Effacer le filtre
Annonce
Irène Mykhailova · Juin 3, 2022
Bonjour à la communauté IRIS,
[InterSystems Certification](https://www.intersystems.com/knowledge-hub/certification-program) est en train de développer un examen de certification pour les administrateurs système IRIS et, si vous correspondez à la description de l'examen ci-dessous, nous aimerions que vous testiez l'examen en version bêta. L'examen sera disponible pour un test bêta du 20 au 23 juin 2022 lors du [Global Summit 2022](https://summit.intersystems.com/event/448ad72e-74e4-4869-b352-8bf74652d856/summary), mais uniquement pour les personnes inscrites au Summit (visitez cette page pour en savoir plus sur la certification au [GS22](https://summit.intersystems.com/event/448ad72e-74e4-4869-b352-8bf74652d856/websitePage:3100a899-5772-4047-8be9-54e45ea4db79)). Le test bêta sera ouvert à tous les autres bêta-testeurs intéressés le 1er juillet 2022. Les bêta-testeurs intéressés doivent toutefois s'inscrire dès maintenant en envoyant un courriel à **certification@intersystems.com **(voir ci-dessous pour plus de détails)**. Le test bêta doit être terminé pour le 1er août 2022**.
**Quelles sont mes responsabilités en tant que bêta-testeur ?**
L'examen vous sera attribué et vous devrez le passer dans le mois suivant la sortie de la version bêta. L'examen sera administré dans un environnement surveillé en ligne (surveillé en direct pendant le Summit), gratuitement (les frais standard de 150 $ par examen sont supprimés pour tous les bêta-testeurs), puis l'équipe de certification d'InterSystems effectuera une analyse statistique minutieuse de toutes les données du bêta-test afin de fixer une note de passage pour l'examen. L'analyse des résultats du test bêta prendra 6 à 8 semaines et, une fois la note de passage établie, vous recevrez une notification par courriel de la part d'InterSystems Certification vous informant des résultats. **Si votre note à l'examen est égale ou supérieure à la note de passage, vous aurez obtenu la certification ! **
**Remarque : les résultats des tests bêta sont totalement confidentiels.**
Les informations sur l'examen
**Titre de l'examen:** Expert en administration de systèmes InterSystems IRIS
**Description du candidat:** Un professionnel de l'informatique qui :
* installe, gère et surveille les environnements InterSystems IRIS,
* et garantit la sécurité, l'intégrité et la haute disponibilité des données.
**Nombre de questions :** 73
**Temps prévu pour passer l'examen:** 2 heures
**Préparation recommandée :**
Programme de cours en classe Management des serveurs InterSystems ou expérience équivalente. Le cours en ligne Bases de la gestion d'IRIS InterSystems, est recommandé, ainsi qu'une expérience de recherche Documentation sur la gestion des plates-formes.
**Expérience pratique recommandée :**
* 1 à 2 ans d'expérience dans l'administration, la gestion et la sécurité de systèmes utilisant la plate-forme de données InterSystems IRIS version 2019.1 ou supérieure.
* Révision de la série de questions d'entraînement qui se trouve dans le fichier PDF au bas de cette page (disponible ici après le 6 juin 2022)
**Questions d'entraînement d'examen**
Cet examen comprendra un ensemble de questions d'entraînement pour aider les candidats à se familiariser avec les formats et les approches des questions. Le document sera disponible ici le 6 juin 2022.
**Thèmes et contenu de l'examen**
L'examen contient des questions qui couvrent les domaines du rôle indiqué, comme le montre le tableau CCA (connaissances, compétences et aptitudes) ci-dessous. Les questions sont présentées sous deux formes : choix multiple et réponse multiple.
Groupe CCA
Description du groupe CCA
Description de CCA
Objets ciblés
T41
Installation et configuration d'InterSystems IRIS
Installation et mise à niveau des instances
Installation d'instances de développement, de clients, de serveurs et d'instances personnalisées ; Installation de différentes sécurités d'InterSystems IRIS ; Identification de la structure et du contenu des dossiers dans le répertoire d'installation ; Démarrage, arrêt et liste des instances à partir de la ligne de commande ; Mise à niveau des instances existantes
Configuration des espaces de noms, des bases de données, de la mémoire et d'autres paramètres du système
Création, visualisation et suppression d'espaces de noms et de bases de données ; Identification du contenu et des caractéristiques des bases de données par défaut ; Mise en correspondance et gestion des globales, des routines et des paquets ; Détermination des cas où il est nécessaire de modifier directement l'iris. cpf et quand cela est déconseillé ; Détermination de la taille appropriée des tampons globaux et des tampons de routine, et ajustement de ces derniers si nécessaire ; Détermination des états de journal appropriés, de la taille de la base de données et de la taille maximale de la base de données ; Détermination de l'espace disque nécessaire à l'installation et au fonctionnement ; Détermination de la mémoire nécessaire à l'installation et au fonctionnement ; Détermination des valeurs appropriées pour les paramètres génériques du tas de mémoire ; Augmentation de la taille des tableaux de verrouillage.
Gestion des licences
Activation et révision des licences ; configuration des serveurs de licences
T42
Gestion et surveillance d'InterSystems IRIS
Gestion des bases de données
Montage, démontage et expansion des bases de données ; compactage, tronquage et défragmentation des bases de données ; vérification de l'intégrité des bases de données ; gestion des données ; gestion des routines
Gestion des processus utilisateur et système
Exécution des opérations de processus : suspension, reprise, terminaison ; Inspection des processus ; Gestion des verrouillages de processus ; Utilisation du gestionnaire de tâches pour visualiser, planifier, exécuter, gérer et automatiser les tâches
Gestion de la journalisation
Configuration des paramètres et de l'emplacement des journaux ; utilisation de la journalisation ; importance de l'activation de l'option "Freeze on error" pour l'intégrité des données ; différence entre les fonctions WIJ et les fonctions de journal ; utilisation de l'utilitaire Journal Profile ; restauration des journaux ; effacement des fichiers de journal
Diagnostic et dépannage des problèmes
Accès et configuration des journaux système ; identification et interprétation des erreurs stockées dans les journaux système ; exécution du Rapport IRISHung/Diagnostic ; identification et fin des processus bloqués/en boucle ; interdiction d'accès ; accès d'urgence à la configuration
Contrôle du système
Utilisation de ^PERFMON pour surveiller le système ; Détermination des outils de surveillance appropriés pour différents problèmes de performance tels que les profils de journaux, ^BLKCOL et ^SystemPerformance ; Exécution de l'utilitaire ^SystemPerformance ; Détermination des tailles de globales
T43
Mise en œuvre de la continuité du système
Implémentation de la mise en miroir
Identification des conditions nécessaires à l'implémentation de la mise en miroir ; Identification des membres du miroir et description de la communication entre miroirs ; Configuration de la mise en miroir ; Détermination des possibilités de basculement ; Ajout de bases de données aux miroirs
Implémentation de l'ECP
Utilisation de l'ECP ; configuration des serveurs de données et d'applications de l'ECP ; surveillance et contrôle des connexions ECP
Gestion des sauvegardes et des récupérations
Planification des stratégies de sauvegarde, y compris la fréquence requise, la conservation des fichiers journaux, et la prise en compte des sauvegardes au niveau du système d'exploitation par rapport aux sauvegardes en ligne InterSystems ; identification du contenu des sauvegardes ; utilisation des API FREEZE et THAW pour les sauvegardes instantanées ; vérification des sauvegardes ; restauration du système
T44
Mise en œuvre de la sécurité du système
Utilisation d'un journal d'audit pour suivre les événements liés aux utilisateurs et au système
Activation et désactivation des événements d'audit ; visualisation des entrées d'audit et des propriétés des événements d'audit ; identification de la cause première des événements d'audit courants ; gestion de la base de données d'audit
Gestion de la sécurité
Création d'utilisateurs et de rôles ; attribution de rôles et de privilèges ; octroi d'autorisations aux ressources ; activation et désactivation de services ; protection des applications et des ressources au sein des applications ; mise en œuvre du cryptage des bases de données et des éléments de données ; cryptage des journaux ; gestion des paramètres de sécurité à l'échelle du système ; importation/exportation des paramètres de sécurité ; réduction de la surface d'attaque ; mise en œuvre de l'authentification à deux facteurs ; identification des multiples couches impliquées dans la configuration et le dépannage de la passerelle Web (y compris la connexion d'un serveur web externe à InterSystems IRIS)
**Vous souhaitez participer ? Envoyez un courriel à certification@intersystems.com maintenant !**
Annonce
Irène Mykhailova · Déc 29, 2022
Si vous souhaitez essayer le nouveau processus d'installation du projet NoPWS, vous pouvez accéder à l'Early Access Program (EAP) here.
Une fois inscrit, veuillez envoyer à InterSystems l'adresse e-mail que vous avez utilisée pour vous inscrire à l'EAP à nopws@intersystems.com.
Regardez ici pour en savoir plus : message original
Article
Guillaume Rongier · Nov 30, 2023
Dans cette série d'articles, j'aimerais présenter et discuter de plusieurs approches possibles pour le développement de logiciels avec les technologies d'InterSystems et GitLab. J'aborderai des sujets tels que:
Git 101
Flux Git (processus de développement)
Installation de GitLab
Flux de travail GitLab
Diffusion continue
Installation et configuration de GitLab
GitLab CI/CD
Dans le premier article, nous avons évoqué les notions de base de Git, les raisons pour lesquelles une compréhension approfondie des concepts de Git est importante pour le développement de logiciels modernes et la manière dont Git peut être utilisé pour développer des logiciels.
Dans le deuxième article, nous avons évoqué le flux de travail GitLab - un processus complet du cycle de vie du logiciel ainsi que Diffusion continue.
Dans le troisième article, nous avons évoqué l'installation et la configuration de GitLab et la connexion de vos environnements à GitLab
Dans cet article, nous allons enfin écrire une configuration sur CD.
Plan
Environnements
Tout d'abord, nous avons besoin de plusieurs environnements et de branches qui leur correspondent:
Environnement
Branche
Diffusion
Qui peut valider
Qui peut fusionner
Test
master
Automatique
Développeurs Propriétaires
Développeurs Propriétaires
Preprod (préproduction)
preprod
Automatique
Personne
Propriétaires
Prod (production)
prod
Semi-automatique (appuyez sur le bouton pour diffuser)
Personne
Owners
Cycle de développement
A titre d'exemple, nous allons développer une nouvelle fonctionnalité en utilisant le flux GitLab et la livrer en utilisant le GitLab CD.
Les fonctionnalités sont développées dans une branche des fonctionnalités.
La branche des fonctionnalités est révisée et fusionnée dans la branche master.
Après quelque temps (plusieurs fonctionnalités fusionnées), le master est fusionné dans le preprod
Après quelque temps (tests d'utilisateurs, etc.), la préprod est fusionnée dans la prod
Voici à quoi il pourrait ressembler (j'ai marqué en cursive les parties qu'il faut développer pour le CD) :
Développement et test
Le développeur valide le code de la nouvelle fonctionnalité dans une branche de fonctionnalité séparée
Une fois que la fonctionnalité est devenue stable, le développeur fusionne la branche de la fonctionnalité dans la branche master
Le code de la branche master est livré à l'environnement de test, où il est téléchargé et testé
Diffusion dans l'environnement de Preprod
Le développeur crée une demande de fusion de la branche master vers la branche preprod
Le propriétaire du référentiel approuve la demande de fusion après un certain temps
Le code de la branche Preprod est diffusé dans l'environnement Preprod
Diffusion dans l'environnement Prod
Le développeur crée une demande de fusion de la branche preprod vers la branche prod
Le propriétaire du référentiel approuve la demande de fusion après un certain temps
Le propriétaire du référentiel appuie sur le bouton "Deploy" (Déployer)
Le code de la branche prod est diffusé dans l'environnement Prod
Ou le même mais sous une forme graphique :
Application
Notre application se compose de deux parties:
API REST développée sur la plateforme InterSystems
Application web JavaScript client
Étapes
À partir du plan ci-dessus, nous pouvons déterminer les étapes à définir dans notre configuration de diffusion continue :
Téléchargement - pour importer le code côté serveur dans InterSystems IRIS
Test - pour tester le code client et le code serveur
Paquet - pour construire le code client
Déploiement - pour "publier" le code client à l'aide d'un serveur web
Voici à quoi cela ressemble dans le fichier .gitlab-ci.yml de configuration :
stages:
- load
- test
- package
- deploy
Scripts
Téléchargement
Ensuite, définissons les scripts. Documentation des scripts. Tout d'abord, définissons un serveur de téléchargement de scripts qui permet le téléchargement du code côté serveur :
load server:
environment:
name: test
url: http://test.hostname.com
only:
- master
tags:
- test
stage: load
script: csession IRIS "##class(isc.git.GitLab).load()"
Que se passe-t-il ici?
load server est un nom de script
ensuite, nous décrivons l'environnement dans lequel ce script s'exécute
only: master - indique à GitLab que ce script est exécuté uniquement lorsqu'il y a un commit sur la branche master
tags: test indique que ce script doit être exécuté uniquement sur un système d'exécution qui a la balise de test
stage indique l'étape d'un script
script définit le code à exécuter. Dans notre cas, nous appelons le téléchargement de classmethod à partir de la classe isc.git.GitLab
Remarque importante
Pour InterSystems IRIS, remplacez csession par iris session.
Pour une utilisation sous Windows: irisdb -s ../mgr -U TEST "##class(isc.git.GitLab).load()
Maintenant, écrivons la classe isc.git.GitLab correspondante. Tous les points d'entrée de cette classe ressemblent à ceci :
ClassMethod method()
{
try {
// code
halt
} catch ex {
write !,$System.Status.GetErrorText(ex.AsStatus()),!
do $system.Process.Terminate(, 1)
}
}
Notez que cette méthode peut se terminer de deux façons :
en arrêtant le processus en cours - ce qui est enregistré dans GitLab comme une réussite
en appelant $system.Process.Terminate - ce qui termine le processus de manière anormale et GitLab l'enregistre comme une erreur
Enfin, voici notre code de téléchargement :
/// Effectuer un téléchargement complet
/// Effectuer ##class(isc.git.GitLab).load()
ClassMethod load()
{
try {
set dir = ..getDir()
do ..log("Importing dir " _ dir)
do $system.OBJ.ImportDir(dir, ..getExtWildcard(), "c", .errors, 1)
throw:$get(errors,0)'=0 ##class(%Exception.General).%New("Load error")
halt
} catch ex {
write !,$System.Status.GetErrorText(ex.AsStatus()),!
do $system.Process.Terminate(, 1)
}
}
Deux méthodes utilitaires sont appelées :
getExtWildcard - pour obtenir une liste des extensions de fichiers pertinentes
getDir - pour obtenir le répertoire du référentiel
Comment obtenir le répertoire ?
Lorsque GitLab exécute un script, il spécifie d'abord un grand nombre de variables d'environnement. La première est CI_PROJECT_DIR - Le chemin complet où le référentiel est cloné et où la tâche est exécutée. Nous pouvons l'obtenir dans la méthode getDir sans problème :
ClassMethod getDir() [ CodeMode = expression ]
{
##class(%File).NormalizeDirectory($system.Util.GetEnviron("CI_PROJECT_DIR"))
}
Tests
Voici le script de test:
load test:
environment:
name: test
url: http://test.hostname.com
only:
- master
tags:
- test
stage: test
script: csession IRIS "##class(isc.git.GitLab).test()"
artifacts:
paths:
- tests.html
Quels sont les changements ? Le nom et le code du script, bien sûr, mais l'artefact a également été ajouté. Un artefact est une liste de fichiers et de répertoires qui sont attachés à une tâche une fois qu'elle s'est achevée avec succès. Dans notre cas, une fois les tests terminés, nous pouvons générer une page HTML redirigeant vers les résultats des tests et la rendre disponible sur GitLab.
Remarquez qu'il y a beaucoup de copier-coller de l'étape de téléchargement - l'environnement est le même, les parties du script telles que les environnements peuvent être étiquetées séparément et attachées à un script. Définissons l'environnement de test :
.env_test: &env_test
environment:
name: test
url: http://test.hostname.com
only:
- master
tags:
- test
Maintenant, notre script de test ressemble à ceci :
load test:
<<: *env_test
script: csession IRIS "##class(isc.git.GitLab).test()"
artifacts:
paths:
- tests.html
Ensuite, exécutons les tests à l'aide duframework UnitTest.
/// Exécuter ##class(isc.git.GitLab).test()
ClassMethod test()
{
try {
set tests = ##class(isc.git.Settings).getSetting("tests")
if (tests'="") {
set dir = ..getDir()
set ^UnitTestRoot = dir
$$$TOE(sc, ##class(%UnitTest.Manager).RunTest(tests, "/nodelete"))
$$$TOE(sc, ..writeTestHTML())
throw:'..isLastTestOk() ##class(%Exception.General).%New("Tests error")
}
halt
} catch ex {
do ..logException(ex)
do $system.Process.Terminate(, 1)
}
}
Le paramètre Tests, dans ce cas, est un chemin relatif à la racine du référentiel où sont stockés les tests unitaires. S'il est vide, les tests sont ignorés. La méthode writeTestHTML est utilisée pour produire du html avec une redirection vers les résultats des tests :
ClassMethod writeTestHTML()
{
set text = ##class(%Dictionary.XDataDefinition).IDKEYOpen($classname(), "html").Data.Read()
set text = $replace(text, "!!!", ..getURL())
set file = ##class(%Stream.FileCharacter).%New()
set name = ..getDir() _ "tests.html"
do file.LinkToFile(name)
do file.Write(text)
quit file.%Save()
}
ClassMethod getURL()
{
set url = ##class(isc.git.Settings).getSetting("url")
set url = url _ $system.CSP.GetDefaultApp("%SYS")
set url = url_"/%25UnitTest.Portal.Indices.cls?Index="_ $g(^UnitTest.Result, 1) _ "&$NAMESPACE=" _ $zconvert($namespace,"O","URL")
quit url
}
ClassMethod isLastTestOk() As %Boolean
{
set in = ##class(%UnitTest.Result.TestInstance).%OpenId(^UnitTest.Result)
for i=1:1:in.TestSuites.Count() {
#dim suite As %UnitTest.Result.TestSuite
set suite = in.TestSuites.GetAt(i)
return:suite.Status=0 $$$NO
}
quit $$$YES
}
XData html
{
<html lang="en-US">
<head>
<meta charset="UTF-8"/>
<meta http-equiv="refresh" content="0; url=!!!"/>
<script type="text/javascript">
window.location.href = "!!!"
</script>
</head>
<body>
If you are not redirected automatically, follow this <a href='!!!'>link to tests</a>.
</body>
</html>
}
Paquet
Notre client est une simple page HTML:
<html>
<head>
<script type="text/javascript">
function initializePage() {
var xhr = new XMLHttpRequest();
var url = "${CI_ENVIRONMENT_URL}:57772/MyApp/version";
xhr.open("GET", url, true);
xhr.send();
xhr.onloadend = function (data) {
document.getElementById("version").innerHTML = "Version: " + this.response;
};
var xhr = new XMLHttpRequest();
var url = "${CI_ENVIRONMENT_URL}:57772/MyApp/author";
xhr.open("GET", url, true);
xhr.send();
xhr.onloadend = function (data) {
document.getElementById("author").innerHTML = "Author: " + this.response;
};
}
</script>
</head>
<body onload="initializePage()">
<div id = "version"></div>
<div id = "author"></div>
</body>
</html>
Et pour le construire, nous devons remplacer ${CI_ENVIRONMENT_URL} avec sa valeur. Bien sûr, une application réelle nécessiterait probablement npm, mais ce n'est qu'un exemple. Voici le script :
package client:
<<: *env_test
stage: package
script: envsubst < client/index.html > index.html
artifacts:
paths:
- index.html
Déploiement
Enfin, nous déployons notre client en copiant index.html dans le répertoire racine du serveur web.
deploy client:
<<: *env_test
stage: deploy
script: cp -f index.html /var/www/html/index.html
C'est tout !
Plusieurs environnements
Que faire si vous devez exécuter le même (ou similaire) script dans plusieurs environnements ? Les parties de script peuvent également être des étiquettes. Voici un exemple de configuration qui charge le code dans les environnements de test et de préprod :
stages:
- load
- test
.env_test: &env_test
environment:
name: test
url: http://test.hostname.com
only:
- master
tags:
- test
.env_preprod: &env_preprod
environment:
name: preprod
url: http://preprod.hostname.com
only:
- preprod
tags:
- preprod
.script_load: &script_load
stage: load
script: csession IRIS "##class(isc.git.GitLab).loadDiff()"
load test:
<<: *env_test
<<: *script_load
load preprod:
<<: *env_preprod
<<: *script_load
Nous pouvons ainsi éviter de copier-coller le code.
La configuration complète du CD est disponible ici. Il suit le plan initial de déplacement du code entre les environnements de test, de préproduction et de production.
Conclusion
La diffusion continue peut être configurée pour automatiser tout flux de développement nécessaire.
Liens
Référentiel de hooks (et exemple de configuration)
Référentiel de tests
Documentation des scripts
Variables d'environnement disponibles
Prochaine étape
Dans le prochain article, nous créerons une configuration CD qui s'appuie sur le conteneur Docker InterSystems IRIS.
Article
Guillaume Rongier · Déc 7, 2023
Dans cette série d'articles, j'aimerais présenter et discuter de plusieurs approches possibles pour le développement de logiciels avec les technologies d'InterSystems et GitLab. J'aborderai des sujets tels que:
Git 101
Flux Git (processus de développement)
Installation de GitLab
Flux de travail GitLab
Diffusion continue
Installation et configuration de GitLab
GitLab CI/CD
Pourquoi des conteneurs?
Infrastructure de conteneurs
GitLab CI/CD utilisant des conteneurs
Dans le premier article, nous avons évoqué les notions de base de Git, les raisons pour lesquelles une compréhension approfondie des concepts de Git est importante pour le développement de logiciels modernes et la manière dont Git peut être utilisé pour développer des logiciels.
Dans le deuxième article, nous avons évoqué le flux de travail GitLab - un processus complet du cycle de vie du logiciel ainsi que Diffusion continue.
Dans le troisième article, nous avons évoqué l'installation et la configuration de GitLab et la connexion de vos environnements à GitLab
Dans le quatrième article, nous avons écrit une configuration de CD.
Dans le cinquième article, nous avons parlé des conteneurs et de la manière dont ils peuvent être utilisés (et pour quelles raisons).
Dans cet article, nous allons discuter des principaux composants dont vous aurez besoin pour exécuter un pipeline de diffusion continue avec des conteneurs et de la façon dont ils fonctionnent tous ensemble.
Notre configuration se présente comme suit :
On voit ici la répartition des trois étapes principales :
Construction
Expédition
Exécution
Build
Dans les parties précédentes, la construction (build) était souvent incrémentale - nous calculions la différence entre l'environnement actuel et la base de code actuelle et modifiions notre environnement pour qu'il corresponde à la base de code. Avec les conteneurs, chaque build est un build complet. Le résultat du build est une image qui peut être exécutée n'importe où, sans dépendances.
Expédition
Une fois que notre image est construite et qu'elle a passé les tests, elle est téléchargée dans le registre - serveur spécialisé pour héberger les images docker. Elle peut alors remplacer l'image précédente ayant la même balise. Par exemple, suite à un nouveau commit dans la branche master, nous avons construit la nouvelle image (projet/version:master) et si les tests sont positifs, nous pouvons remplacer l'image dans le registre par une nouvelle sous la même balise, de sorte que tous ceux qui extraient le projet/version:master obtiendront une nouvelle version.
Exécution
Les images sont enfin déployées. Bien qu'une solution de CI telle que GitLab puisse contrôler ou un orchestrateur spécialisé, l'objectif est le même : certaines images sont exécutées, leur état est vérifié périodiquement et elles sont mises à jour si une nouvelle version de l'image est disponible.
Consultez le webinar de docker expliquant ces différentes étapes.
Ou encore, du point de vue du commit :
Dans notre configuration de diffusion, nous allons:
Introduire le code dans le référentiel GitLab
Construire l'image docker
Tester cette image
Publier l'image dans notre registre docker
Remplacer l'ancien conteneur par la nouvelle version à partir du registre
P
Docker
Registre Docker
Domaine enregistré (facultatif mais préférable)
Outils graphique GUI (facultatif)
Docker
Tout d'abord, il faut lancer docker quelque part. Je recommanderais de commencer par un serveur équipé d'une version plus courante de Linux, comme Ubuntu, RHEL ou Suse. N'utilisez pas de distributions orientées cloud comme CoreOS, RancherOS, etc. - elles ne sont pas adaptées aux débutants. N'oubliez pas de remplacer le pilote de stockage par devicemapper.
Si nous parlons de déploiements importants, l'utilisation d'outils d'orchestration de conteneurs comme Kubernetes, Rancher ou Swarm peut automatiser la plupart des tâches, mais nous n'allons pas en discuter (du moins dans cette partie).
Registre Docker
Il s'agit d'un premier conteneur que nous devons exécuter, et c'est une application côté serveur évolutive sans état qui stocke les images Docker et vous permet de les distribuer.Vous devriez utiliser le Registre si vous voulez :
contrôler rigoureusement l'endroit où vos images sont stockées
être pleinement propriétaire de son pipeline de distribution d'images
intégrer rigoureusement le stockage et la distribution d'images dans votre flux de travail de développement interne
Voici la Documentation de Registre.
Connexion du registre et de GitLab
Remarque: GitLab contient un registre intégré. Vous pouvez l'exécuter à la place du registre externe. Lisez les documents GitLab liés dans ce paragraphe.
Pour connecter votre registre à GitLab, il vous faudra exécuter votre registre avec le support HTTPS - j'utilise Let's Encrypt pour obtenir des certificats, et j'ai suivi ce Gist pour obtenir des certificats et les introduire dans un conteneur. Après avoir vérifié que le registre est disponible en HTTPS (vous pouvez le vérifier depuis votre navigateur), suivez ces instructions pour connecter le registre à GitLab. Ces instructions varient en fonction de vos besoins et de votre installation de GitLab, dans mon cas la configuration consistait à ajouter le certificat et la clé du registre (correctement nommés et avec les permissions correctes) à /etc/gitlab/ssl, et ces lignes à /etc/gitlab/gitlab.rb:
registry_external_url 'https://docker.domain.com'
gitlab_rails['registry_api_url'] = "https://docker.domain.com"
Après la reconfiguration de GitLab, j'ai pu voir un nouvel onglet Registry dans lequel se trouvent les informations sur la manière de marquer correctement les images nouvellement construites, de sorte qu'elles apparaissent ici.
Domaine
Dans notre configuration de diffusion continue, nous construirons automatiquement une image par branche et si l'image passe les tests alors nous la publierons dans le registre et l'exécuterons automatiquement, ainsi notre application sera automatiquement disponible dans tous les " états ", par exemple, auxquels nous pouvons accéder :
Plusieurs branches de fonctionnalités disponibles à <featureName>.docker.domain.com
Version test disponible à master.docker.domain.com
Version préprod disponible à preprod.docker.domain.com
Version prod disponible à prod.docker.domain.com
Pour ce faire, il nous faut disposer d'un nom de domaine et ajouter un enregistrement DNS de type wildcard qui renvoie *.docker.domain.com vers l'adresse IP de docker.domain.com. Or vous pouvez utiliser des ports différents.
Proxy Nginx
Comme nous avons plusieurs branches de fonctionnalités, nous devons rediriger automatiquement les sous-domaines vers le conteneur approprié. Pour ce faire, nous pouvons utiliser Nginx comme un proxy inverse. Voici un guide.
Outils graphique GUI
Pour commencer l'utilisation des conteneurs, vous pouvez utiliser la ligne de commande ou l'une des interfaces graphiques GUI. Il en existe de nombreux, par exemple :
Rancher
MicroBadger
Portainer
Simple Docker UI
...
Ils vous permettent de créer des conteneurs et de les gérer à partir de l'interface graphique GUI au lieu de l'interface de commande (CLI). Voici à quoi ressemble Rancher :
Système d'exécution de GitLab
Comme précédemment, pour exécuter des scripts sur d'autres serveurs, nous devons installer le système d'exécution de GitLab. J'en ai parlé dans le troisième article.
Notez que vous devrez utiliser l'exécuteur Shell au lieu de l'exécuteur Docker. L'exécuteur Docker est utilisé lorsque vous avez besoin de quelque chose à l'intérieur de l'image, par exemple vous construisez une application Android dans un conteneur Java et vous n'avez besoin que d'une apk. Dans notre cas, il nous faut un conteneur complet et pour cela nous avons besoin de l'exécuteur Shell.
Conclusion
Il est facile de commencer à utiliser des conteneurs et il existe de nombreux outils à choisir.
La diffusion continue utilisant des conteneurs diffère de la configuration habituelle de la diffusion continue à plusieurs égards :
Les dépendances sont satisfaites au moment de la construction et une fois l'image construite, il n'est plus nécessaire de se soucier des dépendances.
Reproductibilité - vous pouvez reproduire facilement un environnement existant en utilisant localement le même conteneur.
Rapidité - comme les conteneurs ne contiennent rien d'autre que ce que vous avez explicitement ajouté, ils peuvent être construits plus rapidement et, surtout, ils sont construits une seule fois et utilisés à tout moment.
Efficacité - comme ci-dessus, les conteneurs génèrent moins de frais généraux par rapport, par exemple, aux VMs.
Évolutivité - grâce aux outils d'orchestration, vous pouvez automatiquement adapter votre application à la charge de travail et ne consommer que les ressources dont vous avez besoin dans l'immédiat.
Prochaine étape
Dans le prochain article, nous parlerons de la création d'une configuration CD qui s'appuie sur le conteneur Docker InterSystems IRIS.
Article
Guillaume Rongier · Déc 21, 2023
Après presque quatre ans de pause, ma série CI/CD est de retour ! Au fil des ans, j'ai travaillé avec plusieurs clients d'InterSystems, développant des pipelines CI/CD pour différents cas d'utilisation. J'espère que les informations présentées dans cet article seront utiles à quelqu'un.
Cette série d'articles aborde plusieurs approches possibles du développement logiciel avec les technologies InterSystems et GitLab.
Nous avons une gamme passionnante de sujets à couvrir: aujourd'hui, parlons de choses au - delà du code, à savoir les configurations et les données.
# Problème
Nous avons déjà abordé la question des promotions de code, qui était, d'une certaine manière, sans état - nous passons toujours d'une instance (présumée) vide à une base de code complète. Mais parfois, nous devons fournir des données ou un état. Il existe différents types de données:
- Configuration: utilisateurs, applications Web, LUT, schémas personnalisés, tâches, partenaires commerciaux et bien d'autres
- Paramètres: paires clé-valeur spécifiques à l'environnement
- Données : des tableaux de référence etc. doivent souvent être fournis pour que votre application fonctionne.
Discutons de tous ces types de données et de la manière dont ils peuvent d'abord être validés dans le contrôle de code source, et ensuite déployés.
# Configuration
La configuration de système est répartie dans de nombreuses classes différentes, mais InterSystems IRIS peut exporter la plupart d'entre elles en XML. Tout d'abord, il s'agit d'un [paquet de sécurité](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&PACKAGE=Security) qui contient des informations sur :
- Les Applications Web
- DocDBs
- Les domaines
- Les événements d'audit
- Les serveurs KMIPServers
- Les configurations LDAP
- Les ressources
- Les rôles
- Les privilèges SQL
- Les configurations SSL
- Les services
- Les utilisateurs
Toutes ces classes sont dotées de méthodes Exists, Export et Import, qui vous permettent de les déplacer d'un environnement à l'autre.
Quelques avertissements :
- Les utilisateurs et les configurations SSL peuvent contenir des informations sensibles, telles que des mots de passe. Il N'est généralement PAS recommandé de les stocker dans le contrôle du code source pour des raisons de sécurité. Utilisez des méthodes d'exportation/importation pour faciliter les transferts ponctuels.
- Par défaut, les méthodes d'exportation et d'importation produisent tout dans un seul fichier, ce qui n'est pas forcément compatible avec le contrôle du code source. Voici une [classe utilitaire](https://gist.github.com/eduard93/3a9abdb2eb150a456191bf387c1fc0c3) qui permet d'exporter et d'importer des tableaux de consultation (LUT), des schémas personnalisés, des partenaires commerciaux, des tâches, des informations d'identification et une configuration SSL. Il exporte un élément par fichier, de sorte que vous obtenez un répertoire avec LUT, un autre répertoire avec des schémas personnalisés, et ainsi de suite. Pour les configurations SSL, il exporte également des fichiers : certificats et clés.
Il convient également de noter qu'au lieu d'exporter/importer, vous pouvez utiliser [%Installer](https://community.intersystems.com/post/deploying-applications-intersystems-cache-installer) ou [Merge CPF](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=ACMF) pour créer la plupart de ces éléments. Ces deux outils prennent également en charge la création d'espaces de noms et de bases de données. Merge CPF peut ajuster les paramètres du système, tels que la taille du tampon global.
## Tâches
La classe [%SYS.Task](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=%25SYS.Task) stocke les tâches et fournit les méthodes `ExportTasks` et `ImportTasks`. Vous pouvez également consulter la classe utilitaire ci-dessus pour importer et exporter des tâches individuellement. Notez que lorsque vous importez des tâches, vous pouvez obtenir des erreurs d'importation (`ERROR #7432 : La date et l'heure de début doivent être postérieures à la date et à l'heure actuelles`) si `StartDate` ou d'autres propriétés liées à la planification sont dans le passé. Comme solution, réglez `LastSchedule` à `0`, et InterSystems IRIS replanifiera une tâche nouvellement importée pour qu'elle s'exécute dans le futur le plus proche.
## Interopérabilité
Les productions d'interopérabilité contiennent le suivant :
- Les partenaires commerciaux
- Les paramètres par défaut du système
- Les références
- Les tableaux de consultation (LUT)
Les deux premiers sont disponibles dans le paquet [Ens.Config](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=ENSLIB&PACKAGE=Ens.Config) avec les méthodes `%Export` et `%Import`. Exportez les références et les tableaux de consultation à l'aide de la [classe utilitaire](https://gist.github.com/eduard93/3a9abdb2eb150a456191bf387c1fc0c3) ci-dessus. Dans les versions récentes, les tableaux de consultation peuvent être exportés/importés via la classe [$system.OBJ](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.OBJ).
# Paramètres
[Paramètres par défaut du système](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=ECONFIG_other_default_settings#ECONFIG_other_default_settings_purpose) est un mécanisme d'interopérabilité par défaut pour les paramètres spécifiques à l'environnement :
> L'objectif des paramètres par défaut du système est de simplifier le processus de copiage d'une définition de production d'un environnement à l'autre. Dans toute production, les valeurs de certains paramètres sont déterminées dans le cadre de la conception de la production ; ces paramètres doivent généralement être identiques dans tous les environnements. D'autres paramètres, en revanche, doivent être adaptés à l'environnement ; il s'agit notamment des chemins d'accès aux fichiers, des numéros de port, etc.
>
> Les paramètres par défaut du système ne doivent spécifier que les valeurs spécifiques à l'environnement dans lequel InterSystems IRIS est installé. En revanche, la définition de la production doit spécifier les valeurs des paramètres qui doivent être identiques dans tous les environnements.
Je recommande fortement de les utiliser dans des environnements de production. Utilisez [%Export](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=ENSLIB&CLASSNAME=Ens.Config.DefaultSettings#%25Export) et [%Import](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=ENSLIB&CLASSNAME=Ens.Config.DefaultSettings#%25Import) pour transférer les paramètres par défaut du système.
## Paramètres de l'application
Votre application doit également utiliser des paramètres. Dans ce cas, je vous recommande d'utiliser les paramètres par défaut du système. Bien qu'il s'agisse d'un mécanisme d'interopérabilité, il est possible d'accéder aux paramètres via : `%GetSetting(pProductionName, pItemName, pHostClassName, pTargetType, pSettingName, Output pValue)` ([docs](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=ENSLIB&CLASSNAME=Ens.Config.DefaultSettings#%25GetSetting)). Vous pouvez écrire un wrapper qui définira les valeurs par défaut dont vous ne vous souciez pas, par exemple :
```objectscript
ClassMethod GetSetting(name, Output value) As %Boolean [Codemode=expression]
{
##class(Ens.Config.DefaultSettings).%GetSetting("myAppName", "default", "default", , name, .value)
}
```
Si vous voulez plus de catégories, vous pouvez aussi exposer les arguments `pItemName` et/ou `pHostClassName`. Les paramètres peuvent être initialement définis par importation, en utilisant le portail de gestion du système, en créant des objets de la classe `Ens.Config.DefaultSettings`, ou en définissant une globale `^Ens.Config.DefaultSettingsD`.
Mon premier conseil est de conserver les paramètres en un seul endroit (il peut s'agir des paramètres par défaut du système ou d'une solution personnalisée), et l'application doit obtenir les paramètres uniquement à l'aide d'une API fournie. De cette façon, l'application elle-même ne connaît pas l'environnement et il ne reste plus qu'à fournir un stockage centralisé des paramètres avec des valeurs spécifiques à l'environnement. Pour ce faire, créez un dossier de paramètres dans votre référentiel contenant des fichiers de paramètres, avec des noms de fichiers identiques aux noms des branches de l'environnement. Ensuite, pendant la phase CI/CD, utilisez la [variable d'environnement `$CI_COMMIT_BRANCH`](https://docs.gitlab.com/ee/ci/variables/predefined_variables.html) pour charger le fichier approprié.
```
DEV.xml
TEST.xml
PROD.xml
```
Si vous avez plusieurs fichiers de configuration par environnement, utilisez des dossiers nommés d'après les branches de l'environnement. Pour obtenir la valeur d'une variable d'environnement à l'intérieur d'InterSystems IRIS [utilisez](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.Util#GetEnviron) `$System.Util.GetEnviron("name")`.
# Données
Si vous souhaitez mettre à disposition certaines données ( tableaux de référence, catalogues, etc.), vous disposez de plusieurs moyens pour le faire :
- Exportation globale. Utilisez soit un fichier binaire [GOF export](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GGBL_managing#GGBL_managing_export), soit un nouvel fichier XML. Avec le fichier GOF export, rappelez-vous que les locales sur les systèmes source et cible doivent correspondre (ou au moins la collation globale doit être disponible sur le système cible). Le fichier [XML export](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.OBJ) prend plus de place. Vous pouvez l'améliorer en exportant les globales dans un fichier `xml.gz`, les méthodes `$system.OBJ` (dés)archivent automatiquement les fichiers `xml.gz` selon les besoins. Le principal inconvénient de cette approche est que les données ne sont pas lisibles par l'homme, même XML - la plupart d'entre elles sont encodées en base64.
- Format CSV. [Export CSV](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=%25SQL.StatementResult#%25DisplayFormatted) et l'importer avec [LOAD DATA](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=RSQL_loaddata). Je préfère CSV car c'est le format lisible par l'homme le plus efficace en termes de stockage, et que tout le monde peut importer.
- Format JSON. Créez la classe [JSON Enabled](https://docs.intersystems.com/iris20221/csp/docbook/DocBook.UI.Page.cls?KEY=GJSON_adaptor).
- Format XML. Créez la classe [XML Enabled](https://docs.intersystems.com/iris20221/csp/docbook/DocBook.UI.Page.cls?KEY=GXMLPROJ_intro) pour projeter des objets en XML. Utilisez-la si vos données ont une structure complexe.
Le choix du format dépend de votre cas d'utilisation. Ici, j'ai classé les formats par ordre d'efficacité de stockage, mais ce n'est pas un souci si vous n'avez pas beaucoup de données.
# Conclusions
L'état ajoute une complexité supplémentaire à vos pipelines de déploiement CI/CD, mais InterSystems IRIS fournit une vaste gamme d'outils pour le gérer.
# Liens
- [Utility Class](https://gist.github.com/eduard93/3a9abdb2eb150a456191bf387c1fc0c3)
- [%Installer](https://community.intersystems.com/post/deploying-applications-intersystems-cache-installer)
- [Merge CPF](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=ACMF)
- [$System.OBJ](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.OBJ)
- [Paramètres par défaut du système](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=ENSLIB&CLASSNAME=Ens.Config.DefaultSettings#%25GetSetting)
Article
Iryna Mykhailova · Mai 10, 2023
De nombreux facteurs influencent la qualité de vie des gens, et l'un des plus importants est le sommeil. La qualité de notre sommeil détermine notre capacité à fonctionner pendant la journée et affecte notre santé mentale et physique. Un sommeil de bonne qualité est essentiel à notre santé et à notre bien-être général. Par conséquent, en analysant les indicateurs précédant le sommeil, nous pouvons déterminer la qualité de notre sommeil. C'est précisément la fonctionnalité de l'application Sheep's Galaxy.
Sheep's Galaxy est un exemple d'application qui fonctionne avec les technologies IntegratedML et IRIS Cloud SQL d'InterSystems et qui fournit à l'utilisateur un outil d'analyse et d'amélioration de la qualité du sommeil. L'analyse du sommeil prend en compte des facteurs tels que les niveaux de bruit, l'éclairage de la pièce, la durée du sommeil, la consommation de caféine, etc., ce qui permet à l'utilisateur de reconsidérer ses habitudes en matière de sommeil et de créer des conditions optimales pour le sommeil à l'avenir.
**Présentation vidéo :**
[https://www.youtube.com/watch?v=eZ9Wak831x4&ab_channel=MariaGladkova](https://www.youtube.com/watch?v=eZ9Wak831x4&ab_channel=MariaGladkova)
**L'application est basée sur les technologies suivantes :**
* [Angular](https://angular.io/) structure pour le frontend;
* [FastApi](https://fastapi.tiangolo.com/) structure avec un package DB-API pour le backend ;
* [IRIS Cloud SQL with IntegratedML](https://portal.sql-contest.isccloud.io) pour analyser et stocker des données.
**Partie Frontend :**
Pour construire cette application, nous avons utilisé la structure Angular. Il nous a aidé à créer une application simple à page unique. Nous avons utilisé Angular v15, et tous les composants Angular ont été implémentés en tant que standalones pour rationaliser l'expérience de création. Nous n'avons pas utilisé de modules Angular et c'est une bonne pratique pour faire évoluer une application dans le futur si nécessaire.
Nous avons également utilisé l'architecture des composants intelligents (Smart Component Architecture) - tous les composants de notre application frontale sont divisés en composants "intelligents" et "muets". Ce concept nous aide à séparer le code de logique métier et le code de présentation entre ces composants.
Toute la Logique métier et les demandes adressées au serveur sont conservées dans les services isolés. Pour traiter les données de notre backend, nous utilisons RxJS - une bibliothèque pour composer des programmes asynchrones et basés sur des événements en utilisant des séquences observables.
Pour styliser notre application, nous avons utilisé Angular Material - il s'agit d'une bibliothèque de composants d'interface utilisateur que les développeurs peuvent utiliser dans leurs projets Angular pour accélérer le développement d'interfaces utilisateur élégantes et cohérentes. Cette bibliothèque offre un grand nombre de composants d'interface utilisateur réutilisables et magnifiques - nous en avons ajouté quelques-uns comme les cartes, les entrées, les tableaux de données, les sélecteurs de date, et bien d'autres encore.
Nous présentons ci-dessous une vue d'ensemble du flux de travail typique d'un utilisateur. Tout d'abord, l'utilisateur passe par le processus d'enregistrement, s'il l'utilise pour la première fois, ou par l'écran d'autorisation.
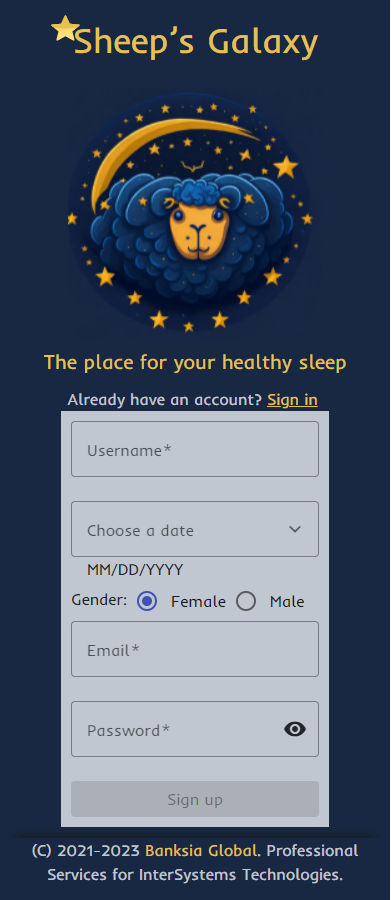
À l'aide de cette application, l'utilisateur entre des renseignements sur son sommeil, tels que son niveau d'activité pendant la journée, le nombre de tasses de café, son confort de sommeil, son niveau de stress et la quantité d'émotions positives, ainsi que la lumière de la pièce et l'heure du coucher.
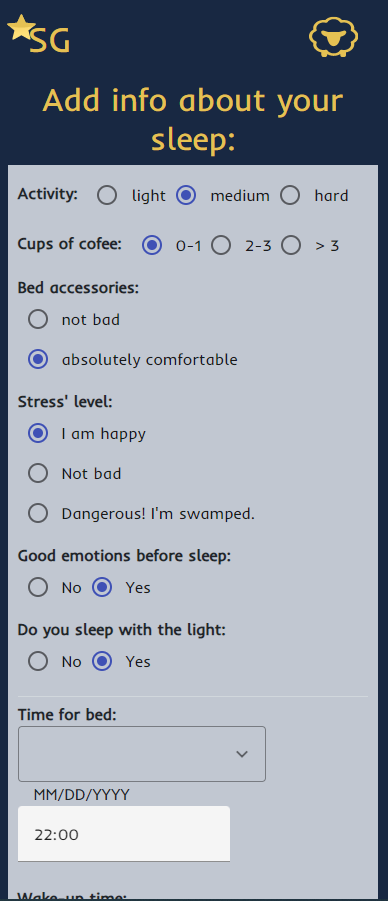
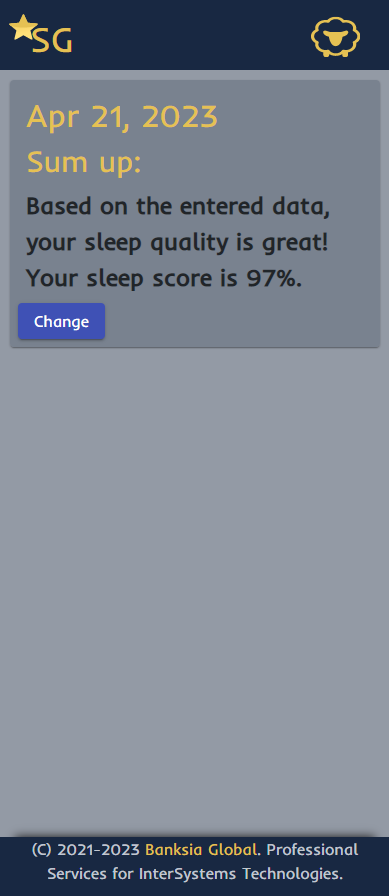
Après chaque saisie de données, l'utilisateur reçoit une notification sur la qualité de son sommeil. Ces données sont ensuite analysées à l'aide d'algorithmes d'apprentissage automatique afin de fournir aux utilisateurs des informations sur leurs habitudes de sommeil.
**Partie Backend :**
Fastapi est un framework python basé sur deux technologies : Pydantic et Starlette.
Il a les fonctionnalités suivantes :
* Il est basé sur des standards ouverts : OpenAPI, schéma JSON, OAuth2 ;
* Documentation automatique de l'API en swagger ;
* Implémentation des dépendances ;
* Il utilise les fonctionnalités de python moderne : annotation de type, asyncio ;
* Il supporte le code synchrone et asynchrone ;
La structure du projet consiste en des routeurs avec des points d'extrémité, des modèles pour chaque entité et des services de traitement.
Chaque point d'extrémité apparaît dans la documentation atomique à /docs et les champs des points d'extrémité ont une relation avec les modèles de données dans la base de données.
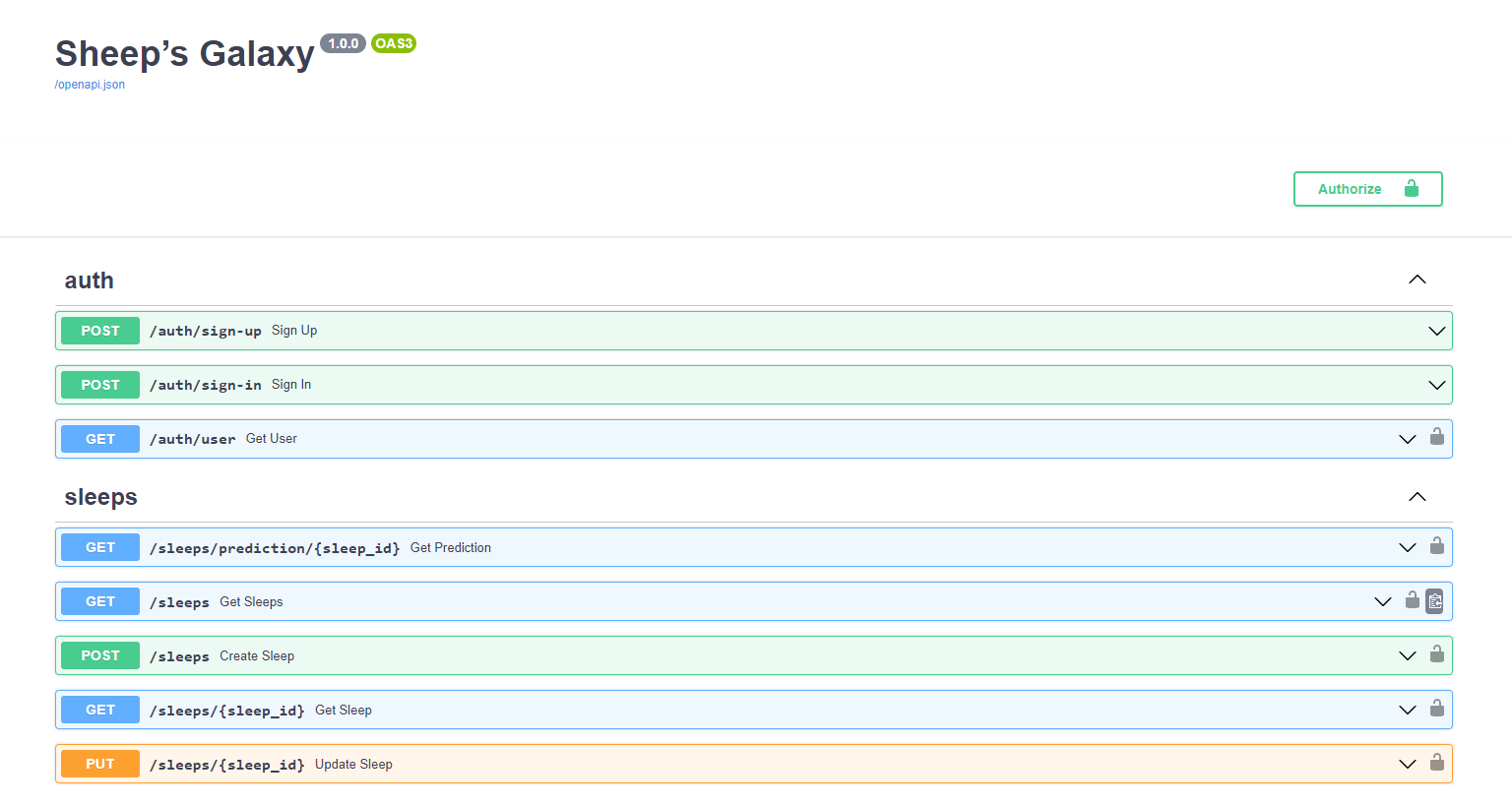
Les modèles pydantiques valident automatiquement les données entrantes et sortantes.
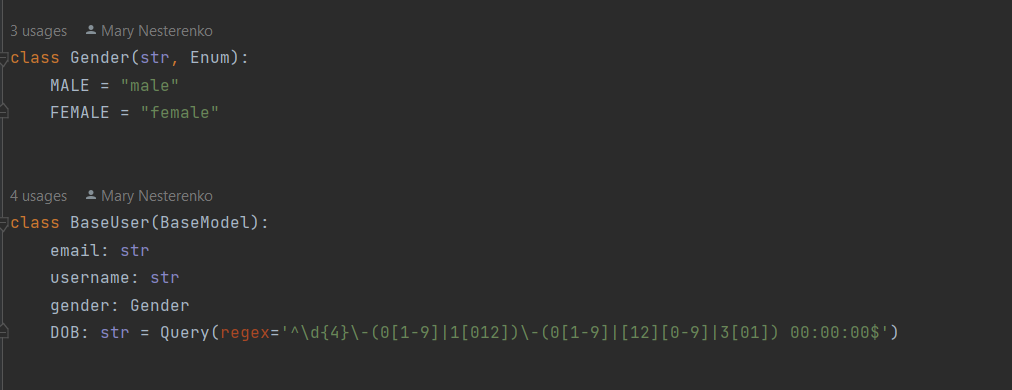
Le processus de traitement des données des utilisateurs repose sur le protocole, qui vous permet de traiter les données en toute sécurité.
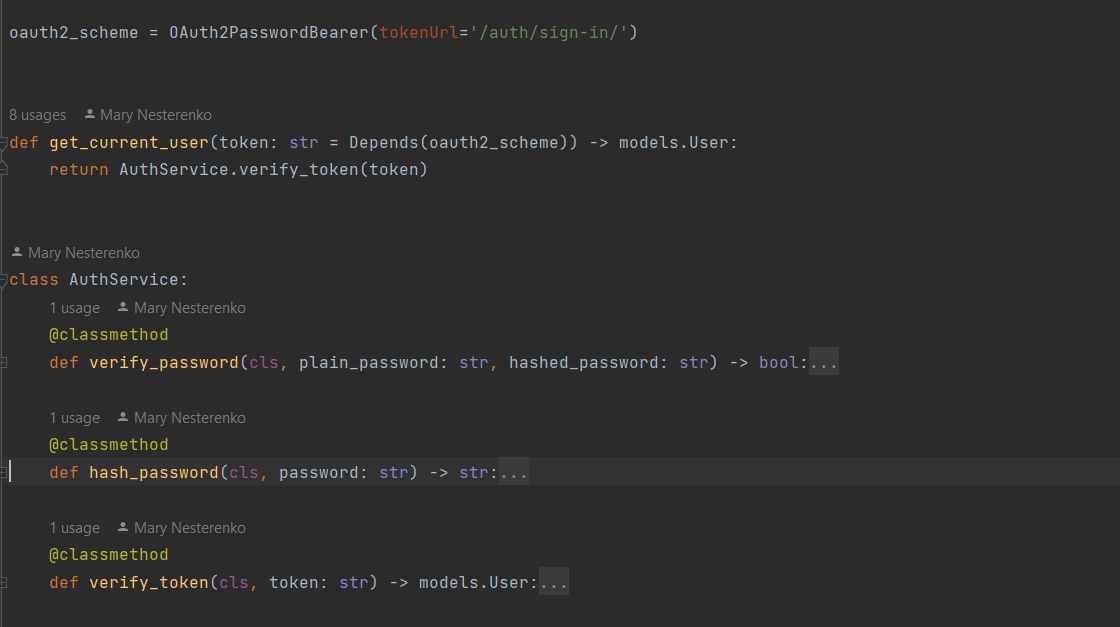
Le processus d'interaction avec la base de données est mis en œuvre par la connexion SQL d'IRIS à l'aide de [DB API](https://raw.githubusercontent.com/intersystems-community/iris-driver-distribution/main/DB-API/intersystems_irispython-3.2.0-py3-none-any.whl).
**IRIS Cloud SQL avec IntegratedML :**
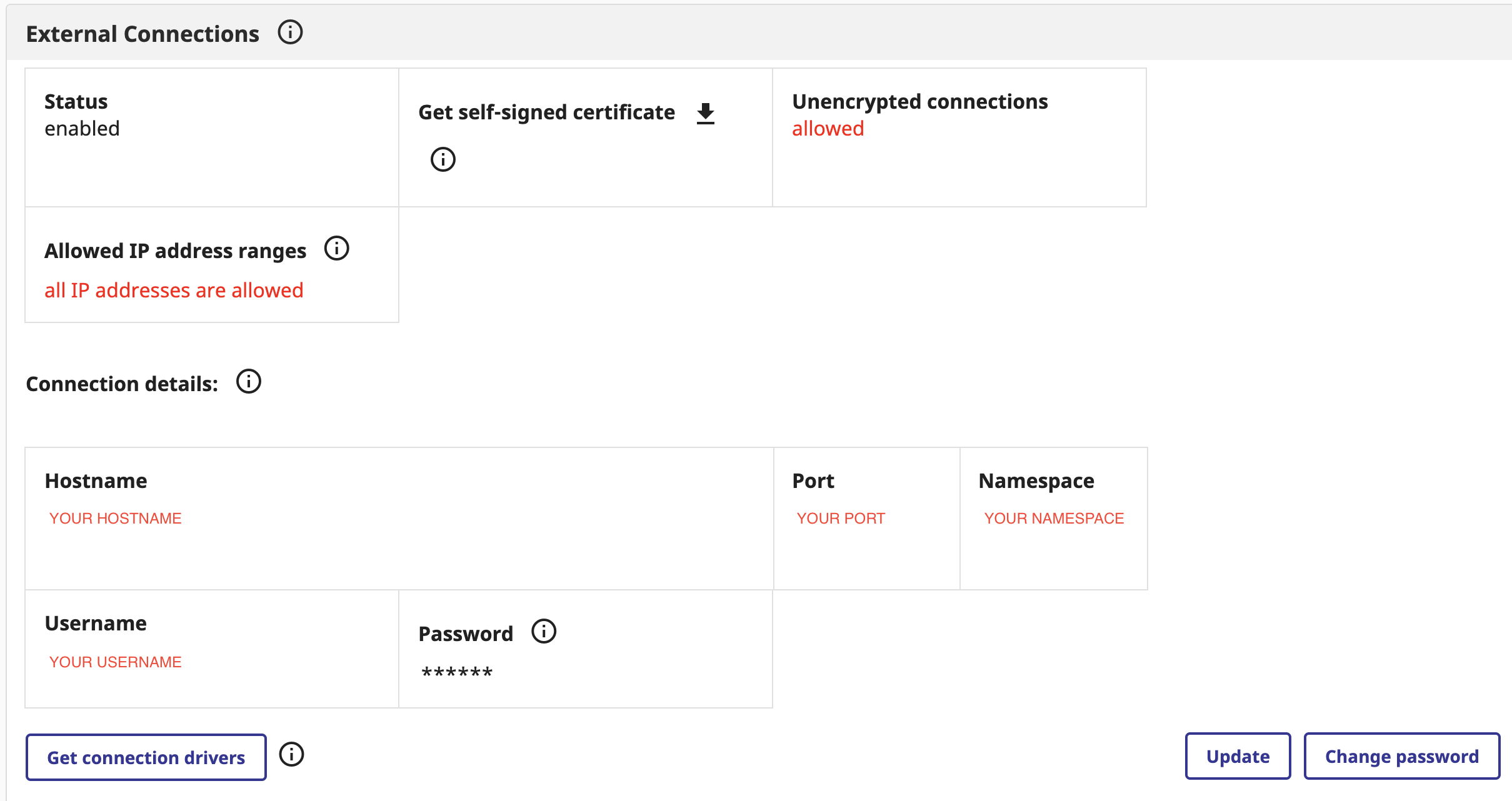
Tout d'abord, vous devez vous connecter au portail InterSystems Cloud Services. Vous devez ensuite créer un nouveau déploiement IRIS Cloud SQL. Veillez à inclure IntegratedML lorsque vous créez un nouveau déploiement. Lorsqu'il est prêt, vous pouvez obtenir les paramètres de connexion à utiliser dans docker-compose.yml :
En ouvrant le menu "IntegratedML Tools", vous avez accès à la création, à l'entraînement et à la validation de votre modèle, ainsi qu'à la possibilité de générer des prédictions sur un champ sélectionné dans le tableau de votre modèle.
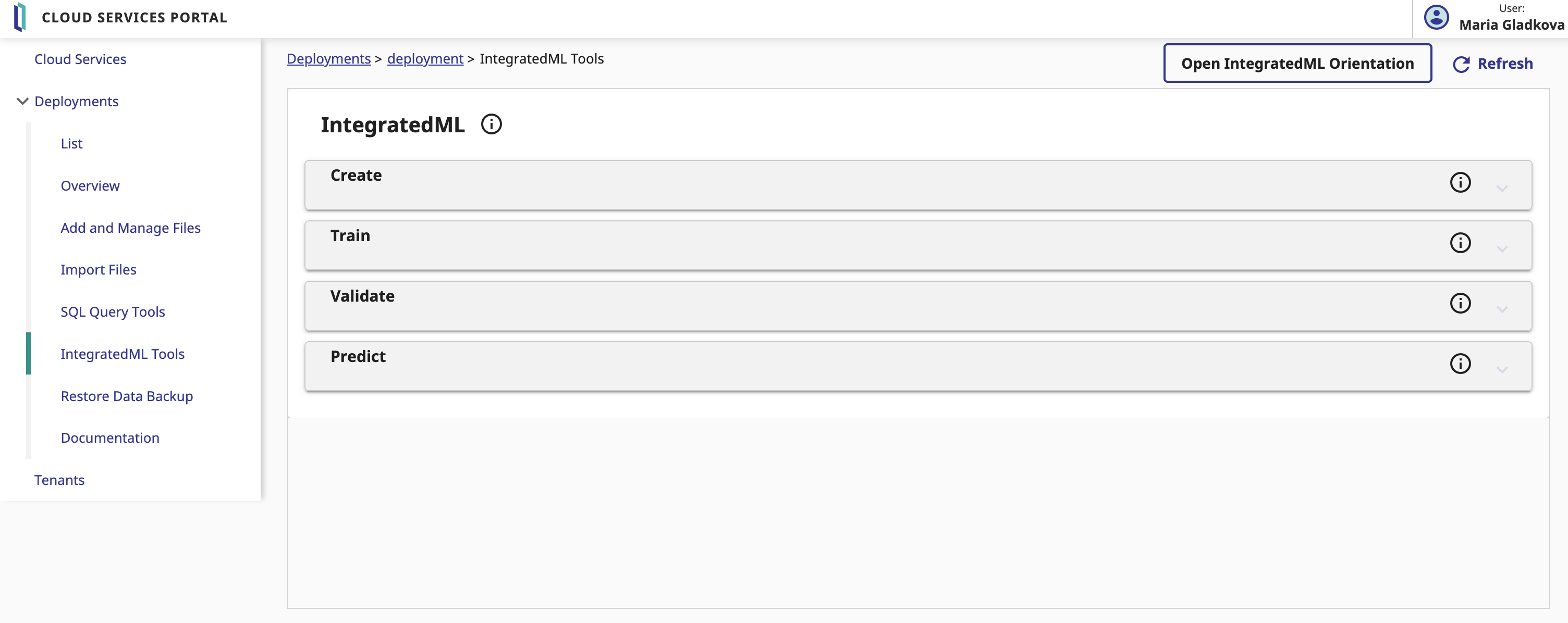
Dans notre application, nous prédisons la qualité du sommeil sur la base des données de l'utilisateur. Pour ce faire, nous remplissons les champs de la section Prédiction comme suit :
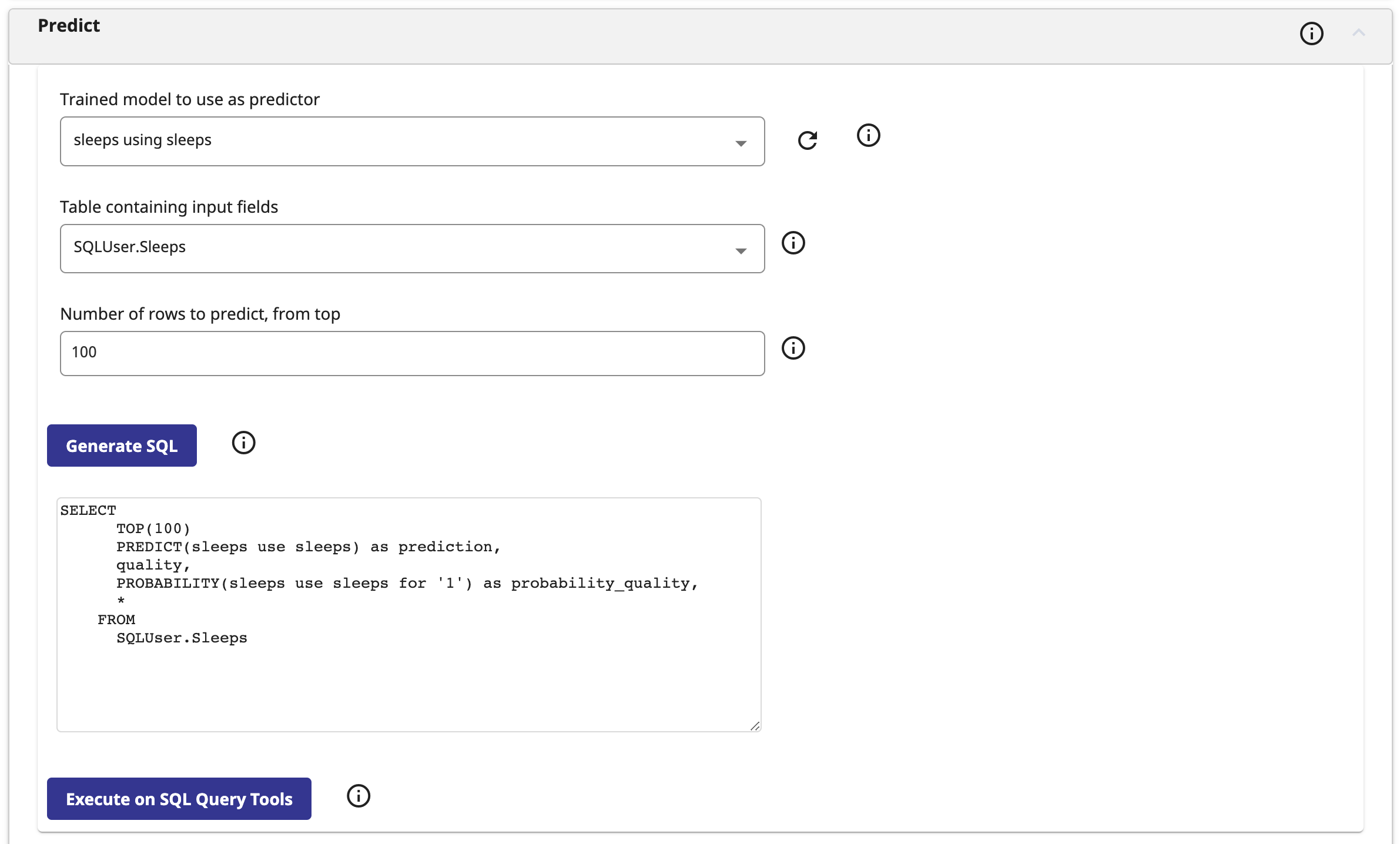
Dans la requête générée, le champ prediction contient une prédiction de la qualité du sommeil, le champ probability_quality (probabilité de qualité) contient la probabilité que le sommeil soit " de bonne qualité ".
**Liens :**
Pour en savoir plus sur notre projet ou l'utiliser comme modèle pour vos futurs travaux :
https://openexchange.intersystems.com/package/Sheep%E2%80%99s-Galaxy
**Remerciements :**
Notre équipe tient à remercier InterSystems et Banksia Global de nous avoir donné l'occasion de travailler avec une technologie de pointe sur des questions importantes.
**Développeurs du projet :**
* [Maria Gladkova](https://community.intersystems.com/user/maria-gladkova)
* [Katsiaryna Shaustruk](https://community.intersystems.com/user/katsiaryna-shaustruk)
* [Maria Nesterenko](https://community.intersystems.com/user/maria-nesterenko)
Annonce
Adeline Icard · Juin 13, 2023
InterSystems annonce la fin de la maintenance de Zen Reports à partir d'Intersystems IRIS et IRIS for Health 2025.1. Cela fait suite à l'avis de dépréciation émis lors de l'introduction d'InterSystems IRIS en 2018 et à l'inclusion ultérieure d'InterSystems Reports en 2020 pour fournir une fonctionnalité de rapport de remplacement. Un aperçu de la chronologie est:
Mars 2018. InterSystems IRIS 2018.1 : Annonce de l'abandon de Zen Reports, livraison continue pour assurer la continuité des applications existantes
Avril 2020. InterSystems IRIS 2020.1 : Rapports Intersystems intégrés dans le cadre des licences InterSystems IRIS et IRIS for Health and Advanced Server basées sur l'utilisateur
Mai 2023. Notification de fin de maintenance pour Zen Reports
2P 2024. Zen Reports disponible en tant que module ipm
1P 2025 (InterSystems IRIS 2025.1) Package Zen Reports supprimé des distributions InterSystems IRIS et IRIS for Health
InterSystems a introduit InterSystems Reports, optimisé par Logi Reports de insightsoftware (anciennement Logi Analytics) en tant que solution de création de rapports intégrée commençant par InterSystems IRIS et IRIS for Health 2020.1. InterSystems Reports fournit une solution de reporting moderne par glisser-déposer pour les clients et partenaires InterSystems.
Nous prévoyons de faire la transition de Zen Reports vers un package indépendant utilisant IPM (InterSystems Package Manager) et de cesser d'expédier Zen Reports avec InterSystems IRIS et IRIS for Health version 2025.1. Zen Reports continuera d'être disponible en tant que module ipm et pourra être distribué mais ne sera pas maintenu par InterSystems. Le WRC continuera à fournir une assistance sur les versions antérieures de Cache et d'IRIS qui contiennent Zen Reports, mais aucune mise à jour n'est prévue pour le logiciel Zen Reports.
Pour plus d'informations sur la mise en route d'InterSystems Reports :
Parcours d'apprentissage InterSystems
Documentation InterSystems
Session du sommet mondial : passage d'InterSystems Application Services de Zen Reports à InterSystems Reports
Documentation et didacticiel Logi Report d'insightsoftware
Veuillez commenter ci-dessous ou contacter dbpprodmgrs@intersystems.com pour toute question concernant cette annonce.
11 Publications•0 Abonnés
Article
Sylvain Guilbaud · Avr 19, 2022
Kong fournit en open source un outil de gestion de ses configurations (écrit en Go), appelé decK (pour declarative Kong)
Vérifiez que decK reconnaît votre installation Kong Gateway via deck ping
deck ping
Successfully connected to Kong!
Kong version: 2.3.3.2-enterprise-edition
Exporter la configuration de Kong Gateway dans un fichier "kong.yaml" via deck dump
deck dump
Après avoir modifié le kong.yaml, afficher les différences via deck diff
deck diff
updating service alerts {
"connect_timeout": 60000,
- "host": "172.24.156.176",
+ "host": "192.10.10.18",
"id": "3bdd7db4-0b75-4148-93b3-2ff11e961f64",
"name": "alerts",
"path": "/alerts",
"port": 50200,
"protocol": "http",
"read_timeout": 60000,
"retries": 5,
"write_timeout": 60000
}
Summary:
Created: 0
Updated: 1
Deleted: 0
Appliquez les modifications via deck sync
deck sync
updating service alerts {
"connect_timeout": 60000,
- "host": "172.24.156.176",
+ "host": "192.10.10.18",
"id": "3bdd7db4-0b75-4148-93b3-2ff11e961f64",
"name": "alerts",
"path": "/alerts",
"port": 50200,
"protocol": "http",
"read_timeout": 60000,
"retries": 5,
"write_timeout": 60000
}
Summary:
Created: 0
Updated: 1
Deleted: 0
deck sync -s workspace1.yaml --workspace workspace1
deck sync -s workspace2.yaml --workspace workspace2
Pour plus d'informations :
https://docs.konghq.com/deck/1.11.x/guides/getting-started/
https://docs.konghq.com/deck/1.11.x/guides/best-practices/
Annonce
Irène Mykhailova · Juil 24, 2022
Salut la communauté !
Nous sommes fiers d'annoncer qu'InterSystems accueillera le Women's Health - FemTech: Much More than A Niche Market au siège a Cambridge !
⏱ Heure : 28 juillet, de 17h30 à 19h30 EDT📍 Lieu : InterSystems Corporation 1 Memorial Drive, Cambridge, MA
Cet événement est organisé par HealthTech Build dont la mission est de créer des opportunités pour les prestataires médicaux, les innovateurs numériques biotechnologiques, les scientifiques des données de santé, les développeurs de thérapies numériques et les ingénieurs logiciels de travailler vers des objectifs communs de manière perturbatrice et productive. Pour cet événement, l'objectif sera d'échanger des idées et de répondre aux besoins de santé des femmes non satisfaits de manière nouvelle.
Le point culminant de l'événement sera un panel en personne HealthTech Build avec :
Janine Kopp, Investor & Head of Venture Studio, Takeda Digital Ventures
Uros Kuzmanovic, CEO, Biosens8
Mary Beth Cicero, CEO, 3Daughters
Thom Busby, Senior Vice President, Outcome Capital
Ne manquez pas cette excellente occasion de découvrir des défis et de discuter de nouvelles solutions dans une grande entreprise de pairs partageant les mêmes idées. Des boissons et des hors-d'œuvres seront servies.
>> INSCRIVEZ-VOUS ICI <<
Annonce
Irène Mykhailova · Oct 21, 2022
Salut la communauté,
Rencontrons-nous virtuellement lors de notre deuxième table ronde communautaire !Il s'agira d'une discussion amicale de 45 minutes sur un sujet donné : Quel est le meilleur système de contrôle de code source pour le développement avec InterSystems IRIS.
>> Inscrivez-vous ici <<
Intervenant : @Evgeny.Shvarov Co-intervenants : @Dmitry.Maslennikov and @Timothy.Leavitt
📅 Date : 27 octobre🕑 Heure : 9h00 ET | 15h00 CES
Avez-vous des questions spécifiques sur le sujet dont vous souhaitez discuter lors de la table ronde ? Partagez-les dans les commentaires!
17 Publications•0 Abonnés