Premiers pas sur InterSystems Data Studio
Le tutoriel récemment publié « Introduction à InterSystems Data Studio » m’a donné envie de découvrir ce produit. Et je trouve que c’est une approche intéressante pour la gestion d’un data fabric, sans avoir à plonger dans du code complexe. Il permet de connecter des silos de données hétérogènes, de transformer les données via des pipelines automatisés, puis de les charger dans un environnement unifié pour l’analyse.
J’ai donc décidé d’écrire un exemple montrant comment l’utiliser. En pratique, je vais parcourir le tutoriel avec vous au cas où vous n’auriez pas le temps de le faire vous-même. Même si je recommande fortement de suivre directement le tutoriel, car il contient beaucoup d’informations utiles.
Pour comprendre son fonctionnement, je me suis mis dans la peau d’un administrateur système, en me connectant avec les identifiants fournis afin d’explorer l’interface. L’organisation de l’outil repose sur quelques piliers essentiels : définir les sources de données, cataloguer leur structure et construire des « recettes » automatisées pour les transférer vers un environnement de production.
Et la toute première étape consiste à établir une connexion avec mes données.
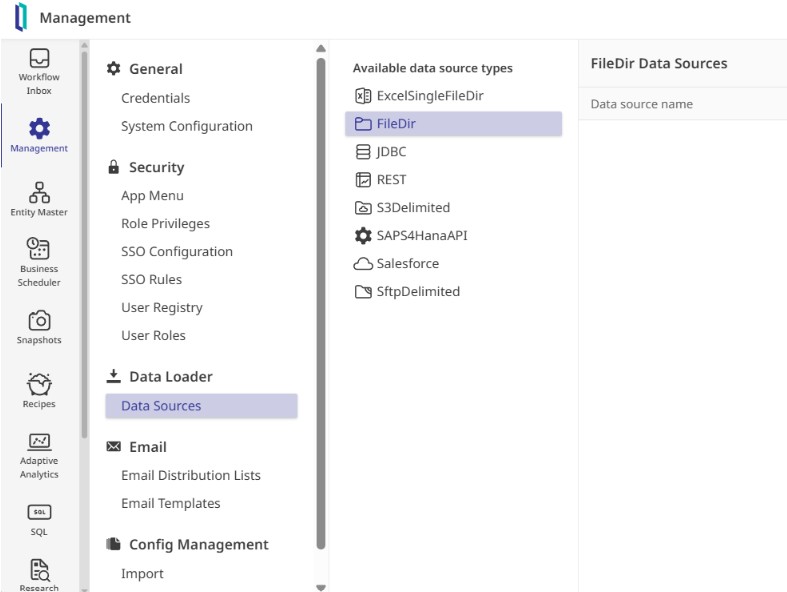
Bien qu’IDS prenne en charge aussi bien des buckets cloud que des API, nous commençons ici avec une simple source de type répertoire de fichiers appelée TestFileDir. Une fois enregistrée, le système génère automatiquement une structure de dossiers permettant de gérer le cycle de vie des fichiers, avec des espaces dédiés aux exemples, au traitement actif et à l’archivage.
Dans le dossier Samples, un petit fichier CSV contenant des données de transactions est utilisé pour alimenter le Data Schema Importer. Cet outil analyse le fichier et mappe automatiquement les noms de colonnes ainsi que les types de données, ce qui permet de publier un schéma formel sans saisie manuelle.
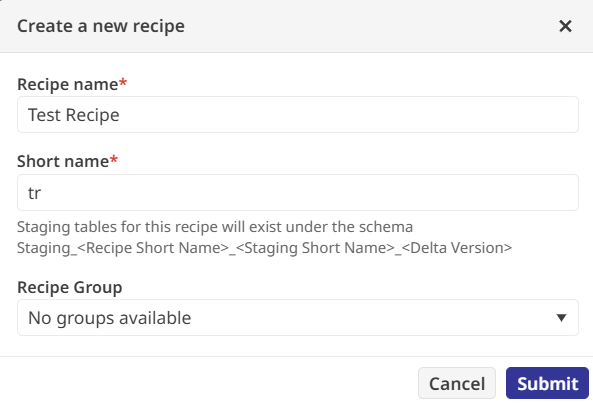
Maintenant qu’il y a des données, il devient possible de faire quelque chose avec elles. Et cela se fait via une « recette ».
Plusieurs types d’activités peuvent être exécutés dans une recette :
- Les activités de staging extraient les données depuis les sources vers une zone intermédiaire
- Les activités de transformation modifient les champs de données selon la logique métier
- Les activités de validation vérifient l’intégrité des données à l’aide de règles prédéfinies
- Les activités de réconciliation comparent les données provenant de différentes sources afin d’assurer leur cohérence
- Les activités de promotion déplacent les données traitées vers des tables ou fichiers finaux destinés à l’exploitation
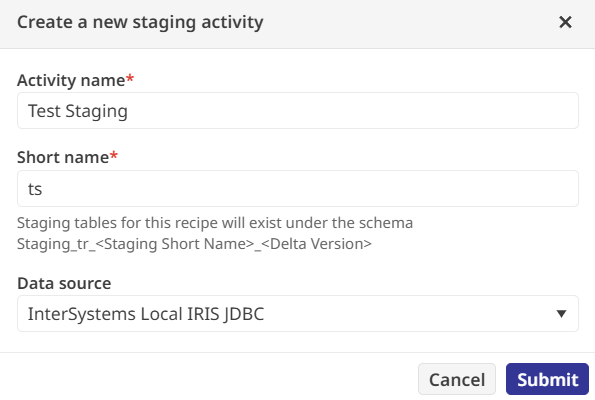
Dans le tutoriel, nous prenons les données du fichier CSV d’exemple et transformons certains champs. Cela implique tout d’abord une étape de staging des données brutes afin de les préparer à l’utilisation.
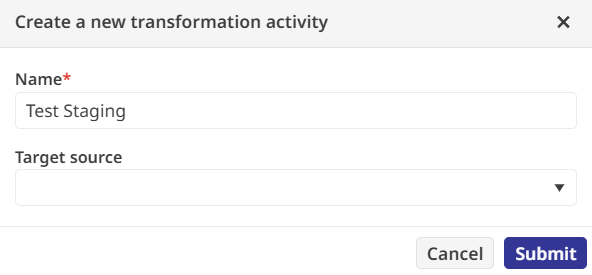
Ensuite vient la phase de transformation selon notre logique métier : la première règle consiste à standardiser les identifiants produits en chaînes majuscules, tandis que la seconde arrondit les prix de vente à une décimale, en créant un nouveau champ appelé RoundedSalePrice.
Afin d’éviter toute donnée invalide, une activité de validation est ajoutée. Une expression régulière vérifie que chaque identifiant produit correspond exactement à une lettre majuscule. En définissant l’échec de cette règle comme « Fatal », le pipeline s’arrêtera immédiatement en cas d’anomalie.
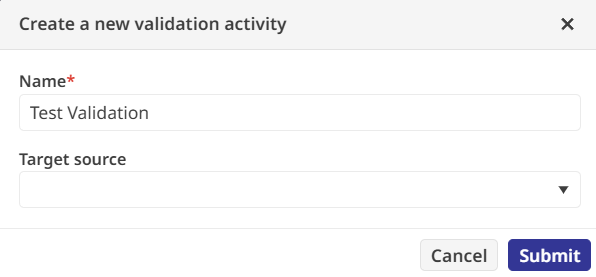
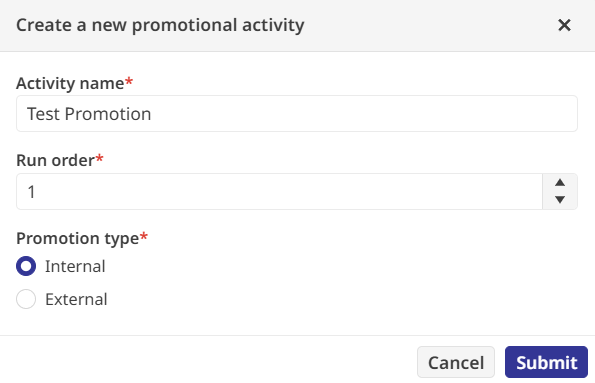
La dernière étape de la recette est l’activité de promotion, qui déplace les données validées vers leur emplacement définitif. J’ai ciblé une table interne appelée Sample.Transactions et rédigé une expression SQL afin de mapper les champs transformés vers les colonnes de production.
Après vérification de la requête SQL pour détecter d’éventuelles erreurs, la recette était prête à être exécutée en conditions réelles.
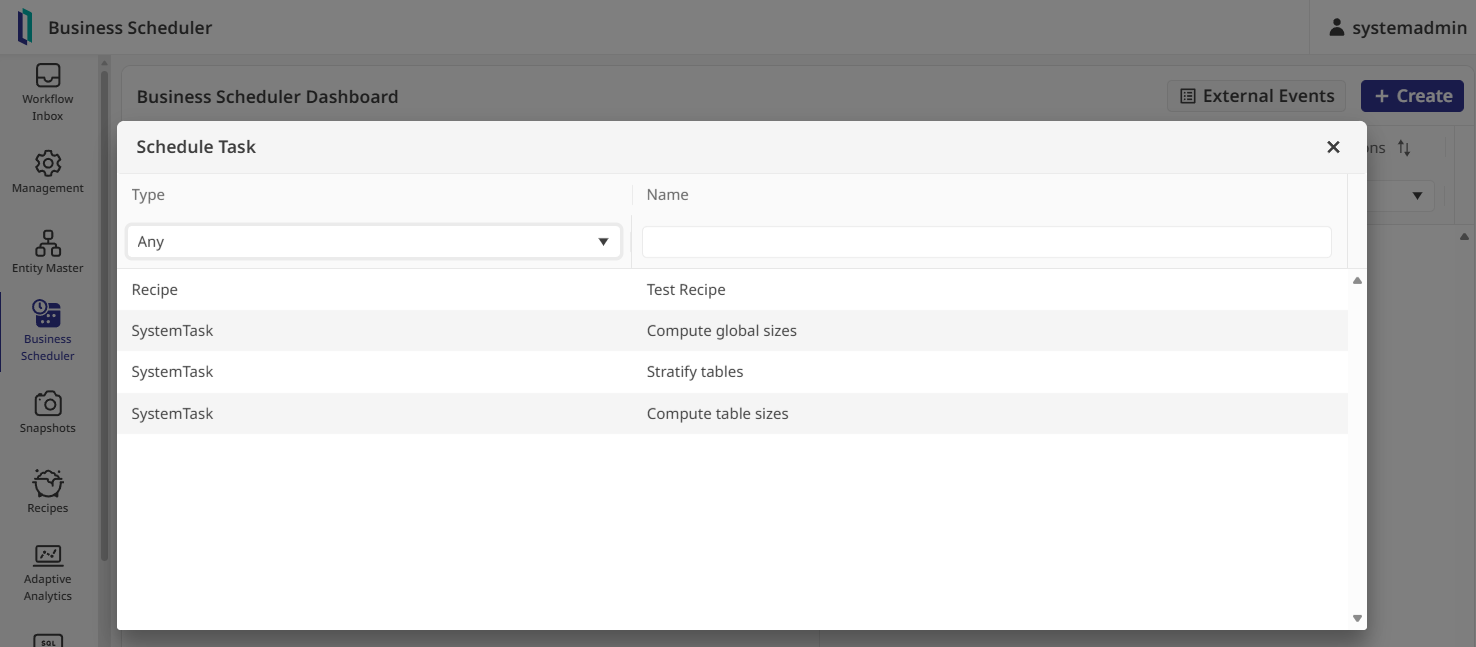
Pour exécuter le pipeline, il faut ouvrir le Business Scheduler. Avant qu’une tâche puisse être lancée, elle a besoin d’une « Entity » fournissant du contexte, notamment les fuseaux horaires. J’ai donc activé l’entité existante « US » dans l’Entity Master.
De retour dans le scheduler, j’ai créé une tâche associée à ma recette :
Je l’ai ensuite assignée au rôle System Administrator pour la gestion des exceptions, puis configurée pour une exécution manuelle.
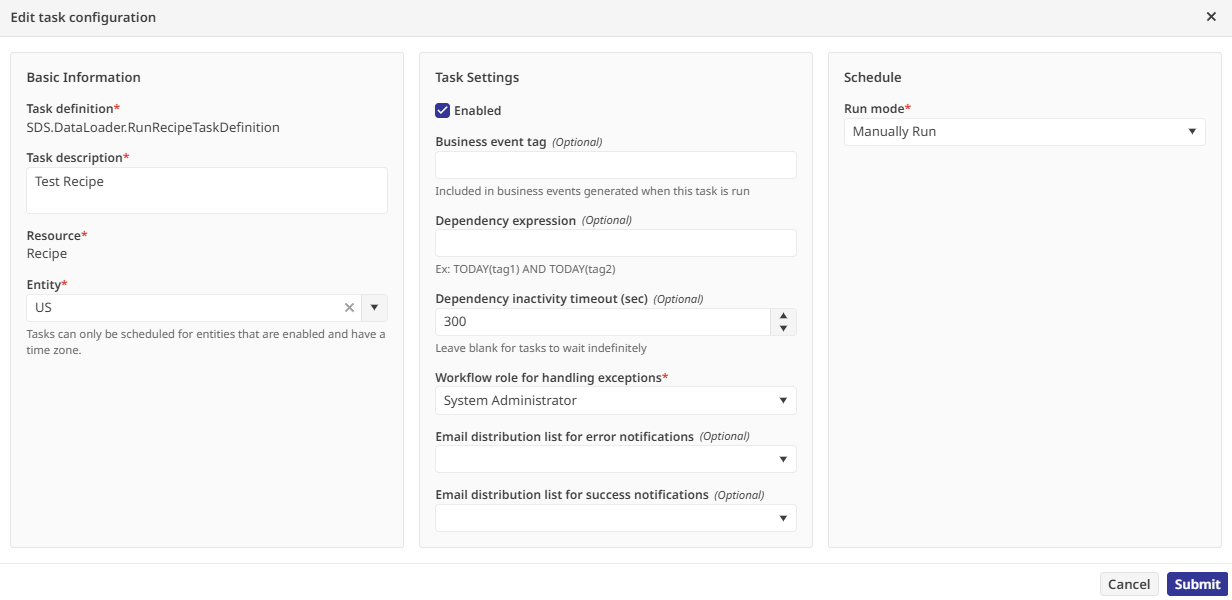
En cliquant sur « Manually Run Now », le système a commencé le traitement : récupération des données CSV, exécution des transformations et validation selon les règles définies.
Une fois la tâche terminée, l’historique d’exécution a fourni un rapport détaillé montrant que tous les enregistrements avaient été traités sans la moindre erreur de validation.
Pour vérifier le résultat moi-même, j’ai ouvert l’explorateur SQL interne et exécuté une requête sur la table Sample.Transactions. Les données brutes étaient bien là, nettoyées, validées et prêtes pour une utilisation en production.
Il s’agit d’une approche scalable du traitement de données qui reste simple même lorsque la logique métier devient plus complexe.
Si vous souhaitez parcourir vous-même tout ce processus dans un environnement de laboratoire interactif (ce que je recommande fortement), vous pouvez accéder au tutoriel ici : « Introduction à InterSystems Data Studio ».