente dans un StreamContainer à l'aide du SalesSqlService (aucune implémentation requise ; la configuration est effectuée dans la configuration de production sous la section "Doing CDC"), une opération métier est nécessaire pour traiter le StreamContainer, extraire les données de vente de PostgreSQL et les enregistrer dans la table de ventes (Sales Table). Procédez comme suit:
1. Créez la classe SalesOperation dans le paket dc.cdc.
2. Écrivez le code source ci-dessous:
Class dc.cdc.SalesOperation Extends Ens.BusinessOperation
{
Method ProcessSalesData(pRequest As Ens.StreamContainer, Output pResponse As Ens.StringResponse) As %Status
{
Set tSC = $$$OK
Set pResponse = ##class(Ens.StringResponse).%New()
Try {
Set tStream = pRequest.Stream
Do tStream.Rewind()
Set content = ""
While 'tStream.AtEnd {
Set content = content _ tStream.Read(4096)
}
Set tDynamicObject = {}.%FromJSON(content)
Set sales = ##class(dc.cdc.Sales).%New()
Set sales.ProductName = tDynamicObject."product_name"
Set sales.StoreName = tDynamicObject."store_name"
Set sales.SalesValue = tDynamicObject."sales_value"
Set tSC = sales.%Save()
Set pResponse.StringValue = tDynamicObject.%ToJSON()
} Catch (ex) {
Set tSC = ex.AsStatus()
Set pResponse.StringValue = "Error while saving sales data!"
$$$LOGERROR("Error while saving sales data: " _ ex.DisplayString())
}
Quit tSC
}
XData MessageMap
{
<MapItems>
<MapItem MessageType="Ens.StreamContainer">
<Method>ProcessSalesData</Method>
</MapItem>
</MapItems>
}
}
3. La méthode ProcessSalesData recevra des messages de type StreamContainer (conformément à la définition MessageMap).
4. La méthode lira les données de vente capturées dans une chaîne JSON, chargera le JSON dans un DynamicObject, créera un objet Sales, définira ses valeurs de propriété et l'enregistrera dans la table de ventes (Sales Table).
5. Enfin, la méthode renverra la chaîne JSON représentant les données de vente dans la réponse.
Création d'un service BAM pour la surveillance des ventes
InterSystems IRIS pour l'interopéabilité inclut une fonctionnalité BAM qui vous permet de surveiller en temps réel les données métier traitées en production à l'aide d'un tableau de bord analytique. Pour créer le service BAM, procédez comme suit:
1. Créez une nouvelle classe appelée SalesMetric qui étend Ens.BusinessMetric dans le paquet dc.cdc.
2. Écrivez le code source suivant:
Class dc.cdc.SalesMetric Extends Ens.BusinessMetric
{
Property TotalSales As Ens.DataType.Metric(UNITS = "$US") [ MultiDimensional ];
Query MetricInstances() As %SQLQuery
{
SELECT distinct(ProductName) FROM dc_cdc.Sales
}
/// Cálculez et mettez à jour l'ensemble des métriques pour cette classe
Method OnCalculateMetrics() As %Status
{
Set product = ..%Instance
Set SalesSum = 0.0
&sql(
select sum(SalesValue) into :SalesSum from dc_cdc.Sales where ProductName = :product
)
Set ..TotalSales = SalesSum
Quit $$$OK
}
}
3. La propriété TotalSales permet de surveiller en temps réel le total des ventes par produit.
4. La requête MetricInstances Query définit quels produits doivent être surveillés.
5. La méthode OnCalculateMetrics calcule le total des ventes pour chaque produit.
6. Cette classe sera utilisée dans une table de bord pour générer le total des ventes par produit en temps réel.
Exécution du processus CDC (Change Data Capture) et production
Notre diagramme de production final comprenant tous les processus ETL (extraction, conversion et chargement) requis est présenté ci-dessous:
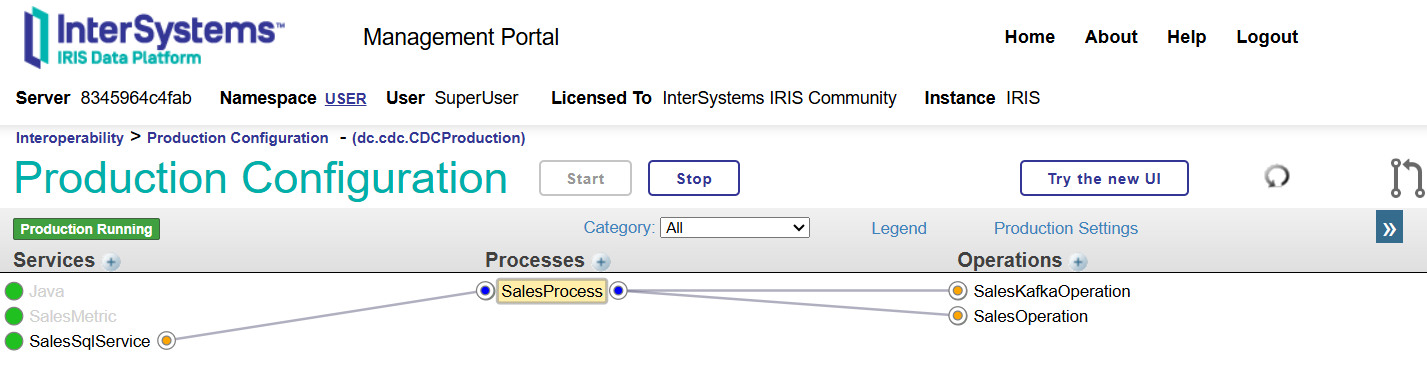
Suivez les étapes suivantes:
1. Accédez à CDC Production: http://localhost:52795/csp/user/EnsPortal.ProductionConfig.zen?PRODUCTION=dc.cdc.CDCProduction
2. Créez un nouveau service EnsLib.JavaGateway.Service nommé Java (requis pour SalesSqlService).
3. Générez un service métier appelé SalesSqlService (SQLCDCService) et configurez les paramètres suivants:
a. DSN (chaîne de connexion pour PostgreSQL): jdbc:postgresql://sales_db:5432/sales_db.
b. Informations d'identification: créez un pg_cred au moyen du nom d'utilisateur (sales_user) et du mot de passe (welcome1) pour accéder à PostgreSQL.
c. Noms de configuration cibles: SalesProcess (le processus CDC).
d. Requête (pour sélectionner les données à consommer): select * from sales.
e. Nom du champ clé (la colonne utilisée par IRIS pour suivre les lignes déjà capturées): id.
f. Service Java Gateway (requis car l'adaptateur CDC fonctionne à l'aide de JDBC): Java (Java Gateway pour cette production).
g. Pilote JDBC: org.postgresql.Driver.
h. Chemin d'accès JDBC (pilote permettant de se connecter à PostgreSQL au moyen de Dockerfile, copié via le script Dockerfile): /home/irisowner/dev/postgresql-42.7.8.jar.
4. Créez le nouveau dc.cdc.SalesMetric appelé SalesMetric.
5. Générez la nouvelle EnsLib.Kafka.Operation et nommez-la SalesKafkaOperation (opération Kafka) aux paramètres suivants:
a. ClientID: iris
b. Serveurs: kafka:9092
6. Créez le nouveau dc.cdc.SalesOperation appelé SalesOperation.
7. Développez un processus métier nommé SalesProcess. La logique d'implémentation BPL doit être la suivante:
a. Diagramme final:
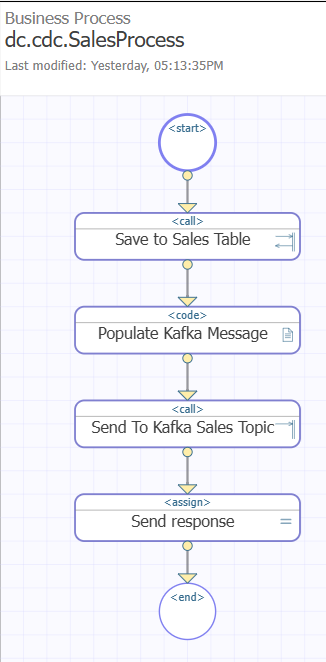
b. Créez deux propriétés Context:
i. Ventes avec le type Ens.StringResponse pour stocker les données de vente sous forme de chaîne JSON.
ii. KafkaMessage avec le type EnsLib.Kafka.Message (qui sera utilisé pour envoyer les données capturées au topic Kafka sales-topic).
c. Générez un appel, enregistrez-le dans la table Sales et définissez les paramètres suivants:
i. Cible : SalesOperation
ii. Classe de message de requête : Ens.StreamContainer (données capturées sous forme de flux)
iii. Actions de requête:

iv. Classe de message de réponse : Ens.StringResponse (le flux sera converti en une représentation JSON String des données capturées)
v. Actions de réponse:

d. Créez un bloc Code et écrivez le code ObjectScript qui remplira le message Kafka avec les propriétés nécessaires pour que les données de vente (sous forme de chaîne JSON) soient publiées en tant qu'événement dans le topic de vente sur le broker Kafka:
Set context.KafkaMessage.topic = "sales-topic"
Set context.KafkaMessage.value = context.Sales.StringValue
Set context.KafkaMessage.key = "iris"e. Concevez un appel à envoyer au topic de vente Kafka (Send To Kafka Sales Topic) et concevez:
i. Cible: SalesKafkaOperation
ii. Classe de message de requête : %Library.Persistent (KafkaMessage est Persistent)
iii. Actions de requête:

f. Créez une assignation nommée Send Response au moyen de:
i. Propriété: response.StringValue
ii. Valeur: "Process finished!" (le processus est achevé!)
Affichage des résultats CDC
Après avoir activé CDCProduction, complétez certains enregistrements dans la table des ventes PostgreSQL à l'aide de votre outil d'administration de base de données (DBeaver ou PgAdmin) et observez les résultats des messages de production.
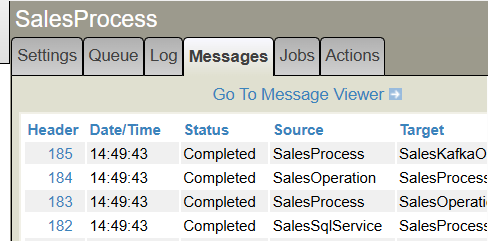
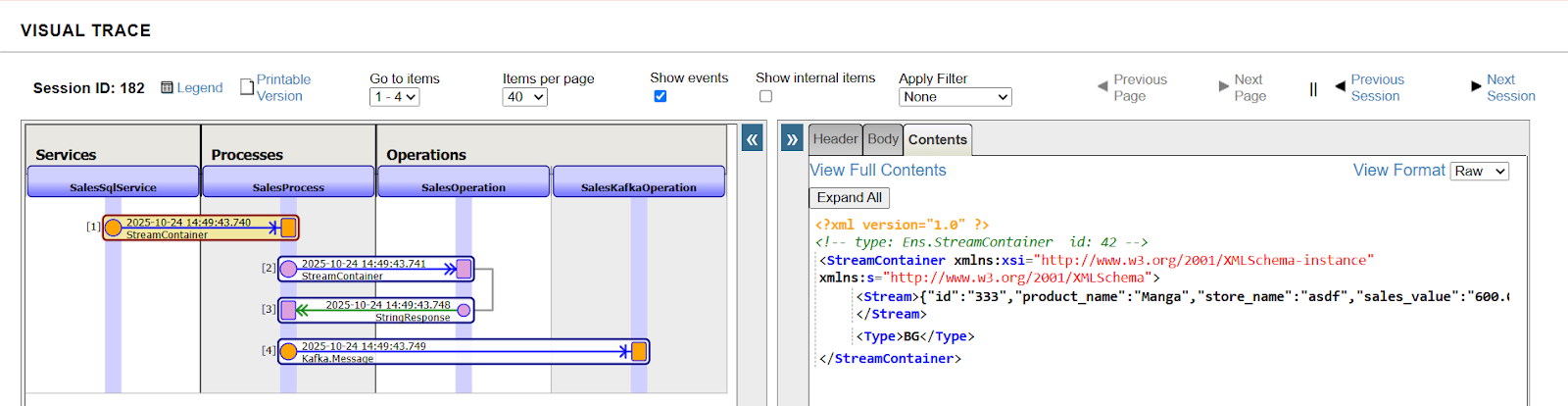
Consultez le diagramme de séquence pour comprendre le processus CDC (cliquez sur n'importe quel lien d'en-tête de message):
Affichage de la surveillance BAM dans un tableau de bord analytique
Lorsque vous capturez des données en temps réel, il est naturel de vouloir voir les résultats instantanément dans un tableau de bord. Pour ce faire, procédez comme suit:
1. Accédez à Analytics > Portail utilisateur:
2. Cliquez sur Ajouter un tableau de bord (Add Dashboard):

3. Définissez les propriétés ci-dessous et cliquez sur OK:
a. Dossier: Ens/Analytics
b. Nom du tableau de bord: Sales BAM
4. Cliquez sur Widgets:
5. Cliquez sur le bouton "plus":
6. Configurez le widget comme indiqué ci-dessous: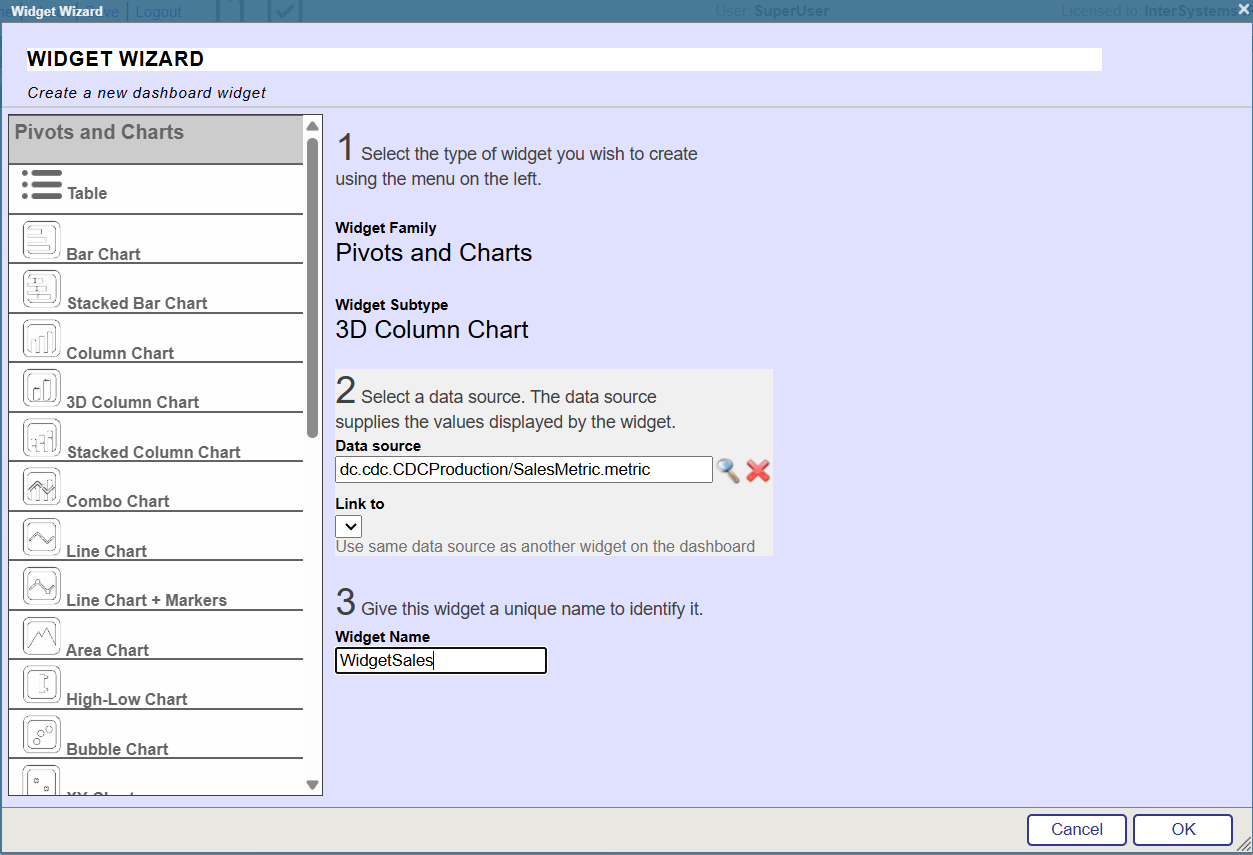
7. Ajustez le nouveau widget pour qu'il couvre toute la zone du tableau de bord.
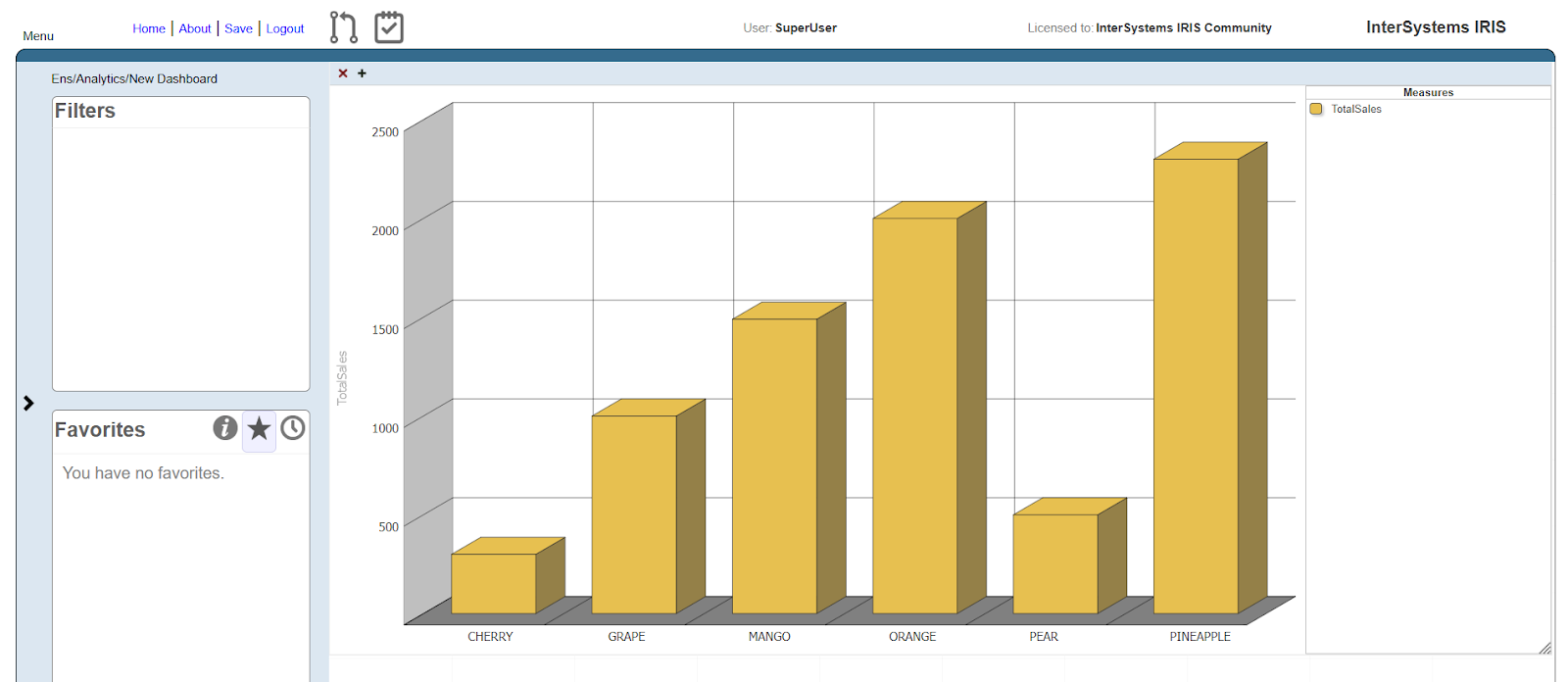
8. Maintenant, selectionnez WidgetSales:
9. Choisissez les contrôles:
10. Cliquez sur le bouton "plus":
11. Configurez le contrôle comme illustré ci-dessous (pour voir le total des ventes en temps réel, au moyen d'une actualisation automatique):
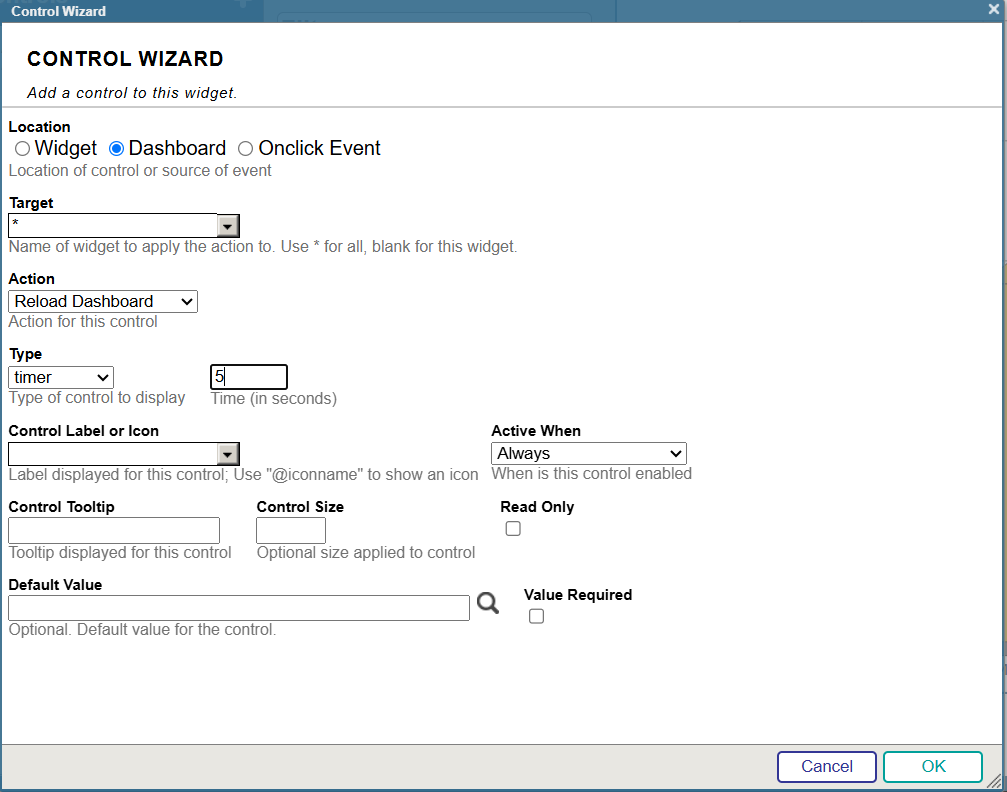
12. Désormais, lorsque de nouvelles valeurs sont saisies, le tableau de bord affiche immédiatement les valeurs mises à jour pour TotalSales.
Pour en savoir plus:
La documentation InterSystems peut vous aider à approfondir vos connaissances sur les productions CDC, BAM, Kafka et Interopérabilité. Consultez les pages ci-dessous pour en savoir plus:
- BAM: https://docs.intersystems.com/iris20252/csp/docbook/Doc.View.cls?KEY=EGIN_options#EGIN_options_bam
- Kafka: https://docs.intersystems.com/iris20252/csp/docbook/Doc.View.cls?KEY=ITECHREF_kafka
- SQL Adaptateurs (CDC pour les tables SQL): https://docs.intersystems.com/iris20252/csp/docbook/Doc.View.cls?KEY=ESQL_intro
- Creations des productions ETL/CDC: https://docs.intersystems.com/iris20252/csp/docbook/Doc.View.cls?KEY=PAGE_interop_languages
- BPL (processus métier visuel à faible codage): https://docs.intersystems.com/iris20252/csp/docbook/Doc.View.cls?KEY=EBPL_use
Comments
Merci pour cette traduction @Lorenzo Scalese